Graph.control_dependencies() using the default graph.',!1,`Wrapper for \`Graph.control_dependencies()\` using the default graph.
+
+ See \`tf.Graph.control_dependencies\` for more details.
+
+ Note: *In TensorFlow 2 with eager and/or Autograph, you should not require
+ this method, as ops execute in the expected order thanks to automatic control
+ dependencies.* Only use \`tf.control_dependencies\` when working with v1
+ \`tf.Graph\` code.
+
+ When eager execution is enabled, any callable object in the \`control_inputs\`
+ list will be called.
+
+ Args:
+ control_inputs: A list of \`Operation\` or \`Tensor\` objects which must be
+ executed or computed before running the operations defined in the context.
+ Can also be \`None\` to clear the control dependencies. If eager execution
+ is enabled, any callable object in the \`control_inputs\` list will be
+ called.
+
+ Returns:
+ A context manager that specifies control dependencies for all
+ operations constructed within the context.
+ `],["tf.convert_to_tensor","description: Converts the given value to a Tensor.",!1,`Converts the given \`value\` to a \`Tensor\`.
+
+ This function converts Python objects of various types to \`Tensor\`
+ objects. It accepts \`Tensor\` objects, numpy arrays, Python lists,
+ and Python scalars.
+
+ For example:
+
+ >>> import numpy as np
+ >>> def my_func(arg):
+ ... arg = tf.convert_to_tensor(arg, dtype=tf.float32)
+ ... return arg
+
+ >>> # The following calls are equivalent.
+ ...
+ >>> value_1 = my_func(tf.constant([[1.0, 2.0], [3.0, 4.0]]))
+ >>> print(value_1)
+ tf.Tensor(
+ [[1. 2.]
+ [3. 4.]], shape=(2, 2), dtype=float32)
+ >>> value_2 = my_func([[1.0, 2.0], [3.0, 4.0]])
+ >>> print(value_2)
+ tf.Tensor(
+ [[1. 2.]
+ [3. 4.]], shape=(2, 2), dtype=float32)
+ >>> value_3 = my_func(np.array([[1.0, 2.0], [3.0, 4.0]], dtype=np.float32))
+ >>> print(value_3)
+ tf.Tensor(
+ [[1. 2.]
+ [3. 4.]], shape=(2, 2), dtype=float32)
+
+ This function can be useful when composing a new operation in Python
+ (such as \`my_func\` in the example above). All standard Python op
+ constructors apply this function to each of their Tensor-valued
+ inputs, which allows those ops to accept numpy arrays, Python lists,
+ and scalars in addition to \`Tensor\` objects.
+
+ Note: This function diverges from default Numpy behavior for \`float\` and
+ \`string\` types when \`None\` is present in a Python list or scalar. Rather
+ than silently converting \`None\` values, an error will be thrown.
+
+ Args:
+ value: An object whose type has a registered \`Tensor\` conversion function.
+ dtype: Optional element type for the returned tensor. If missing, the type
+ is inferred from the type of \`value\`.
+ dtype_hint: Optional element type for the returned tensor, used when dtype
+ is None. In some cases, a caller may not have a dtype in mind when
+ converting to a tensor, so dtype_hint can be used as a soft preference.
+ If the conversion to \`dtype_hint\` is not possible, this argument has no
+ effect.
+ name: Optional name to use if a new \`Tensor\` is created.
+
+ Returns:
+ A \`Tensor\` based on \`value\`.
+
+ Raises:
+ TypeError: If no conversion function is registered for \`value\` to \`dtype\`.
+ RuntimeError: If a registered conversion function returns an invalid value.
+ ValueError: If the \`value\` is a tensor not of given \`dtype\` in graph mode.
+ `],["tf.CriticalSection","description: Critical section.",!1,`Critical section.
+
+ A \`CriticalSection\` object is a resource in the graph which executes subgraphs
+ in **serial** order. A common example of a subgraph one may wish to run
+ exclusively is the one given by the following function:
+
+ \`\`\`python
+ v = resource_variable_ops.ResourceVariable(0.0, name="v")
+
+ def count():
+ value = v.read_value()
+ with tf.control_dependencies([value]):
+ with tf.control_dependencies([v.assign_add(1)]):
+ return tf.identity(value)
+ \`\`\`
+
+ Here, a snapshot of \`v\` is captured in \`value\`; and then \`v\` is updated.
+ The snapshot value is returned.
+
+ If multiple workers or threads all execute \`count\` in parallel, there is no
+ guarantee that access to the variable \`v\` is atomic at any point within
+ any thread's calculation of \`count\`. In fact, even implementing an atomic
+ counter that guarantees that the user will see each value \`0, 1, ...,\` is
+ currently impossible.
+
+ The solution is to ensure any access to the underlying resource \`v\` is
+ only processed through a critical section:
+
+ \`\`\`python
+ cs = CriticalSection()
+ f1 = cs.execute(count)
+ f2 = cs.execute(count)
+ output = f1 + f2
+ session.run(output)
+ \`\`\`
+ The functions \`f1\` and \`f2\` will be executed serially, and updates to \`v\`
+ will be atomic.
+
+ **NOTES**
+
+ All resource objects, including the critical section and any captured
+ variables of functions executed on that critical section, will be
+ colocated to the same device (host and cpu/gpu).
+
+ When using multiple critical sections on the same resources, there is no
+ guarantee of exclusive access to those resources. This behavior is disallowed
+ by default (but see the kwarg \`exclusive_resource_access\`).
+
+ For example, running the same function in two separate critical sections
+ will not ensure serial execution:
+
+ \`\`\`python
+ v = tf.compat.v1.get_variable("v", initializer=0.0, use_resource=True)
+ def accumulate(up):
+ x = v.read_value()
+ with tf.control_dependencies([x]):
+ with tf.control_dependencies([v.assign_add(up)]):
+ return tf.identity(x)
+ ex1 = CriticalSection().execute(
+ accumulate, 1.0, exclusive_resource_access=False)
+ ex2 = CriticalSection().execute(
+ accumulate, 1.0, exclusive_resource_access=False)
+ bad_sum = ex1 + ex2
+ sess.run(v.initializer)
+ sess.run(bad_sum) # May return 0.0
+ \`\`\`
+ `],["tf.custom_gradient","description: Decorator to define a function with a custom gradient.",!1,`Decorator to define a function with a custom gradient.
+
+ This decorator allows fine grained control over the gradients of a sequence
+ for operations. This may be useful for multiple reasons, including providing
+ a more efficient or numerically stable gradient for a sequence of operations.
+
+ For example, consider the following function that commonly occurs in the
+ computation of cross entropy and log likelihoods:
+
+ \`\`\`python
+ def log1pexp(x):
+ return tf.math.log(1 + tf.exp(x))
+ \`\`\`
+
+ Due to numerical instability, the gradient of this function evaluated at x=100
+ is NaN. For example:
+
+ \`\`\`python
+ x = tf.constant(100.)
+ y = log1pexp(x)
+ dy_dx = tf.gradients(y, x) # Will be NaN when evaluated.
+ \`\`\`
+
+ The gradient expression can be analytically simplified to provide numerical
+ stability:
+
+ \`\`\`python
+ @tf.custom_gradient
+ def log1pexp(x):
+ e = tf.exp(x)
+ def grad(upstream):
+ return upstream * (1 - 1 / (1 + e))
+ return tf.math.log(1 + e), grad
+ \`\`\`
+
+ With this definition, the gradient \`dy_dx\` at \`x = 100\` will be correctly
+ evaluated as 1.0.
+
+ The variable \`upstream\` is defined as the upstream gradient. i.e. the gradient
+ from all the layers or functions originating from this layer. The above
+ example has no upstream functions, therefore \`upstream = dy/dy = 1.0\`.
+
+ Assume that \`x_i\` is \`log1pexp\` in the forward pass \`x_1 = x_1(x_0)\`,
+ \`x_2 = x_2(x_1)\`, ..., \`x_i = x_i(x_i-1)\`, ..., \`x_n = x_n(x_n-1)\`. By
+ chain rule we know that \`dx_n/dx_0 = dx_n/dx_n-1 * dx_n-1/dx_n-2 * ... *
+ dx_i/dx_i-1 * ... * dx_1/dx_0\`.
+
+ In this case the gradient of our current function defined as
+ \`dx_i/dx_i-1 = (1 - 1 / (1 + e))\`. The upstream gradient \`upstream\` would be
+ \`dx_n/dx_n-1 * dx_n-1/dx_n-2 * ... * dx_i+1/dx_i\`. The upstream gradient
+ multiplied by the current gradient is then passed downstream.
+
+ In case the function takes multiple variables as input, the \`grad\`
+ function must also return the same number of variables.
+ We take the function \`z = x * y\` as an example.
+
+ >>> @tf.custom_gradient
+ ... def bar(x, y):
+ ... def grad(upstream):
+ ... dz_dx = y
+ ... dz_dy = x
+ ... return upstream * dz_dx, upstream * dz_dy
+ ... z = x * y
+ ... return z, grad
+ >>> x = tf.constant(2.0, dtype=tf.float32)
+ >>> y = tf.constant(3.0, dtype=tf.float32)
+ >>> with tf.GradientTape(persistent=True) as tape:
+ ... tape.watch(x)
+ ... tape.watch(y)
+ ... z = bar(x, y)
+ >>> z
+ tf.data.Dataset API for input pipelines.',!0,`\`tf.data.Dataset\` API for input pipelines.
+
+See [Importing Data](https://tensorflow.org/guide/data) for an overview.
+
+`],["tf.debugging","description: Public API for tf.debugging namespace.",!0,`Public API for tf.debugging namespace.
+`],["tf.device","description: Specifies the device for ops created/executed in this context.",!1,`Specifies the device for ops created/executed in this context.
+
+ This function specifies the device to be used for ops created/executed in a
+ particular context. Nested contexts will inherit and also create/execute
+ their ops on the specified device. If a specific device is not required,
+ consider not using this function so that a device can be automatically
+ assigned. In general the use of this function is optional. \`device_name\` can
+ be fully specified, as in "/job:worker/task:1/device:cpu:0", or partially
+ specified, containing only a subset of the "/"-separated fields. Any fields
+ which are specified will override device annotations from outer scopes.
+
+ For example:
+
+ \`\`\`python
+ with tf.device('/job:foo'):
+ # ops created here have devices with /job:foo
+ with tf.device('/job:bar/task:0/device:gpu:2'):
+ # ops created here have the fully specified device above
+ with tf.device('/device:gpu:1'):
+ # ops created here have the device '/job:foo/device:gpu:1'
+ \`\`\`
+
+ Args:
+ device_name: The device name to use in the context.
+
+ Returns:
+ A context manager that specifies the default device to use for newly
+ created ops.
+
+ Raises:
+ RuntimeError: If a function is passed in.
+ `],["tf.DeviceSpec","description: Represents a (possibly partial) specification for a TensorFlow device.",!1,`Represents a (possibly partial) specification for a TensorFlow device.
+
+ \`DeviceSpec\`s are used throughout TensorFlow to describe where state is stored
+ and computations occur. Using \`DeviceSpec\` allows you to parse device spec
+ strings to verify their validity, merge them or compose them programmatically.
+
+ Example:
+
+ \`\`\`python
+ # Place the operations on device "GPU:0" in the "ps" job.
+ device_spec = DeviceSpec(job="ps", device_type="GPU", device_index=0)
+ with tf.device(device_spec.to_string()):
+ # Both my_var and squared_var will be placed on /job:ps/device:GPU:0.
+ my_var = tf.Variable(..., name="my_variable")
+ squared_var = tf.square(my_var)
+ \`\`\`
+
+ With eager execution disabled (by default in TensorFlow 1.x and by calling
+ disable_eager_execution() in TensorFlow 2.x), the following syntax
+ can be used:
+
+ \`\`\`python
+ tf.compat.v1.disable_eager_execution()
+
+ # Same as previous
+ device_spec = DeviceSpec(job="ps", device_type="GPU", device_index=0)
+ # No need of .to_string() method.
+ with tf.device(device_spec):
+ my_var = tf.Variable(..., name="my_variable")
+ squared_var = tf.square(my_var)
+ \`\`\`
+
+ If a \`DeviceSpec\` is partially specified, it will be merged with other
+ \`DeviceSpec\`s according to the scope in which it is defined. \`DeviceSpec\`
+ components defined in inner scopes take precedence over those defined in
+ outer scopes.
+
+ \`\`\`python
+ gpu0_spec = DeviceSpec(job="ps", device_type="GPU", device_index=0)
+ with tf.device(DeviceSpec(job="train").to_string()):
+ with tf.device(gpu0_spec.to_string()):
+ # Nodes created here will be assigned to /job:ps/device:GPU:0.
+ with tf.device(DeviceSpec(device_type="GPU", device_index=1).to_string()):
+ # Nodes created here will be assigned to /job:train/device:GPU:1.
+ \`\`\`
+
+ A \`DeviceSpec\` consists of 5 components -- each of
+ which is optionally specified:
+
+ * Job: The job name.
+ * Replica: The replica index.
+ * Task: The task index.
+ * Device type: The device type string (e.g. "CPU" or "GPU").
+ * Device index: The device index.
+ `],["tf.distribute","description: Library for running a computation across multiple devices.",!0,`Library for running a computation across multiple devices.
+
+The intent of this library is that you can write an algorithm in a stylized way
+and it will be usable with a variety of different \`tf.distribute.Strategy\`
+implementations. Each descendant will implement a different strategy for
+distributing the algorithm across multiple devices/machines. Furthermore, these
+changes can be hidden inside the specific layers and other library classes that
+need special treatment to run in a distributed setting, so that most users'
+model definition code can run unchanged. The \`tf.distribute.Strategy\` API works
+the same way with eager and graph execution.
+
+*Guides*
+
+* [TensorFlow v2.x](https://www.tensorflow.org/guide/distributed_training)
+* [TensorFlow v1.x](https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/distribute_strategy.ipynb)
+
+*Tutorials*
+
+* [Distributed Training Tutorials](https://www.tensorflow.org/tutorials/distribute/)
+
+ The tutorials cover how to use \`tf.distribute.Strategy\` to do distributed
+ training with native Keras APIs, custom training loops,
+ and Estimator APIs. They also cover how to save/load model when using
+ \`tf.distribute.Strategy\`.
+
+*Glossary*
+
+* _Data parallelism_ is where we run multiple copies of the model
+ on different slices of the input data. This is in contrast to
+ _model parallelism_ where we divide up a single copy of a model
+ across multiple devices.
+ Note: we only support data parallelism for now, but
+ hope to add support for model parallelism in the future.
+* A _device_ is a CPU or accelerator (e.g. GPUs, TPUs) on some machine that
+ TensorFlow can run operations on (see e.g. \`tf.device\`). You may have multiple
+ devices on a single machine, or be connected to devices on multiple
+ machines. Devices used to run computations are called _worker devices_.
+ Devices used to store variables are _parameter devices_. For some strategies,
+ such as \`tf.distribute.MirroredStrategy\`, the worker and parameter devices
+ will be the same (see mirrored variables below). For others they will be
+ different. For example, \`tf.distribute.experimental.CentralStorageStrategy\`
+ puts the variables on a single device (which may be a worker device or may be
+ the CPU), and \`tf.distribute.experimental.ParameterServerStrategy\` puts the
+ variables on separate machines called _parameter servers_ (see below).
+* A _replica_ is one copy of the model, running on one slice of the
+ input data. Right now each replica is executed on its own
+ worker device, but once we add support for model parallelism
+ a replica may span multiple worker devices.
+* A _host_ is the CPU device on a machine with worker devices, typically
+ used for running input pipelines.
+* A _worker_ is defined to be the physical machine(s) containing the physical
+ devices (e.g. GPUs, TPUs) on which the replicated computation is executed. A
+ worker may contain one or more replicas, but contains at least one
+ replica. Typically one worker will correspond to one machine, but in the case
+ of very large models with model parallelism, one worker may span multiple
+ machines. We typically run one input pipeline per worker, feeding all the
+ replicas on that worker.
+* _Synchronous_, or more commonly _sync_, training is where the updates from
+ each replica are aggregated together before updating the model variables. This
+ is in contrast to _asynchronous_, or _async_ training, where each replica
+ updates the model variables independently. You may also have replicas
+ partitioned into groups which are in sync within each group but async between
+ groups.
+* _Parameter servers_: These are machines that hold a single copy of
+ parameters/variables, used by some strategies (right now just
+ \`tf.distribute.experimental.ParameterServerStrategy\`). All replicas that want
+ to operate on a variable retrieve it at the beginning of a step and send an
+ update to be applied at the end of the step. These can in principle support
+ either sync or async training, but right now we only have support for async
+ training with parameter servers. Compare to
+ \`tf.distribute.experimental.CentralStorageStrategy\`, which puts all variables
+ on a single device on the same machine (and does sync training), and
+ \`tf.distribute.MirroredStrategy\`, which mirrors variables to multiple devices
+ (see below).
+
+* _Replica context_ vs. _Cross-replica context_ vs _Update context_
+
+ A _replica context_ applies
+ when you execute the computation function that was called with \`strategy.run\`.
+ Conceptually, you're in replica context when executing the computation
+ function that is being replicated.
+
+ An _update context_ is entered in a \`tf.distribute.StrategyExtended.update\`
+ call.
+
+ An _cross-replica context_ is entered when you enter a \`strategy.scope\`. This
+ is useful for calling \`tf.distribute.Strategy\` methods which operate across
+ the replicas (like \`reduce_to()\`). By default you start in a _replica context_
+ (the "default single _replica context_") and then some methods can switch you
+ back and forth.
+
+* _Distributed value_: Distributed value is represented by the base class
+ \`tf.distribute.DistributedValues\`. \`tf.distribute.DistributedValues\` is useful
+ to represent values on multiple devices, and it contains a map from replica id
+ to values. Two representative kinds of \`tf.distribute.DistributedValues\` are
+ "PerReplica" and "Mirrored" values.
+
+ "PerReplica" values exist on the worker
+ devices, with a different value for each replica. They are produced by
+ iterating through a distributed dataset returned by
+ \`tf.distribute.Strategy.experimental_distribute_dataset\` and
+ \`tf.distribute.Strategy.distribute_datasets_from_function\`. They
+ are also the typical result returned by
+ \`tf.distribute.Strategy.run\`.
+
+ "Mirrored" values are like "PerReplica" values, except we know that the value
+ on all replicas are the same. We can safely read a "Mirrored" value in a
+ cross-replica context by using the value on any replica.
+
+* _Unwrapping_ and _merging_: Consider calling a function \`fn\` on multiple
+ replicas, like \`strategy.run(fn, args=[w])\` with an
+ argument \`w\` that is a \`tf.distribute.DistributedValues\`. This means \`w\` will
+ have a map taking replica id \`0\` to \`w0\`, replica id \`1\` to \`w1\`, etc.
+ \`strategy.run()\` unwraps \`w\` before calling \`fn\`, so it calls \`fn(w0)\` on
+ device \`d0\`, \`fn(w1)\` on device \`d1\`, etc. It then merges the return
+ values from \`fn()\`, which leads to one common object if the returned values
+ are the same object from every replica, or a \`DistributedValues\` object
+ otherwise.
+
+* _Reductions_ and _all-reduce_: A _reduction_ is a method of aggregating
+ multiple values into one value, like "sum" or "mean". If a strategy is doing
+ sync training, we will perform a reduction on the gradients to a parameter
+ from all replicas before applying the update. _All-reduce_ is an algorithm for
+ performing a reduction on values from multiple devices and making the result
+ available on all of those devices.
+
+* _Mirrored variables_: These are variables that are created on multiple
+ devices, where we keep the variables in sync by applying the same
+ updates to every copy. Mirrored variables are created with
+ \`tf.Variable(...synchronization=tf.VariableSynchronization.ON_WRITE...)\`.
+ Normally they are only used in synchronous training.
+
+* _SyncOnRead variables_
+
+ _SyncOnRead variables_ are created by
+ \`tf.Variable(...synchronization=tf.VariableSynchronization.ON_READ...)\`, and
+ they are created on multiple devices. In replica context, each
+ component variable on the local replica can perform reads and writes without
+ synchronization with each other. When the
+ _SyncOnRead variable_ is read in cross-replica context, the values from
+ component variables are aggregated and returned.
+
+ _SyncOnRead variables_ bring a lot of custom configuration difficulty to the
+ underlying logic, so we do not encourage users to instantiate and use
+ _SyncOnRead variable_ on their own. We have mainly used _SyncOnRead
+ variables_ for use cases such as batch norm and metrics. For performance
+ reasons, we often don't need to keep these statistics in sync every step and
+ they can be accumulated on each replica independently. The only time we want
+ to sync them is reporting or checkpointing, which typically happens in
+ cross-replica context. _SyncOnRead variables_ are also often used by advanced
+ users who want to control when variable values are aggregated. For example,
+ users sometimes want to maintain gradients independently on each replica for a
+ couple of steps without aggregation.
+
+* _Distribute-aware layers_
+
+ Layers are generally called in a replica context, except when defining a
+ Keras functional model. \`tf.distribute.in_cross_replica_context\` will let you
+ determine which case you are in. If in a replica context,
+ the \`tf.distribute.get_replica_context\` function will return the default
+ replica context outside a strategy scope, \`None\` within a strategy scope, and
+ a \`tf.distribute.ReplicaContext\` object inside a strategy scope and within a
+ \`tf.distribute.Strategy.run\` function. The \`ReplicaContext\` object has an
+ \`all_reduce\` method for aggregating across all replicas.
+
+
+Note that we provide a default version of \`tf.distribute.Strategy\` that is
+used when no other strategy is in scope, that provides the same API with
+reasonable default behavior.
+
+`],["tf.dtypes","description: Public API for tf.dtypes namespace.",!0,`Public API for tf.dtypes namespace.
+`],["tf.dynamic_partition","description: Partitions data into num_partitions tensors using indices from partitions.",!1,'Partitions `data` into `num_partitions` tensors using indices from `partitions`.\n\n For each index tuple `js` of size `partitions.ndim`, the slice `data[js, ...]`\n becomes part of `outputs[partitions[js]]`. The slices with `partitions[js] = i`\n are placed in `outputs[i]` in lexicographic order of `js`, and the first\n dimension of `outputs[i]` is the number of entries in `partitions` equal to `i`.\n In detail,\n\n ```python\n outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:]\n\n outputs[i] = pack([data[js, ...] for js if partitions[js] == i])\n ```\n\n `data.shape` must start with `partitions.shape`.\n\n For example:\n\n ```python\n # Scalar partitions.\n partitions = 1\n num_partitions = 2\n data = [10, 20]\n outputs[0] = [] # Empty with shape [0, 2]\n outputs[1] = [[10, 20]]\n\n # Vector partitions.\n partitions = [0, 0, 1, 1, 0]\n num_partitions = 2\n data = [10, 20, 30, 40, 50]\n outputs[0] = [10, 20, 50]\n outputs[1] = [30, 40]\n ```\n\n See `dynamic_stitch` for an example on how to merge partitions back.\n\n \n 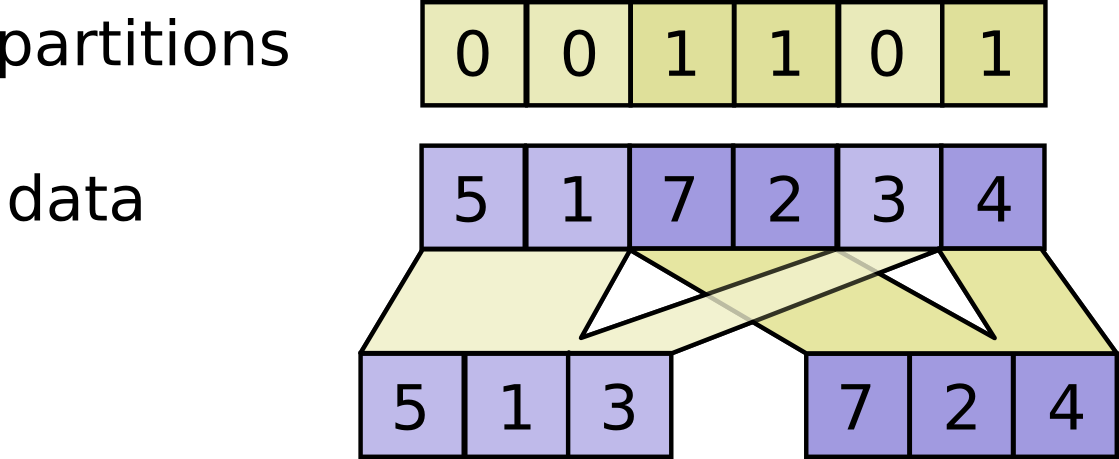 \n
\n
\n\n Args:\n data: A `Tensor`.\n partitions: A `Tensor` of type `int32`.\n Any shape. Indices in the range `[0, num_partitions)`.\n num_partitions: An `int` that is `>= 1`.\n The number of partitions to output.\n name: A name for the operation (optional).\n\n Returns:\n A list of `num_partitions` `Tensor` objects with the same type as `data`.\n '],["tf.dynamic_stitch","description: Interleave the values from the data tensors into a single tensor.",!1,`Interleave the values from the \`data\` tensors into a single tensor.
+
+ Builds a merged tensor such that
+
+ \`\`\`python
+ merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
+ \`\`\`
+
+ For example, if each \`indices[m]\` is scalar or vector, we have
+
+ \`\`\`python
+ # Scalar indices:
+ merged[indices[m], ...] = data[m][...]
+
+ # Vector indices:
+ merged[indices[m][i], ...] = data[m][i, ...]
+ \`\`\`
+
+ Each \`data[i].shape\` must start with the corresponding \`indices[i].shape\`,
+ and the rest of \`data[i].shape\` must be constant w.r.t. \`i\`. That is, we
+ must have \`data[i].shape = indices[i].shape + constant\`. In terms of this
+ \`constant\`, the output shape is
+
+ merged.shape = [max(indices)] + constant
+
+ Values are merged in order, so if an index appears in both \`indices[m][i]\` and
+ \`indices[n][j]\` for \`(m,i) < (n,j)\` the slice \`data[n][j]\` will appear in the
+ merged result. If you do not need this guarantee, ParallelDynamicStitch might
+ perform better on some devices.
+
+ For example:
+
+ \`\`\`python
+ indices[0] = 6
+ indices[1] = [4, 1]
+ indices[2] = [[5, 2], [0, 3]]
+ data[0] = [61, 62]
+ data[1] = [[41, 42], [11, 12]]
+ data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
+ merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
+ [51, 52], [61, 62]]
+ \`\`\`
+
+ This method can be used to merge partitions created by \`dynamic_partition\`
+ as illustrated on the following example:
+
+ \`\`\`python
+ # Apply function (increments x_i) on elements for which a certain condition
+ # apply (x_i != -1 in this example).
+ x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
+ condition_mask=tf.not_equal(x,tf.constant(-1.))
+ partitioned_data = tf.dynamic_partition(
+ x, tf.cast(condition_mask, tf.int32) , 2)
+ partitioned_data[1] = partitioned_data[1] + 1.0
+ condition_indices = tf.dynamic_partition(
+ tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
+ x = tf.dynamic_stitch(condition_indices, partitioned_data)
+ # Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
+ # unchanged.
+ \`\`\`
+
+ \n
+ 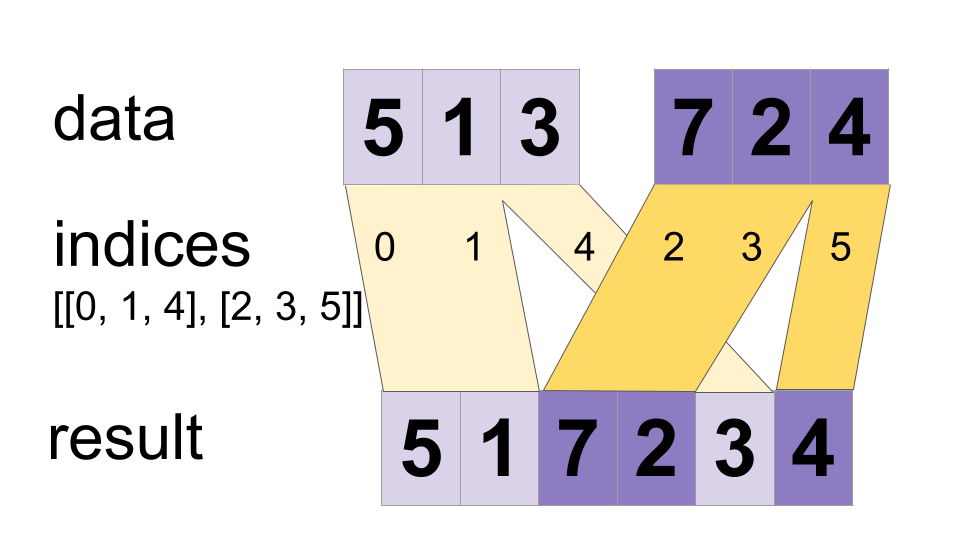 +
+
+
+ Args:
+ indices: A list of at least 1 \`Tensor\` objects with type \`int32\`.
+ data: A list with the same length as \`indices\` of \`Tensor\` objects with the same type.
+ name: A name for the operation (optional).
+
+ Returns:
+ A \`Tensor\`. Has the same type as \`data\`.
+ `],["tf.edit_distance","description: Computes the Levenshtein distance between sequences.",!1,`Computes the Levenshtein distance between sequences.
+
+ This operation takes variable-length sequences (\`hypothesis\` and \`truth\`),
+ each provided as a \`SparseTensor\`, and computes the Levenshtein distance.
+ You can normalize the edit distance by length of \`truth\` by setting
+ \`normalize\` to true.
+
+ For example:
+
+ Given the following input,
+ * \`hypothesis\` is a \`tf.SparseTensor\` of shape \`[2, 1, 1]\`
+ * \`truth\` is a \`tf.SparseTensor\` of shape \`[2, 2, 2]\`
+
+ >>> hypothesis = tf.SparseTensor(
+ ... [[0, 0, 0],
+ ... [1, 0, 0]],
+ ... ["a", "b"],
+ ... (2, 1, 1))
+ >>> truth = tf.SparseTensor(
+ ... [[0, 1, 0],
+ ... [1, 0, 0],
+ ... [1, 0, 1],
+ ... [1, 1, 0]],
+ ... ["a", "b", "c", "a"],
+ ... (2, 2, 2))
+ >>> tf.edit_distance(hypothesis, truth, normalize=True)
+
+
+ +
+
+
+The indices can have any shape. When the \`params\` has 1 axis, the
+output shape is equal to the input shape:
+
+>>> tf.gather(params, [[2, 0], [2, 5]]).numpy()
+array([[b'p2', b'p0'],
+ [b'p2', b'p5']], dtype=object)
+
+The \`params\` may also have any shape. \`gather\` can select slices
+across any axis depending on the \`axis\` argument (which defaults to 0).
+Below it is used to gather first rows, then columns from a matrix:
+
+>>> params = tf.constant([[0, 1.0, 2.0],
+... [10.0, 11.0, 12.0],
+... [20.0, 21.0, 22.0],
+... [30.0, 31.0, 32.0]])
+>>> tf.gather(params, indices=[3,1]).numpy()
+array([[30., 31., 32.],
+ [10., 11., 12.]], dtype=float32)
+>>> tf.gather(params, indices=[2,1], axis=1).numpy()
+array([[ 2., 1.],
+ [12., 11.],
+ [22., 21.],
+ [32., 31.]], dtype=float32)
+
+More generally: The output shape has the same shape as the input, with the
+indexed-axis replaced by the shape of the indices.
+
+>>> def result_shape(p_shape, i_shape, axis=0):
+... return p_shape[:axis] + i_shape + p_shape[axis+1:]
+>>>
+>>> result_shape([1, 2, 3], [], axis=1)
+[1, 3]
+>>> result_shape([1, 2, 3], [7], axis=1)
+[1, 7, 3]
+>>> result_shape([1, 2, 3], [7, 5], axis=1)
+[1, 7, 5, 3]
+
+Here are some examples:
+
+>>> params.shape.as_list()
+[4, 3]
+>>> indices = tf.constant([[0, 2]])
+>>> tf.gather(params, indices=indices, axis=0).shape.as_list()
+[1, 2, 3]
+>>> tf.gather(params, indices=indices, axis=1).shape.as_list()
+[4, 1, 2]
+
+>>> params = tf.random.normal(shape=(5, 6, 7, 8))
+>>> indices = tf.random.uniform(shape=(10, 11), maxval=7, dtype=tf.int32)
+>>> result = tf.gather(params, indices, axis=2)
+>>> result.shape.as_list()
+[5, 6, 10, 11, 8]
+
+This is because each index takes a slice from \`params\`, and
+places it at the corresponding location in the output. For the above example
+
+>>> # For any location in indices
+>>> a, b = 0, 1
+>>> tf.reduce_all(
+... # the corresponding slice of the result
+... result[:, :, a, b, :] ==
+... # is equal to the slice of \`params\` along \`axis\` at the index.
+... params[:, :, indices[a, b], :]
+... ).numpy()
+True
+
+### Batching:
+
+The \`batch_dims\` argument lets you gather different items from each element
+of a batch.
+
+Using \`batch_dims=1\` is equivalent to having an outer loop over the first
+axis of \`params\` and \`indices\`:
+
+>>> params = tf.constant([
+... [0, 0, 1, 0, 2],
+... [3, 0, 0, 0, 4],
+... [0, 5, 0, 6, 0]])
+>>> indices = tf.constant([
+... [2, 4],
+... [0, 4],
+... [1, 3]])
+
+>>> tf.gather(params, indices, axis=1, batch_dims=1).numpy()
+array([[1, 2],
+ [3, 4],
+ [5, 6]], dtype=int32)
+
+This is equivalent to:
+
+>>> def manually_batched_gather(params, indices, axis):
+... batch_dims=1
+... result = []
+... for p,i in zip(params, indices):
+... r = tf.gather(p, i, axis=axis-batch_dims)
+... result.append(r)
+... return tf.stack(result)
+>>> manually_batched_gather(params, indices, axis=1).numpy()
+array([[1, 2],
+ [3, 4],
+ [5, 6]], dtype=int32)
+
+Higher values of \`batch_dims\` are equivalent to multiple nested loops over
+the outer axes of \`params\` and \`indices\`. So the overall shape function is
+
+>>> def batched_result_shape(p_shape, i_shape, axis=0, batch_dims=0):
+... return p_shape[:axis] + i_shape[batch_dims:] + p_shape[axis+1:]
+>>>
+>>> batched_result_shape(
+... p_shape=params.shape.as_list(),
+... i_shape=indices.shape.as_list(),
+... axis=1,
+... batch_dims=1)
+[3, 2]
+
+>>> tf.gather(params, indices, axis=1, batch_dims=1).shape.as_list()
+[3, 2]
+
+This comes up naturally if you need to use the indices of an operation like
+\`tf.argsort\`, or \`tf.math.top_k\` where the last dimension of the indices
+indexes into the last dimension of input, at the corresponding location.
+In this case you can use \`tf.gather(values, indices, batch_dims=-1)\`.
+
+See also:
+
+* \`tf.Tensor.__getitem__\`: The direct tensor index operation (\`t[]\`), handles
+ scalars and python-slices \`tensor[..., 7, 1:-1]\`
+* \`tf.scatter\`: A collection of operations similar to \`__setitem__\`
+ (\`t[i] = x\`)
+* \`tf.gather_nd\`: An operation similar to \`tf.gather\` but gathers across
+ multiple axis at once (it can gather elements of a matrix instead of rows
+ or columns)
+* \`tf.boolean_mask\`, \`tf.where\`: Binary indexing.
+* \`tf.slice\` and \`tf.strided_slice\`: For lower level access to the
+ implementation of \`__getitem__\`'s python-slice handling (\`t[1:-1:2]\`)
+
+Args:
+ params: The \`Tensor\` from which to gather values. Must be at least rank
+ \`axis + 1\`.
+ indices: The index \`Tensor\`. Must be one of the following types: \`int32\`,
+ \`int64\`. The values must be in range \`[0, params.shape[axis])\`.
+ validate_indices: Deprecated, does nothing. Indices are always validated on
+ CPU, never validated on GPU.
+
+ Caution: On CPU, if an out of bound index is found, an error is raised.
+ On GPU, if an out of bound index is found, a 0 is stored in the
+ corresponding output value.
+ axis: A \`Tensor\`. Must be one of the following types: \`int32\`, \`int64\`. The
+ \`axis\` in \`params\` to gather \`indices\` from. Must be greater than or equal
+ to \`batch_dims\`. Defaults to the first non-batch dimension. Supports
+ negative indexes.
+ batch_dims: An \`integer\`. The number of batch dimensions. Must be less
+ than or equal to \`rank(indices)\`.
+ name: A name for the operation (optional).
+
+Returns:
+ A \`Tensor\`. Has the same type as \`params\`.`],["tf.gather_nd","description: Gather slices from params into a Tensor with shape specified by indices.",!1,`Gather slices from \`params\` into a Tensor with shape specified by \`indices\`.
+
+ \`indices\` is a \`Tensor\` of indices into \`params\`. The index vectors are
+ arranged along the last axis of \`indices\`.
+
+ This is similar to \`tf.gather\`, in which \`indices\` defines slices into the
+ first dimension of \`params\`. In \`tf.gather_nd\`, \`indices\` defines slices into the
+ first \`N\` dimensions of \`params\`, where \`N = indices.shape[-1]\`.
+
+ Caution: On CPU, if an out of bound index is found, an error is returned.
+ On GPU, if an out of bound index is found, a 0 is stored in the
+ corresponding output value.
+
+ ## Gathering scalars
+
+ In the simplest case the vectors in \`indices\` index the full rank of \`params\`:
+
+ >>> tf.gather_nd(
+ ... indices=[[0, 0],
+ ... [1, 1]],
+ ... params = [['a', 'b'],
+ ... ['c', 'd']]).numpy()
+ array([b'a', b'd'], dtype=object)
+
+ In this case the result has 1-axis fewer than \`indices\`, and each index vector
+ is replaced by the scalar indexed from \`params\`.
+
+ In this case the shape relationship is:
+
+ \`\`\`
+ index_depth = indices.shape[-1]
+ assert index_depth == params.shape.rank
+ result_shape = indices.shape[:-1]
+ \`\`\`
+
+ If \`indices\` has a rank of \`K\`, it is helpful to think \`indices\` as a
+ (K-1)-dimensional tensor of indices into \`params\`.
+
+ ## Gathering slices
+
+ If the index vectors do not index the full rank of \`params\` then each location
+ in the result contains a slice of params. This example collects rows from a
+ matrix:
+
+ >>> tf.gather_nd(
+ ... indices = [[1],
+ ... [0]],
+ ... params = [['a', 'b', 'c'],
+ ... ['d', 'e', 'f']]).numpy()
+ array([[b'd', b'e', b'f'],
+ [b'a', b'b', b'c']], dtype=object)
+
+ Here \`indices\` contains \`[2]\` index vectors, each with a length of \`1\`.
+ The index vectors each refer to rows of the \`params\` matrix. Each
+ row has a shape of \`[3]\` so the output shape is \`[2, 3]\`.
+
+ In this case, the relationship between the shapes is:
+
+ \`\`\`
+ index_depth = indices.shape[-1]
+ outer_shape = indices.shape[:-1]
+ assert index_depth <= params.shape.rank
+ inner_shape = params.shape[index_depth:]
+ output_shape = outer_shape + inner_shape
+ \`\`\`
+
+ It is helpful to think of the results in this case as tensors-of-tensors.
+ The shape of the outer tensor is set by the leading dimensions of \`indices\`.
+ While the shape of the inner tensors is the shape of a single slice.
+
+ ## Batches
+
+ Additionally both \`params\` and \`indices\` can have \`M\` leading batch
+ dimensions that exactly match. In this case \`batch_dims\` must be set to \`M\`.
+
+ For example, to collect one row from each of a batch of matrices you could
+ set the leading elements of the index vectors to be their location in the
+ batch:
+
+ >>> tf.gather_nd(
+ ... indices = [[0, 1],
+ ... [1, 0],
+ ... [2, 4],
+ ... [3, 2],
+ ... [4, 1]],
+ ... params=tf.zeros([5, 7, 3])).shape.as_list()
+ [5, 3]
+
+ The \`batch_dims\` argument lets you omit those leading location dimensions
+ from the index:
+
+ >>> tf.gather_nd(
+ ... batch_dims=1,
+ ... indices = [[1],
+ ... [0],
+ ... [4],
+ ... [2],
+ ... [1]],
+ ... params=tf.zeros([5, 7, 3])).shape.as_list()
+ [5, 3]
+
+ This is equivalent to caling a separate \`gather_nd\` for each location in the
+ batch dimensions.
+
+
+ >>> params=tf.zeros([5, 7, 3])
+ >>> indices=tf.zeros([5, 1])
+ >>> batch_dims = 1
+ >>>
+ >>> index_depth = indices.shape[-1]
+ >>> batch_shape = indices.shape[:batch_dims]
+ >>> assert params.shape[:batch_dims] == batch_shape
+ >>> outer_shape = indices.shape[batch_dims:-1]
+ >>> assert index_depth <= params.shape.rank
+ >>> inner_shape = params.shape[batch_dims + index_depth:]
+ >>> output_shape = batch_shape + outer_shape + inner_shape
+ >>> output_shape.as_list()
+ [5, 3]
+
+ ### More examples
+
+ Indexing into a 3-tensor:
+
+ >>> tf.gather_nd(
+ ... indices = [[1]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[[b'a1', b'b1'],
+ [b'c1', b'd1']]], dtype=object)
+
+
+
+ >>> tf.gather_nd(
+ ... indices = [[0, 1], [1, 0]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[b'c0', b'd0'],
+ [b'a1', b'b1']], dtype=object)
+
+
+ >>> tf.gather_nd(
+ ... indices = [[0, 0, 1], [1, 0, 1]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([b'b0', b'b1'], dtype=object)
+
+ The examples below are for the case when only indices have leading extra
+ dimensions. If both 'params' and 'indices' have leading batch dimensions, use
+ the 'batch_dims' parameter to run gather_nd in batch mode.
+
+ Batched indexing into a matrix:
+
+ >>> tf.gather_nd(
+ ... indices = [[[0, 0]], [[0, 1]]],
+ ... params = [['a', 'b'], ['c', 'd']]).numpy()
+ array([[b'a'],
+ [b'b']], dtype=object)
+
+
+
+ Batched slice indexing into a matrix:
+
+ >>> tf.gather_nd(
+ ... indices = [[[1]], [[0]]],
+ ... params = [['a', 'b'], ['c', 'd']]).numpy()
+ array([[[b'c', b'd']],
+ [[b'a', b'b']]], dtype=object)
+
+
+ Batched indexing into a 3-tensor:
+
+ >>> tf.gather_nd(
+ ... indices = [[[1]], [[0]]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[[[b'a1', b'b1'],
+ [b'c1', b'd1']]],
+ [[[b'a0', b'b0'],
+ [b'c0', b'd0']]]], dtype=object)
+
+
+ >>> tf.gather_nd(
+ ... indices = [[[0, 1], [1, 0]], [[0, 0], [1, 1]]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[[b'c0', b'd0'],
+ [b'a1', b'b1']],
+ [[b'a0', b'b0'],
+ [b'c1', b'd1']]], dtype=object)
+
+ >>> tf.gather_nd(
+ ... indices = [[[0, 0, 1], [1, 0, 1]], [[0, 1, 1], [1, 1, 0]]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[b'b0', b'b1'],
+ [b'd0', b'c1']], dtype=object)
+
+
+ Examples with batched 'params' and 'indices':
+
+ >>> tf.gather_nd(
+ ... batch_dims = 1,
+ ... indices = [[1],
+ ... [0]],
+ ... params = [[['a0', 'b0'],
+ ... ['c0', 'd0']],
+ ... [['a1', 'b1'],
+ ... ['c1', 'd1']]]).numpy()
+ array([[b'c0', b'd0'],
+ [b'a1', b'b1']], dtype=object)
+
+
+ >>> tf.gather_nd(
+ ... batch_dims = 1,
+ ... indices = [[[1]], [[0]]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[[b'c0', b'd0']],
+ [[b'a1', b'b1']]], dtype=object)
+
+ >>> tf.gather_nd(
+ ... batch_dims = 1,
+ ... indices = [[[1, 0]], [[0, 1]]],
+ ... params = [[['a0', 'b0'], ['c0', 'd0']],
+ ... [['a1', 'b1'], ['c1', 'd1']]]).numpy()
+ array([[b'c0'],
+ [b'b1']], dtype=object)
+
+
+ See also \`tf.gather\`.
+
+ Args:
+ params: A \`Tensor\`. The tensor from which to gather values.
+ indices: A \`Tensor\`. Must be one of the following types: \`int32\`, \`int64\`.
+ Index tensor.
+ name: A name for the operation (optional).
+ batch_dims: An integer or a scalar 'Tensor'. The number of batch dimensions.
+
+ Returns:
+ A \`Tensor\`. Has the same type as \`params\`.
+ `],["tf.get_current_name_scope",'description: Returns current full name scope specified by
+tf.name_scope(...)s.',!1,`Returns current full name scope specified by \`tf.name_scope(...)\`s.
+
+ For example,
+ \`\`\`python
+ with tf.name_scope("outer"):
+ tf.get_current_name_scope() # "outer"
+
+ with tf.name_scope("inner"):
+ tf.get_current_name_scope() # "outer/inner"
+ \`\`\`
+
+ In other words, \`tf.get_current_name_scope()\` returns the op name prefix that
+ will be prepended to, if an op is created at that place.
+
+ Note that \`@tf.function\` resets the name scope stack as shown below.
+
+ \`\`\`
+ with tf.name_scope("outer"):
+
+ @tf.function
+ def foo(x):
+ with tf.name_scope("inner"):
+ return tf.add(x * x) # Op name is "inner/Add", not "outer/inner/Add"
+ \`\`\`
+ `],["tf.get_logger","description: Return TF logger instance.",!1,"Return TF logger instance."],["tf.get_static_value","description: Returns the constant value of the given tensor, if efficiently calculable.",!1,`Returns the constant value of the given tensor, if efficiently calculable.
+
+ This function attempts to partially evaluate the given tensor, and
+ returns its value as a numpy ndarray if this succeeds.
+
+ Example usage:
+
+ >>> a = tf.constant(10)
+ >>> tf.get_static_value(a)
+ 10
+ >>> b = tf.constant(20)
+ >>> tf.get_static_value(tf.add(a, b))
+ 30
+
+ >>> # \`tf.Variable\` is not supported.
+ >>> c = tf.Variable(30)
+ >>> print(tf.get_static_value(c))
+ None
+
+ Using \`partial\` option is most relevant when calling \`get_static_value\` inside
+ a \`tf.function\`. Setting it to \`True\` will return the results but for the
+ values that cannot be evaluated will be \`None\`. For example:
+
+ \`\`\`python
+ class Foo(object):
+ def __init__(self):
+ self.a = tf.Variable(1)
+ self.b = tf.constant(2)
+
+ @tf.function
+ def bar(self, partial):
+ packed = tf.raw_ops.Pack(values=[self.a, self.b])
+ static_val = tf.get_static_value(packed, partial=partial)
+ tf.print(static_val)
+
+ f = Foo()
+ f.bar(partial=True) # \`array([None, array(2, dtype=int32)], dtype=object)\`
+ f.bar(partial=False) # \`None\`
+ \`\`\`
+
+ Compatibility(V1): If \`constant_value(tensor)\` returns a non-\`None\` result, it
+ will no longer be possible to feed a different value for \`tensor\`. This allows
+ the result of this function to influence the graph that is constructed, and
+ permits static shape optimizations.
+
+ Args:
+ tensor: The Tensor to be evaluated.
+ partial: If True, the returned numpy array is allowed to have partially
+ evaluated values. Values that can't be evaluated will be None.
+
+ Returns:
+ A numpy ndarray containing the constant value of the given \`tensor\`,
+ or None if it cannot be calculated.
+
+ Raises:
+ TypeError: if tensor is not an ops.Tensor.
+ `],["tf.gradients","description: Constructs symbolic derivatives of sum of ys w.r.t. x in xs.",!1,"Constructs symbolic derivatives of sum of `ys` w.r.t. x in `xs`.\n\n `tf.gradients` is only valid in a graph context. In particular,\n it is valid in the context of a `tf.function` wrapper, where code\n is executing as a graph.\n\n `ys` and `xs` are each a `Tensor` or a list of tensors. `grad_ys`\n is a list of `Tensor`, holding the gradients received by the\n `ys`. The list must be the same length as `ys`.\n\n `gradients()` adds ops to the graph to output the derivatives of `ys` with\n respect to `xs`. It returns a list of `Tensor` of length `len(xs)` where\n each tensor is the `sum(dy/dx)` for y in `ys` and for x in `xs`.\n\n `grad_ys` is a list of tensors of the same length as `ys` that holds\n the initial gradients for each y in `ys`. When `grad_ys` is None,\n we fill in a tensor of '1's of the shape of y for each y in `ys`. A\n user can provide their own initial `grad_ys` to compute the\n derivatives using a different initial gradient for each y (e.g., if\n one wanted to weight the gradient differently for each value in\n each y).\n\n `stop_gradients` is a `Tensor` or a list of tensors to be considered constant\n with respect to all `xs`. These tensors will not be backpropagated through,\n as though they had been explicitly disconnected using `stop_gradient`. Among\n other things, this allows computation of partial derivatives as opposed to\n total derivatives. For example:\n\n >>> @tf.function\n ... def example():\n ... a = tf.constant(0.)\n ... b = 2 * a\n ... return tf.gradients(a + b, [a, b], stop_gradients=[a, b])\n >>> example()\n [tf.IndexedSlices.',!1,"Type specification for a `tf.IndexedSlices`."],["tf.init_scope","description: A context manager that lifts ops out of control-flow scopes and function-building graphs.",!1,`A context manager that lifts ops out of control-flow scopes and function-building graphs.
+
+ There is often a need to lift variable initialization ops out of control-flow
+ scopes, function-building graphs, and gradient tapes. Entering an
+ \`init_scope\` is a mechanism for satisfying these desiderata. In particular,
+ entering an \`init_scope\` has three effects:
+
+ (1) All control dependencies are cleared the moment the scope is entered;
+ this is equivalent to entering the context manager returned from
+ \`control_dependencies(None)\`, which has the side-effect of exiting
+ control-flow scopes like \`tf.cond\` and \`tf.while_loop\`.
+
+ (2) All operations that are created while the scope is active are lifted
+ into the lowest context on the \`context_stack\` that is not building a
+ graph function. Here, a context is defined as either a graph or an eager
+ context. Every context switch, i.e., every installation of a graph as
+ the default graph and every switch into eager mode, is logged in a
+ thread-local stack called \`context_switches\`; the log entry for a
+ context switch is popped from the stack when the context is exited.
+ Entering an \`init_scope\` is equivalent to crawling up
+ \`context_switches\`, finding the first context that is not building a
+ graph function, and entering it. A caveat is that if graph mode is
+ enabled but the default graph stack is empty, then entering an
+ \`init_scope\` will simply install a fresh graph as the default one.
+
+ (3) The gradient tape is paused while the scope is active.
+
+ When eager execution is enabled, code inside an init_scope block runs with
+ eager execution enabled even when tracing a \`tf.function\`. For example:
+
+ \`\`\`python
+ tf.compat.v1.enable_eager_execution()
+
+ @tf.function
+ def func():
+ # A function constructs TensorFlow graphs,
+ # it does not execute eagerly.
+ assert not tf.executing_eagerly()
+ with tf.init_scope():
+ # Initialization runs with eager execution enabled
+ assert tf.executing_eagerly()
+ \`\`\`
+
+ Raises:
+ RuntimeError: if graph state is incompatible with this initialization.
+ `],["tf.inside_function",'description: Indicates whether the caller code is executing inside a tf.function.',!1,`Indicates whether the caller code is executing inside a \`tf.function\`.
+
+ Returns:
+ Boolean, True if the caller code is executing inside a \`tf.function\`
+ rather than eagerly.
+
+ Example:
+
+ >>> tf.inside_function()
+ False
+ >>> @tf.function
+ ... def f():
+ ... print(tf.inside_function())
+ >>> f()
+ True
+ `],["tf.io","description: Public API for tf.io namespace.",!0,`Public API for tf.io namespace.
+`],["tf.is_tensor","description: Checks whether x is a TF-native type that can be passed to many TF ops.",!1,"Checks whether `x` is a TF-native type that can be passed to many TF ops.\n\n Use `is_tensor` to differentiate types that can ingested by TensorFlow ops\n without any conversion (e.g., `tf.Tensor`, `tf.SparseTensor`, and\n `tf.RaggedTensor`) from types that need to be converted into tensors before\n they are ingested (e.g., numpy `ndarray` and Python scalars).\n\n For example, in the following code block:\n\n ```python\n if not tf.is_tensor(t):\n t = tf.convert_to_tensor(t)\n return t.shape, t.dtype\n ```\n\n we check to make sure that `t` is a tensor (and convert it if not) before\n accessing its `shape` and `dtype`. (But note that not all TensorFlow native\n types have shapes or dtypes; `tf.data.Dataset` is an example of a TensorFlow\n native type that has neither shape nor dtype.)\n\n Args:\n x: A python object to check.\n\n Returns:\n `True` if `x` is a TensorFlow-native type.\n "],["tf.keras","description: Implementation of the Keras API, the high-level API of TensorFlow.",!0,`Implementation of the Keras API, the high-level API of TensorFlow.
+
+Detailed documentation and user guides are available at
+[keras.io](https://keras.io).
+
+`],["tf.linalg","description: Operations for linear algebra.",!0,`Operations for linear algebra.
+`],["tf.linspace","description: Generates evenly-spaced values in an interval along a given axis.",!1,'Generates evenly-spaced values in an interval along a given axis.\n\n A sequence of `num` evenly-spaced values are generated beginning at `start`\n along a given `axis`.\n If `num > 1`, the values in the sequence increase by\n `(stop - start) / (num - 1)`, so that the last one is exactly `stop`.\n If `num <= 0`, `ValueError` is raised.\n\n Matches\n [np.linspace](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html)\'s\n behaviour\n except when `num == 0`.\n\n For example:\n\n ```\n tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0]\n ```\n\n `Start` and `stop` can be tensors of arbitrary size:\n\n >>> tf.linspace([0., 5.], [10., 40.], 5, axis=0)\n tf.experimental.Optional.',!1,`Type specification for \`tf.experimental.Optional\`.
+
+ For instance, \`tf.OptionalSpec\` can be used to define a tf.function that takes
+ \`tf.experimental.Optional\` as an input argument:
+
+ >>> @tf.function(input_signature=[tf.OptionalSpec(
+ ... tf.TensorSpec(shape=(), dtype=tf.int32, name=None))])
+ ... def maybe_square(optional):
+ ... if optional.has_value():
+ ... x = optional.get_value()
+ ... return x * x
+ ... return -1
+ >>> optional = tf.experimental.Optional.from_value(5)
+ >>> print(maybe_square(optional))
+ tf.Tensor(25, shape=(), dtype=int32)
+
+ Attributes:
+ element_spec: A (nested) structure of \`TypeSpec\` objects that represents the
+ type specification of the optional element.
+ `],["tf.pad","description: Pads a tensor.",!1,'Pads a tensor.\n\n This operation pads a `tensor` according to the `paddings` you specify.\n `paddings` is an integer tensor with shape `[n, 2]`, where n is the rank of\n `tensor`. For each dimension D of `input`, `paddings[D, 0]` indicates how\n many values to add before the contents of `tensor` in that dimension, and\n `paddings[D, 1]` indicates how many values to add after the contents of\n `tensor` in that dimension. If `mode` is "REFLECT" then both `paddings[D, 0]`\n and `paddings[D, 1]` must be no greater than `tensor.dim_size(D) - 1`. If\n `mode` is "SYMMETRIC" then both `paddings[D, 0]` and `paddings[D, 1]` must be\n no greater than `tensor.dim_size(D)`.\n\n The padded size of each dimension D of the output is:\n\n `paddings[D, 0] + tensor.dim_size(D) + paddings[D, 1]`\n\n For example:\n\n ```python\n t = tf.constant([[1, 2, 3], [4, 5, 6]])\n paddings = tf.constant([[1, 1,], [2, 2]])\n # \'constant_values\' is 0.\n # rank of \'t\' is 2.\n tf.pad(t, paddings, "CONSTANT") # [[0, 0, 0, 0, 0, 0, 0],\n # [0, 0, 1, 2, 3, 0, 0],\n # [0, 0, 4, 5, 6, 0, 0],\n # [0, 0, 0, 0, 0, 0, 0]]\n\n tf.pad(t, paddings, "REFLECT") # [[6, 5, 4, 5, 6, 5, 4],\n # [3, 2, 1, 2, 3, 2, 1],\n # [6, 5, 4, 5, 6, 5, 4],\n # [3, 2, 1, 2, 3, 2, 1]]\n\n tf.pad(t, paddings, "SYMMETRIC") # [[2, 1, 1, 2, 3, 3, 2],\n # [2, 1, 1, 2, 3, 3, 2],\n # [5, 4, 4, 5, 6, 6, 5],\n # [5, 4, 4, 5, 6, 6, 5]]\n ```\n\n Args:\n tensor: A `Tensor`.\n paddings: A `Tensor` of type `int32`.\n mode: One of "CONSTANT", "REFLECT", or "SYMMETRIC" (case-insensitive)\n constant_values: In "CONSTANT" mode, the scalar pad value to use. Must be\n same type as `tensor`.\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor`. Has the same type as `tensor`.\n\n Raises:\n ValueError: When mode is not one of "CONSTANT", "REFLECT", or "SYMMETRIC".\n '],["tf.parallel_stack","description: Stacks a list of rank-R tensors into one rank-(R+1) tensor in parallel.",!1,`Stacks a list of rank-\`R\` tensors into one rank-\`(R+1)\` tensor in parallel.
+
+ Requires that the shape of inputs be known at graph construction time.
+
+ Packs the list of tensors in \`values\` into a tensor with rank one higher than
+ each tensor in \`values\`, by packing them along the first dimension.
+ Given a list of length \`N\` of tensors of shape \`(A, B, C)\`; the \`output\`
+ tensor will have the shape \`(N, A, B, C)\`.
+
+ For example:
+
+ \`\`\`python
+ x = tf.constant([1, 4])
+ y = tf.constant([2, 5])
+ z = tf.constant([3, 6])
+ tf.parallel_stack([x, y, z]) # [[1, 4], [2, 5], [3, 6]]
+ \`\`\`
+
+ The difference between \`stack\` and \`parallel_stack\` is that \`stack\` requires
+ all the inputs be computed before the operation will begin but doesn't require
+ that the input shapes be known during graph construction.
+
+ \`parallel_stack\` will copy pieces of the input into the output as they become
+ available, in some situations this can provide a performance benefit.
+
+ Unlike \`stack\`, \`parallel_stack\` does NOT support backpropagation.
+
+ This is the opposite of unstack. The numpy equivalent is
+
+ tf.parallel_stack([x, y, z]) = np.asarray([x, y, z])
+
+ @compatibility(eager)
+ parallel_stack is not compatible with eager execution.
+ @end_compatibility
+
+ Args:
+ values: A list of \`Tensor\` objects with the same shape and type.
+ name: A name for this operation (optional).
+
+ Returns:
+ output: A stacked \`Tensor\` with the same type as \`values\`.
+
+ Raises:
+ RuntimeError: if executed in eager mode.
+ `],["tf.print","description: Print the specified inputs.",!1,`Print the specified inputs.
+
+ A TensorFlow operator that prints the specified inputs to a desired
+ output stream or logging level. The inputs may be dense or sparse Tensors,
+ primitive python objects, data structures that contain tensors, and printable
+ Python objects. Printed tensors will recursively show the first and last
+ elements of each dimension to summarize.
+
+ Example:
+ Single-input usage:
+
+ \`\`\`python
+ tensor = tf.range(10)
+ tf.print(tensor, output_stream=sys.stderr)
+ \`\`\`
+
+ (This prints "[0 1 2 ... 7 8 9]" to sys.stderr)
+
+ Multi-input usage:
+
+ \`\`\`python
+ tensor = tf.range(10)
+ tf.print("tensors:", tensor, {2: tensor * 2}, output_stream=sys.stdout)
+ \`\`\`
+
+ (This prints "tensors: [0 1 2 ... 7 8 9] {2: [0 2 4 ... 14 16 18]}" to
+ sys.stdout)
+
+ Changing the input separator:
+ \`\`\`python
+ tensor_a = tf.range(2)
+ tensor_b = tensor_a * 2
+ tf.print(tensor_a, tensor_b, output_stream=sys.stderr, sep=',')
+ \`\`\`
+
+ (This prints "[0 1],[0 2]" to sys.stderr)
+
+ Usage in a \`tf.function\`:
+
+ \`\`\`python
+ @tf.function
+ def f():
+ tensor = tf.range(10)
+ tf.print(tensor, output_stream=sys.stderr)
+ return tensor
+
+ range_tensor = f()
+ \`\`\`
+
+ (This prints "[0 1 2 ... 7 8 9]" to sys.stderr)
+
+ *Compatibility usage in TF 1.x graphs*:
+
+ In graphs manually created outside of \`tf.function\`, this method returns
+ the created TF operator that prints the data. To make sure the
+ operator runs, users need to pass the produced op to
+ \`tf.compat.v1.Session\`'s run method, or to use the op as a control
+ dependency for executed ops by specifying
+ \`with tf.compat.v1.control_dependencies([print_op])\`.
+
+ \`\`\`python
+ tf.compat.v1.disable_v2_behavior() # for TF1 compatibility only
+
+ sess = tf.compat.v1.Session()
+ with sess.as_default():
+ tensor = tf.range(10)
+ print_op = tf.print("tensors:", tensor, {2: tensor * 2},
+ output_stream=sys.stdout)
+ with tf.control_dependencies([print_op]):
+ tripled_tensor = tensor * 3
+
+ sess.run(tripled_tensor)
+ \`\`\`
+
+ (This prints "tensors: [0 1 2 ... 7 8 9] {2: [0 2 4 ... 14 16 18]}" to
+ sys.stdout)
+
+ Note: In Jupyter notebooks and colabs, \`tf.print\` prints to the notebook
+ cell outputs. It will not write to the notebook kernel's console logs.
+
+ Args:
+ *inputs: Positional arguments that are the inputs to print. Inputs in the
+ printed output will be separated by spaces. Inputs may be python
+ primitives, tensors, data structures such as dicts and lists that may
+ contain tensors (with the data structures possibly nested in arbitrary
+ ways), and printable python objects.
+ output_stream: The output stream, logging level, or file to print to.
+ Defaults to sys.stderr, but sys.stdout, tf.compat.v1.logging.info,
+ tf.compat.v1.logging.warning, tf.compat.v1.logging.error,
+ absl.logging.info, absl.logging.warning and absl.logging.error are also
+ supported. To print to a file, pass a string started with "file://"
+ followed by the file path, e.g., "file:///tmp/foo.out".
+ summarize: The first and last \`summarize\` elements within each dimension are
+ recursively printed per Tensor. If None, then the first 3 and last 3
+ elements of each dimension are printed for each tensor. If set to -1, it
+ will print all elements of every tensor.
+ sep: The string to use to separate the inputs. Defaults to " ".
+ end: End character that is appended at the end the printed string. Defaults
+ to the newline character.
+ name: A name for the operation (optional).
+
+ Returns:
+ None when executing eagerly. During graph tracing this returns
+ a TF operator that prints the specified inputs in the specified output
+ stream or logging level. This operator will be automatically executed
+ except inside of \`tf.compat.v1\` graphs and sessions.
+
+ Raises:
+ ValueError: If an unsupported output stream is specified.
+ `],["tf.profiler","description: Public API for tf.profiler namespace.",!0,`Public API for tf.profiler namespace.
+`],["tf.py_function","description: Wraps a python function into a TensorFlow op that executes it eagerly.",!1,"Wraps a python function into a TensorFlow op that executes it eagerly.\n\n This function allows expressing computations in a TensorFlow graph as\n Python functions. In particular, it wraps a Python function `func`\n in a once-differentiable TensorFlow operation that executes it with eager\n execution enabled. As a consequence, `tf.py_function` makes it\n possible to express control flow using Python constructs (`if`, `while`,\n `for`, etc.), instead of TensorFlow control flow constructs (`tf.cond`,\n `tf.while_loop`). For example, you might use `tf.py_function` to\n implement the log huber function:\n\n ```python\n def log_huber(x, m):\n if tf.abs(x) <= m:\n return x**2\n else:\n return m**2 * (1 - 2 * tf.math.log(m) + tf.math.log(x**2))\n\n x = tf.constant(1.0)\n m = tf.constant(2.0)\n\n with tf.GradientTape() as t:\n t.watch([x, m])\n y = tf.py_function(func=log_huber, inp=[x, m], Tout=tf.float32)\n\n dy_dx = t.gradient(y, x)\n assert dy_dx.numpy() == 2.0\n ```\n\n You can also use `tf.py_function` to debug your models at runtime\n using Python tools, i.e., you can isolate portions of your code that\n you want to debug, wrap them in Python functions and insert `pdb` tracepoints\n or print statements as desired, and wrap those functions in\n `tf.py_function`.\n\n For more information on eager execution, see the\n [Eager guide](https://tensorflow.org/guide/eager).\n\n `tf.py_function` is similar in spirit to `tf.compat.v1.py_func`, but unlike\n the latter, the former lets you use TensorFlow operations in the wrapped\n Python function. In particular, while `tf.compat.v1.py_func` only runs on CPUs\n and wraps functions that take NumPy arrays as inputs and return NumPy arrays\n as outputs, `tf.py_function` can be placed on GPUs and wraps functions\n that take Tensors as inputs, execute TensorFlow operations in their bodies,\n and return Tensors as outputs.\n\n Note: We recommend to avoid using `tf.py_function` outside of prototyping\n and experimentation due to the following known limitations:\n\n * Calling `tf.py_function` will acquire the Python Global Interpreter Lock\n (GIL) that allows only one thread to run at any point in time. This will\n preclude efficient parallelization and distribution of the execution of the\n program.\n\n * The body of the function (i.e. `func`) will not be serialized in a\n `GraphDef`. Therefore, you should not use this function if you need to\n serialize your model and restore it in a different environment.\n\n * The operation must run in the same address space as the Python program\n that calls `tf.py_function()`. If you are using distributed\n TensorFlow, you must run a `tf.distribute.Server` in the same process as the\n program that calls `tf.py_function()` and you must pin the created\n operation to a device in that server (e.g. using `with tf.device():`).\n\n * Currently `tf.py_function` is not compatible with XLA. Calling\n `tf.py_function` inside `tf.function(jit_comiple=True)` will raise an\n error.\n\n Args:\n func: A Python function that accepts `inp` as arguments, and returns a\n value (or list of values) whose type is described by `Tout`.\n\n inp: Input arguments for `func`. A list whose elements are `Tensor`s or\n `CompositeTensors` (such as `tf.RaggedTensor`); or a single `Tensor` or\n `CompositeTensor`.\n\n Tout: The type(s) of the value(s) returned by `func`. One of the\n following.\n\n * If `func` returns a `Tensor` (or a value that can be converted to a\n Tensor): the `tf.DType` for that value.\n * If `func` returns a `CompositeTensor`: The `tf.TypeSpec` for that value.\n * If `func` returns `None`: the empty list (`[]`).\n * If `func` returns a list of `Tensor` and `CompositeTensor` values:\n a corresponding list of `tf.DType`s and `tf.TypeSpec`s for each value.\n\n name: A name for the operation (optional).\n\n Returns:\n The value(s) computed by `func`: a `Tensor`, `CompositeTensor`, or list of\n `Tensor` and `CompositeTensor`; or an empty list if `func` returns `None`.\n "],["tf.quantization","description: Public API for tf.quantization namespace.",!0,`Public API for tf.quantization namespace.
+`],["tf.queue","description: Public API for tf.queue namespace.",!0,`Public API for tf.queue namespace.
+`],["tf.ragged","description: Ragged Tensors.",!0,"Ragged Tensors.\n\nThis package defines ops for manipulating ragged tensors (`tf.RaggedTensor`),\nwhich are tensors with non-uniform shapes. In particular, each `RaggedTensor`\nhas one or more *ragged dimensions*, which are dimensions whose slices may have\ndifferent lengths. For example, the inner (column) dimension of\n`rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []]` is ragged, since the column slices\n(`rt[0, :]`, ..., `rt[4, :]`) have different lengths. For a more detailed\ndescription of ragged tensors, see the `tf.RaggedTensor` class documentation\nand the [Ragged Tensor Guide](/guide/ragged_tensor).\n\n\n### Additional ops that support `RaggedTensor`\n\nArguments that accept `RaggedTensor`s are marked in **bold**.\n\n* `tf.__operators__.eq`(**self**, **other**)\n* `tf.__operators__.ne`(**self**, **other**)\n* `tf.bitcast`(**input**, type, name=`None`)\n* `tf.bitwise.bitwise_and`(**x**, **y**, name=`None`)\n* `tf.bitwise.bitwise_or`(**x**, **y**, name=`None`)\n* `tf.bitwise.bitwise_xor`(**x**, **y**, name=`None`)\n* `tf.bitwise.invert`(**x**, name=`None`)\n* `tf.bitwise.left_shift`(**x**, **y**, name=`None`)\n* `tf.bitwise.right_shift`(**x**, **y**, name=`None`)\n* `tf.broadcast_to`(**input**, **shape**, name=`None`)\n* `tf.cast`(**x**, dtype, name=`None`)\n* `tf.clip_by_value`(**t**, clip_value_min, clip_value_max, name=`None`)\n* `tf.concat`(**values**, axis, name=`'concat'`)\n* `tf.debugging.check_numerics`(**tensor**, message, name=`None`)\n* `tf.dtypes.complex`(**real**, **imag**, name=`None`)\n* `tf.dtypes.saturate_cast`(**value**, dtype, name=`None`)\n* `tf.dynamic_partition`(**data**, **partitions**, num_partitions, name=`None`)\n* `tf.expand_dims`(**input**, axis, name=`None`)\n* `tf.gather_nd`(**params**, **indices**, batch_dims=`0`, name=`None`)\n* `tf.gather`(**params**, **indices**, validate_indices=`None`, axis=`None`, batch_dims=`0`, name=`None`)\n* `tf.image.adjust_brightness`(**image**, delta)\n* `tf.image.adjust_gamma`(**image**, gamma=`1`, gain=`1`)\n* `tf.image.convert_image_dtype`(**image**, dtype, saturate=`False`, name=`None`)\n* `tf.image.random_brightness`(**image**, max_delta, seed=`None`)\n* `tf.image.resize`(**images**, size, method=`'bilinear'`, preserve_aspect_ratio=`False`, antialias=`False`, name=`None`)\n* `tf.image.stateless_random_brightness`(**image**, max_delta, seed)\n* `tf.io.decode_base64`(**input**, name=`None`)\n* `tf.io.decode_compressed`(**bytes**, compression_type=`''`, name=`None`)\n* `tf.io.encode_base64`(**input**, pad=`False`, name=`None`)\n* `tf.linalg.matmul`(**a**, **b**, transpose_a=`False`, transpose_b=`False`, adjoint_a=`False`, adjoint_b=`False`, a_is_sparse=`False`, b_is_sparse=`False`, output_type=`None`, name=`None`)\n* `tf.math.abs`(**x**, name=`None`)\n* `tf.math.acos`(**x**, name=`None`)\n* `tf.math.acosh`(**x**, name=`None`)\n* `tf.math.add_n`(**inputs**, name=`None`)\n* `tf.math.add`(**x**, **y**, name=`None`)\n* `tf.math.angle`(**input**, name=`None`)\n* `tf.math.asin`(**x**, name=`None`)\n* `tf.math.asinh`(**x**, name=`None`)\n* `tf.math.atan2`(**y**, **x**, name=`None`)\n* `tf.math.atan`(**x**, name=`None`)\n* `tf.math.atanh`(**x**, name=`None`)\n* `tf.math.bessel_i0`(**x**, name=`None`)\n* `tf.math.bessel_i0e`(**x**, name=`None`)\n* `tf.math.bessel_i1`(**x**, name=`None`)\n* `tf.math.bessel_i1e`(**x**, name=`None`)\n* `tf.math.ceil`(**x**, name=`None`)\n* `tf.math.conj`(**x**, name=`None`)\n* `tf.math.cos`(**x**, name=`None`)\n* `tf.math.cosh`(**x**, name=`None`)\n* `tf.math.digamma`(**x**, name=`None`)\n* `tf.math.divide_no_nan`(**x**, **y**, name=`None`)\n* `tf.math.divide`(**x**, **y**, name=`None`)\n* `tf.math.equal`(**x**, **y**, name=`None`)\n* `tf.math.erf`(**x**, name=`None`)\n* `tf.math.erfc`(**x**, name=`None`)\n* `tf.math.erfcinv`(**x**, name=`None`)\n* `tf.math.erfinv`(**x**, name=`None`)\n* `tf.math.exp`(**x**, name=`None`)\n* `tf.math.expm1`(**x**, name=`None`)\n* `tf.math.floor`(**x**, name=`None`)\n* `tf.math.floordiv`(**x**, **y**, name=`None`)\n* `tf.math.floormod`(**x**, **y**, name=`None`)\n* `tf.math.greater_equal`(**x**, **y**, name=`None`)\n* `tf.math.greater`(**x**, **y**, name=`None`)\n* `tf.math.imag`(**input**, name=`None`)\n* `tf.math.is_finite`(**x**, name=`None`)\n* `tf.math.is_inf`(**x**, name=`None`)\n* `tf.math.is_nan`(**x**, name=`None`)\n* `tf.math.less_equal`(**x**, **y**, name=`None`)\n* `tf.math.less`(**x**, **y**, name=`None`)\n* `tf.math.lgamma`(**x**, name=`None`)\n* `tf.math.log1p`(**x**, name=`None`)\n* `tf.math.log_sigmoid`(**x**, name=`None`)\n* `tf.math.log`(**x**, name=`None`)\n* `tf.math.logical_and`(**x**, **y**, name=`None`)\n* `tf.math.logical_not`(**x**, name=`None`)\n* `tf.math.logical_or`(**x**, **y**, name=`None`)\n* `tf.math.logical_xor`(**x**, **y**, name=`'LogicalXor'`)\n* `tf.math.maximum`(**x**, **y**, name=`None`)\n* `tf.math.minimum`(**x**, **y**, name=`None`)\n* `tf.math.multiply_no_nan`(**x**, **y**, name=`None`)\n* `tf.math.multiply`(**x**, **y**, name=`None`)\n* `tf.math.ndtri`(**x**, name=`None`)\n* `tf.math.negative`(**x**, name=`None`)\n* `tf.math.nextafter`(**x1**, x2, name=`None`)\n* `tf.math.not_equal`(**x**, **y**, name=`None`)\n* `tf.math.pow`(**x**, **y**, name=`None`)\n* `tf.math.real`(**input**, name=`None`)\n* `tf.math.reciprocal_no_nan`(**x**, name=`None`)\n* `tf.math.reciprocal`(**x**, name=`None`)\n* `tf.math.reduce_all`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_any`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_max`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_mean`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_min`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_prod`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_std`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_sum`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.reduce_variance`(**input_tensor**, axis=`None`, keepdims=`False`, name=`None`)\n* `tf.math.rint`(**x**, name=`None`)\n* `tf.math.round`(**x**, name=`None`)\n* `tf.math.rsqrt`(**x**, name=`None`)\n* `tf.math.scalar_mul`(**scalar**, **x**, name=`None`)\n* `tf.math.sigmoid`(**x**, name=`None`)\n* `tf.math.sign`(**x**, name=`None`)\n* `tf.math.sin`(**x**, name=`None`)\n* `tf.math.sinh`(**x**, name=`None`)\n* `tf.math.softplus`(**features**, name=`None`)\n* `tf.math.special.bessel_j0`(**x**, name=`None`)\n* `tf.math.special.bessel_j1`(**x**, name=`None`)\n* `tf.math.special.bessel_k0`(**x**, name=`None`)\n* `tf.math.special.bessel_k0e`(**x**, name=`None`)\n* `tf.math.special.bessel_k1`(**x**, name=`None`)\n* `tf.math.special.bessel_k1e`(**x**, name=`None`)\n* `tf.math.special.bessel_y0`(**x**, name=`None`)\n* `tf.math.special.bessel_y1`(**x**, name=`None`)\n* `tf.math.special.dawsn`(**x**, name=`None`)\n* `tf.math.special.expint`(**x**, name=`None`)\n* `tf.math.special.fresnel_cos`(**x**, name=`None`)\n* `tf.math.special.fresnel_sin`(**x**, name=`None`)\n* `tf.math.special.spence`(**x**, name=`None`)\n* `tf.math.sqrt`(**x**, name=`None`)\n* `tf.math.square`(**x**, name=`None`)\n* `tf.math.squared_difference`(**x**, **y**, name=`None`)\n* `tf.math.subtract`(**x**, **y**, name=`None`)\n* `tf.math.tan`(**x**, name=`None`)\n* `tf.math.tanh`(**x**, name=`None`)\n* `tf.math.truediv`(**x**, **y**, name=`None`)\n* `tf.math.unsorted_segment_max`(**data**, **segment_ids**, num_segments, name=`None`)\n* `tf.math.unsorted_segment_mean`(**data**, **segment_ids**, num_segments, name=`None`)\n* `tf.math.unsorted_segment_min`(**data**, **segment_ids**, num_segments, name=`None`)\n* `tf.math.unsorted_segment_prod`(**data**, **segment_ids**, num_segments, name=`None`)\n* `tf.math.unsorted_segment_sqrt_n`(**data**, **segment_ids**, num_segments, name=`None`)\n* `tf.math.unsorted_segment_sum`(**data**, **segment_ids**, num_segments, name=`None`)\n* `tf.math.xdivy`(**x**, **y**, name=`None`)\n* `tf.math.xlog1py`(**x**, **y**, name=`None`)\n* `tf.math.xlogy`(**x**, **y**, name=`None`)\n* `tf.math.zeta`(**x**, **q**, name=`None`)\n* `tf.nn.dropout`(**x**, rate, noise_shape=`None`, seed=`None`, name=`None`)\n* `tf.nn.elu`(**features**, name=`None`)\n* `tf.nn.gelu`(**features**, approximate=`False`, name=`None`)\n* `tf.nn.leaky_relu`(**features**, alpha=`0.2`, name=`None`)\n* `tf.nn.relu6`(**features**, name=`None`)\n* `tf.nn.relu`(**features**, name=`None`)\n* `tf.nn.selu`(**features**, name=`None`)\n* `tf.nn.sigmoid_cross_entropy_with_logits`(**labels**=`None`, **logits**=`None`, name=`None`)\n* `tf.nn.silu`(**features**, beta=`1.0`)\n* `tf.nn.softmax`(**logits**, axis=`None`, name=`None`)\n* `tf.nn.softsign`(**features**, name=`None`)\n* `tf.one_hot`(**indices**, depth, on_value=`None`, off_value=`None`, axis=`None`, dtype=`None`, name=`None`)\n* `tf.ones_like`(**input**, dtype=`None`, name=`None`)\n* `tf.print`(***inputs**, **kwargs)\n* `tf.rank`(**input**, name=`None`)\n* `tf.realdiv`(**x**, **y**, name=`None`)\n* `tf.reshape`(**tensor**, **shape**, name=`None`)\n* `tf.reverse`(**tensor**, axis, name=`None`)\n* `tf.size`(**input**, out_type=`tf.int32`, name=`None`)\n* `tf.split`(**value**, num_or_size_splits, axis=`0`, num=`None`, name=`'split'`)\n* `tf.squeeze`(**input**, axis=`None`, name=`None`)\n* `tf.stack`(**values**, axis=`0`, name=`'stack'`)\n* `tf.strings.as_string`(**input**, precision=`-1`, scientific=`False`, shortest=`False`, width=`-1`, fill=`''`, name=`None`)\n* `tf.strings.format`(**template**, **inputs**, placeholder=`'{}'`, summarize=`3`, name=`None`)\n* `tf.strings.join`(**inputs**, separator=`''`, name=`None`)\n* `tf.strings.length`(**input**, unit=`'BYTE'`, name=`None`)\n* `tf.strings.lower`(**input**, encoding=`''`, name=`None`)\n* `tf.strings.reduce_join`(**inputs**, axis=`None`, keepdims=`False`, separator=`''`, name=`None`)\n* `tf.strings.regex_full_match`(**input**, pattern, name=`None`)\n* `tf.strings.regex_replace`(**input**, pattern, rewrite, replace_global=`True`, name=`None`)\n* `tf.strings.strip`(**input**, name=`None`)\n* `tf.strings.substr`(**input**, pos, len, unit=`'BYTE'`, name=`None`)\n* `tf.strings.to_hash_bucket_fast`(**input**, num_buckets, name=`None`)\n* `tf.strings.to_hash_bucket_strong`(**input**, num_buckets, key, name=`None`)\n* `tf.strings.to_hash_bucket`(**input**, num_buckets, name=`None`)\n* `tf.strings.to_number`(**input**, out_type=`tf.float32`, name=`None`)\n* `tf.strings.unicode_script`(**input**, name=`None`)\n* `tf.strings.unicode_transcode`(**input**, input_encoding, output_encoding, errors=`'replace'`, replacement_char=`65533`, replace_control_characters=`False`, name=`None`)\n* `tf.strings.upper`(**input**, encoding=`''`, name=`None`)\n* `tf.tile`(**input**, multiples, name=`None`)\n* `tf.truncatediv`(**x**, **y**, name=`None`)\n* `tf.truncatemod`(**x**, **y**, name=`None`)\n* `tf.where`(**condition**, **x**=`None`, **y**=`None`, name=`None`)\n* `tf.zeros_like`(**input**, dtype=`None`, name=`None`)n\n"],["tf.RaggedTensor","description: Represents a ragged tensor.",!1,`Represents a ragged tensor.
+
+ A \`RaggedTensor\` is a tensor with one or more *ragged dimensions*, which are
+ dimensions whose slices may have different lengths. For example, the inner
+ (column) dimension of \`rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []]\` is ragged,
+ since the column slices (\`rt[0, :]\`, ..., \`rt[4, :]\`) have different lengths.
+ Dimensions whose slices all have the same length are called *uniform
+ dimensions*. The outermost dimension of a \`RaggedTensor\` is always uniform,
+ since it consists of a single slice (and so there is no possibility for
+ differing slice lengths).
+
+ The total number of dimensions in a \`RaggedTensor\` is called its *rank*,
+ and the number of ragged dimensions in a \`RaggedTensor\` is called its
+ *ragged-rank*. A \`RaggedTensor\`'s ragged-rank is fixed at graph creation
+ time: it can't depend on the runtime values of \`Tensor\`s, and can't vary
+ dynamically for different session runs.
+
+ Note that the \`__init__\` constructor is private. Please use one of the
+ following methods to construct a \`RaggedTensor\`:
+
+ * \`tf.RaggedTensor.from_row_lengths\`
+ * \`tf.RaggedTensor.from_value_rowids\`
+ * \`tf.RaggedTensor.from_row_splits\`
+ * \`tf.RaggedTensor.from_row_starts\`
+ * \`tf.RaggedTensor.from_row_limits\`
+ * \`tf.RaggedTensor.from_nested_row_splits\`
+ * \`tf.RaggedTensor.from_nested_row_lengths\`
+ * \`tf.RaggedTensor.from_nested_value_rowids\`
+
+ ### Potentially Ragged Tensors
+
+ Many ops support both \`Tensor\`s and \`RaggedTensor\`s
+ (see [tf.ragged](https://www.tensorflow.org/api_docs/python/tf/ragged) for a
+ full listing). The term "potentially ragged tensor" may be used to refer to a
+ tensor that might be either a \`Tensor\` or a \`RaggedTensor\`. The ragged-rank
+ of a \`Tensor\` is zero.
+
+ ### Documenting RaggedTensor Shapes
+
+ When documenting the shape of a RaggedTensor, ragged dimensions can be
+ indicated by enclosing them in parentheses. For example, the shape of
+ a 3-D \`RaggedTensor\` that stores the fixed-size word embedding for each
+ word in a sentence, for each sentence in a batch, could be written as
+ \`[num_sentences, (num_words), embedding_size]\`. The parentheses around
+ \`(num_words)\` indicate that dimension is ragged, and that the length
+ of each element list in that dimension may vary for each item.
+
+ ### Component Tensors
+
+ Internally, a \`RaggedTensor\` consists of a concatenated list of values that
+ are partitioned into variable-length rows. In particular, each \`RaggedTensor\`
+ consists of:
+
+ * A \`values\` tensor, which concatenates the variable-length rows into a
+ flattened list. For example, the \`values\` tensor for
+ \`[[3, 1, 4, 1], [], [5, 9, 2], [6], []]\` is \`[3, 1, 4, 1, 5, 9, 2, 6]\`.
+
+ * A \`row_splits\` vector, which indicates how those flattened values are
+ divided into rows. In particular, the values for row \`rt[i]\` are stored
+ in the slice \`rt.values[rt.row_splits[i]:rt.row_splits[i+1]]\`.
+
+ Example:
+
+ >>> print(tf.RaggedTensor.from_row_splits(
+ ... values=[3, 1, 4, 1, 5, 9, 2, 6],
+ ... row_splits=[0, 4, 4, 7, 8, 8]))
+ tf.RaggedTensor.',!1,"Type specification for a `tf.RaggedTensor`."],["tf.random","description: Public API for tf.random namespace.",!0,`Public API for tf.random namespace.
+`],["tf.random_index_shuffle","description: Outputs the position of value in a permutation of [0, ..., max_index].",!1,"Outputs the position of `value` in a permutation of [0, ..., max_index].\n\n Output values are a bijection of the `index` for any combination and `seed` and `max_index`.\n\n If multiple inputs are vectors (matrix in case of seed) then the size of the\n first dimension must match.\n\n The outputs are deterministic.\n\n Args:\n index: A `Tensor`. Must be one of the following types: `int32`, `uint32`, `int64`, `uint64`.\n A scalar tensor or a vector of dtype `dtype`. The index (or indices) to be shuffled. Must be within [0, max_index].\n seed: A `Tensor`. Must be one of the following types: `int32`, `uint32`, `int64`, `uint64`.\n A tensor of dtype `Tseed` and shape [3] or [n, 3]. The random seed.\n max_index: A `Tensor`. Must have the same type as `index`.\n A scalar tensor or vector of dtype `dtype`. The upper bound(s) of the interval (inclusive).\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor`. Has the same type as `index`.\n "],["tf.random_normal_initializer","description: Initializer that generates tensors with a normal distribution.",!1,`Initializer that generates tensors with a normal distribution.
+
+ Initializers allow you to pre-specify an initialization strategy, encoded in
+ the Initializer object, without knowing the shape and dtype of the variable
+ being initialized.
+
+ Examples:
+
+ >>> def make_variables(k, initializer):
+ ... return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
+ ... tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
+ >>> v1, v2 = make_variables(3,
+ ... tf.random_normal_initializer(mean=1., stddev=2.))
+ >>> v1
+
+  +
+
+
+ In Python, this scatter operation would look like this:
+
+ \`\`\`python
+ indices = tf.constant([[4], [3], [1], [7]])
+ updates = tf.constant([9, 10, 11, 12])
+ shape = tf.constant([8])
+ scatter = tf.scatter_nd(indices, updates, shape)
+ print(scatter)
+ \`\`\`
+
+ The resulting tensor would look like this:
+
+ [0, 11, 0, 10, 9, 0, 0, 12]
+
+ You can also insert entire slices of a higher rank tensor all at once. For
+ example, you can insert two slices in the first dimension of a rank-3 tensor
+ with two matrices of new values.
+
+
+
+  +
+
+
+ In Python, this scatter operation would look like this:
+
+ \`\`\`python
+ indices = tf.constant([[0], [2]])
+ updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
+ [7, 7, 7, 7], [8, 8, 8, 8]],
+ [[5, 5, 5, 5], [6, 6, 6, 6],
+ [7, 7, 7, 7], [8, 8, 8, 8]]])
+ shape = tf.constant([4, 4, 4])
+ scatter = tf.scatter_nd(indices, updates, shape)
+ print(scatter)
+ \`\`\`
+
+ The resulting tensor would look like this:
+
+ [[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
+ [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]],
+ [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
+ [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]
+
+ Note that on CPU, if an out of bound index is found, an error is returned.
+ On GPU, if an out of bound index is found, the index is ignored.
+
+ Args:
+ indices: A \`Tensor\`. Must be one of the following types: \`int16\`, \`int32\`, \`int64\`.
+ Tensor of indices.
+ updates: A \`Tensor\`. Values to scatter into the output tensor.
+ shape: A \`Tensor\`. Must have the same type as \`indices\`.
+ 1-D. The shape of the output tensor.
+ name: A name for the operation (optional).
+
+ Returns:
+ A \`Tensor\`. Has the same type as \`updates\`.
+ `],["tf.searchsorted","description: Searches for where a value would go in a sorted sequence.",!1,`Searches for where a value would go in a sorted sequence.
+
+ This is not a method for checking containment (like python \`in\`).
+
+ The typical use case for this operation is "binning", "bucketing", or
+ "discretizing". The \`values\` are assigned to bucket-indices based on the
+ **edges** listed in \`sorted_sequence\`. This operation
+ returns the bucket-index for each value.
+
+ >>> edges = [-1, 3.3, 9.1, 10.0]
+ >>> values = [0.0, 4.1, 12.0]
+ >>> tf.searchsorted(edges, values).numpy()
+ array([1, 2, 4], dtype=int32)
+
+ The \`side\` argument controls which index is returned if a value lands exactly
+ on an edge:
+
+ >>> seq = [0, 3, 9, 10, 10]
+ >>> values = [0, 4, 10]
+ >>> tf.searchsorted(seq, values).numpy()
+ array([0, 2, 3], dtype=int32)
+ >>> tf.searchsorted(seq, values, side="right").numpy()
+ array([1, 2, 5], dtype=int32)
+
+ The \`axis\` is not settable for this operation. It always operates on the
+ innermost dimension (\`axis=-1\`). The operation will accept any number of
+ outer dimensions. Here it is applied to the rows of a matrix:
+
+ >>> sorted_sequence = [[0., 3., 8., 9., 10.],
+ ... [1., 2., 3., 4., 5.]]
+ >>> values = [[9.8, 2.1, 4.3],
+ ... [0.1, 6.6, 4.5, ]]
+ >>> tf.searchsorted(sorted_sequence, values).numpy()
+ array([[4, 1, 2],
+ [0, 5, 4]], dtype=int32)
+
+ Note: This operation assumes that \`sorted_sequence\` **is sorted** along the
+ innermost axis, maybe using \`tf.sort(..., axis=-1)\`. **If the sequence is not
+ sorted no error is raised** and the content of the returned tensor is not well
+ defined.
+
+ Args:
+ sorted_sequence: N-D \`Tensor\` containing a sorted sequence.
+ values: N-D \`Tensor\` containing the search values.
+ side: 'left' or 'right'; 'left' corresponds to lower_bound and 'right' to
+ upper_bound.
+ out_type: The output type (\`int32\` or \`int64\`). Default is \`tf.int32\`.
+ name: Optional name for the operation.
+
+ Returns:
+ An N-D \`Tensor\` the size of \`values\` containing the result of applying
+ either lower_bound or upper_bound (depending on side) to each value. The
+ result is not a global index to the entire \`Tensor\`, but the index in the
+ last dimension.
+
+ Raises:
+ ValueError: If the last dimension of \`sorted_sequence >= 2^31-1\` elements.
+ If the total size of \`values\` exceeds \`2^31 - 1\` elements.
+ If the first \`N-1\` dimensions of the two tensors don't match.
+ `],["tf.sequence_mask","description: Returns a mask tensor representing the first N positions of each cell.",!1,`Returns a mask tensor representing the first N positions of each cell.
+
+ If \`lengths\` has shape \`[d_1, d_2, ..., d_n]\` the resulting tensor \`mask\` has
+ dtype \`dtype\` and shape \`[d_1, d_2, ..., d_n, maxlen]\`, with
+
+ \`\`\`
+ mask[i_1, i_2, ..., i_n, j] = (j < lengths[i_1, i_2, ..., i_n])
+ \`\`\`
+
+ Examples:
+
+ \`\`\`python
+ tf.sequence_mask([1, 3, 2], 5) # [[True, False, False, False, False],
+ # [True, True, True, False, False],
+ # [True, True, False, False, False]]
+
+ tf.sequence_mask([[1, 3],[2,0]]) # [[[True, False, False],
+ # [True, True, True]],
+ # [[True, True, False],
+ # [False, False, False]]]
+ \`\`\`
+
+ Args:
+ lengths: integer tensor, all its values <= maxlen.
+ maxlen: scalar integer tensor, size of last dimension of returned tensor.
+ Default is the maximum value in \`lengths\`.
+ dtype: output type of the resulting tensor.
+ name: name of the op.
+
+ Returns:
+ A mask tensor of shape \`lengths.shape + (maxlen,)\`, cast to specified dtype.
+ Raises:
+ ValueError: if \`maxlen\` is not a scalar.
+ `],["tf.sets","description: Tensorflow set operations.",!0,`Tensorflow set operations.
+`],["tf.shape","description: Returns a tensor containing the shape of the input tensor.",!1,`Returns a tensor containing the shape of the input tensor.
+
+ See also \`tf.size\`, \`tf.rank\`.
+
+ \`tf.shape\` returns a 1-D integer tensor representing the shape of \`input\`.
+ For a scalar input, the tensor returned has a shape of (0,) and its value is
+ the empty vector (i.e. []).
+
+ For example:
+
+ >>> tf.shape(1.)
+
+ tf.sparse.SparseTensor.',!1,"Type specification for a `tf.sparse.SparseTensor`."],["tf.split","description: Splits a tensor value into a list of sub tensors.",!1,"Splits a tensor `value` into a list of sub tensors.\n\n See also `tf.unstack`.\n\n If `num_or_size_splits` is an `int`, then it splits `value` along the\n dimension `axis` into `num_or_size_splits` smaller tensors. This requires that\n `value.shape[axis]` is divisible by `num_or_size_splits`.\n\n If `num_or_size_splits` is a 1-D Tensor (or list), then `value` is split into\n `len(num_or_size_splits)` elements. The shape of the `i`-th\n element has the same size as the `value` except along dimension `axis` where\n the size is `num_or_size_splits[i]`.\n\n For example:\n\n >>> x = tf.Variable(tf.random.uniform([5, 30], -1, 1))\n >>>\n >>> # Split `x` into 3 tensors along dimension 1\n >>> s0, s1, s2 = tf.split(x, num_or_size_splits=3, axis=1)\n >>> tf.shape(s0).numpy()\n array([ 5, 10], dtype=int32)\n >>>\n >>> # Split `x` into 3 tensors with sizes [4, 15, 11] along dimension 1\n >>> split0, split1, split2 = tf.split(x, [4, 15, 11], 1)\n >>> tf.shape(split0).numpy()\n array([5, 4], dtype=int32)\n >>> tf.shape(split1).numpy()\n array([ 5, 15], dtype=int32)\n >>> tf.shape(split2).numpy()\n array([ 5, 11], dtype=int32)\n\n Args:\n value: The `Tensor` to split.\n num_or_size_splits: Either an `int` indicating the number of splits\n along `axis` or a 1-D integer `Tensor` or Python list containing the sizes\n of each output tensor along `axis`. If an `int`, then it must evenly\n divide `value.shape[axis]`; otherwise the sum of sizes along the split\n axis must match that of the `value`.\n axis: An `int` or scalar `int32` `Tensor`. The dimension along which\n to split. Must be in the range `[-rank(value), rank(value))`. Defaults to\n 0.\n num: Optional, an `int`, used to specify the number of outputs when it\n cannot be inferred from the shape of `size_splits`.\n name: A name for the operation (optional).\n\n Returns:\n if `num_or_size_splits` is an `int` returns a list of\n `num_or_size_splits` `Tensor` objects; if `num_or_size_splits` is a 1-D\n list or 1-D `Tensor` returns `num_or_size_splits.get_shape[0]`\n `Tensor` objects resulting from splitting `value`.\n\n Raises:\n ValueError: If `num` is unspecified and cannot be inferred.\n ValueError: If `num_or_size_splits` is a scalar `Tensor`.\n "],["tf.squeeze","description: Removes dimensions of size 1 from the shape of a tensor.",!1,"Removes dimensions of size 1 from the shape of a tensor.\n\n Given a tensor `input`, this operation returns a tensor of the same type with\n all dimensions of size 1 removed. If you don't want to remove all size 1\n dimensions, you can remove specific size 1 dimensions by specifying\n `axis`.\n\n For example:\n\n ```python\n # 't' is a tensor of shape [1, 2, 1, 3, 1, 1]\n tf.shape(tf.squeeze(t)) # [2, 3]\n ```\n\n Or, to remove specific size 1 dimensions:\n\n ```python\n # 't' is a tensor of shape [1, 2, 1, 3, 1, 1]\n tf.shape(tf.squeeze(t, [2, 4])) # [1, 2, 3, 1]\n ```\n\n Unlike the older op `tf.compat.v1.squeeze`, this op does not accept a\n deprecated `squeeze_dims` argument.\n\n Note: if `input` is a `tf.RaggedTensor`, then this operation takes `O(N)`\n time, where `N` is the number of elements in the squeezed dimensions.\n\n Args:\n input: A `Tensor`. The `input` to squeeze.\n axis: An optional list of `ints`. Defaults to `[]`. If specified, only\n squeezes the dimensions listed. The dimension index starts at 0. It is an\n error to squeeze a dimension that is not 1. Must be in the range\n `[-rank(input), rank(input))`. Must be specified if `input` is a\n `RaggedTensor`.\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor`. Has the same type as `input`.\n Contains the same data as `input`, but has one or more dimensions of\n size 1 removed.\n\n Raises:\n ValueError: The input cannot be converted to a tensor, or the specified\n axis cannot be squeezed.\n "],["tf.stack","description: Stacks a list of rank-R tensors into one rank-(R+1) tensor.",!1,"Stacks a list of rank-`R` tensors into one rank-`(R+1)` tensor.\n\n See also `tf.concat`, `tf.tile`, `tf.repeat`.\n\n Packs the list of tensors in `values` into a tensor with rank one higher than\n each tensor in `values`, by packing them along the `axis` dimension.\n Given a list of length `N` of tensors of shape `(A, B, C)`;\n\n if `axis == 0` then the `output` tensor will have the shape `(N, A, B, C)`.\n if `axis == 1` then the `output` tensor will have the shape `(A, N, B, C)`.\n Etc.\n\n For example:\n\n >>> x = tf.constant([1, 4])\n >>> y = tf.constant([2, 5])\n >>> z = tf.constant([3, 6])\n >>> tf.stack([x, y, z])\n tf.Tensor represents a multidimensional array of elements.',!1,`A \`tf.Tensor\` represents a multidimensional array of elements.
+
+ All elements are of a single known data type.
+
+ When writing a TensorFlow program, the main object that is
+ manipulated and passed around is the \`tf.Tensor\`.
+
+ A \`tf.Tensor\` has the following properties:
+
+ * a single data type (float32, int32, or string, for example)
+ * a shape
+
+ TensorFlow supports eager execution and graph execution. In eager
+ execution, operations are evaluated immediately. In graph
+ execution, a computational graph is constructed for later
+ evaluation.
+
+ TensorFlow defaults to eager execution. In the example below, the
+ matrix multiplication results are calculated immediately.
+
+ >>> # Compute some values using a Tensor
+ >>> c = tf.constant([[1.0, 2.0], [3.0, 4.0]])
+ >>> d = tf.constant([[1.0, 1.0], [0.0, 1.0]])
+ >>> e = tf.matmul(c, d)
+ >>> print(e)
+ tf.Tensor(
+ [[1. 3.]
+ [3. 7.]], shape=(2, 2), dtype=float32)
+
+ Note that during eager execution, you may discover your \`Tensors\` are actually
+ of type \`EagerTensor\`. This is an internal detail, but it does give you
+ access to a useful function, \`numpy\`:
+
+ >>> type(e)
+ tf.TensorArray.',!1,"Type specification for a `tf.TensorArray`."],["tf.tensordot","description: Tensor contraction of a and b along specified axes and outer product.",!1,"Tensor contraction of a and b along specified axes and outer product.\n\n Tensordot (also known as tensor contraction) sums the product of elements\n from `a` and `b` over the indices specified by `axes`.\n\n This operation corresponds to `numpy.tensordot(a, b, axes)`.\n\n Example 1: When `a` and `b` are matrices (order 2), the case `axes=1`\n is equivalent to matrix multiplication.\n\n Example 2: When `a` and `b` are matrices (order 2), the case\n `axes = [[1], [0]]` is equivalent to matrix multiplication.\n\n Example 3: When `a` and `b` are matrices (order 2), the case `axes=0` gives\n the outer product, a tensor of order 4.\n\n Example 4: Suppose that \\\\(a_{ijk}\\\\) and \\\\(b_{lmn}\\\\) represent two\n tensors of order 3. Then, `contract(a, b, [[0], [2]])` is the order 4 tensor\n \\\\(c_{jklm}\\\\) whose entry\n corresponding to the indices \\\\((j,k,l,m)\\\\) is given by:\n\n \\\\( c_{jklm} = \\sum_i a_{ijk} b_{lmi} \\\\).\n\n In general, `order(c) = order(a) + order(b) - 2*len(axes[0])`.\n\n Args:\n a: `Tensor` of type `float32` or `float64`.\n b: `Tensor` with the same type as `a`.\n axes: Either a scalar `N`, or a list or an `int32` `Tensor` of shape [2, k].\n If axes is a scalar, sum over the last N axes of a and the first N axes of\n b in order. If axes is a list or `Tensor` the first and second row contain\n the set of unique integers specifying axes along which the contraction is\n computed, for `a` and `b`, respectively. The number of axes for `a` and\n `b` must be equal. If `axes=0`, computes the outer product between `a` and\n `b`.\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor` with the same type as `a`.\n\n Raises:\n ValueError: If the shapes of `a`, `b`, and `axes` are incompatible.\n IndexError: If the values in axes exceed the rank of the corresponding\n tensor.\n "],["tf.TensorShape","description: Represents the shape of a Tensor.",!1,'Represents the shape of a `Tensor`.\n\n A `TensorShape` represents a possibly-partial shape specification for a\n `Tensor`. It may be one of the following:\n\n * *Fully-known shape:* has a known number of dimensions and a known size\n for each dimension. e.g. `TensorShape([16, 256])`\n * *Partially-known shape:* has a known number of dimensions, and an unknown\n size for one or more dimension. e.g. `TensorShape([None, 256])`\n * *Unknown shape:* has an unknown number of dimensions, and an unknown\n size in all dimensions. e.g. `TensorShape(None)`\n\n If a tensor is produced by an operation of type `"Foo"`, its shape\n may be inferred if there is a registered shape function for\n `"Foo"`. See [Shape\n functions](https://www.tensorflow.org/guide/create_op#shape_functions_in_c)\n for details of shape functions and how to register them. Alternatively,\n you may set the shape explicitly using `tf.Tensor.set_shape`.\n '],["tf.TensorSpec","description: Describes a tf.Tensor.",!1,`Describes a tf.Tensor.
+
+ Metadata for describing the \`tf.Tensor\` objects accepted or returned
+ by some TensorFlow APIs.
+ `],["tf.tensor_scatter_nd_add","description: Adds sparse updates to an existing tensor according to indices.",!1,`Adds sparse \`updates\` to an existing tensor according to \`indices\`.
+
+ This operation creates a new tensor by adding sparse \`updates\` to the passed
+ in \`tensor\`.
+ This operation is very similar to \`tf.compat.v1.scatter_nd_add\`, except that the
+ updates are added onto an existing tensor (as opposed to a variable). If the
+ memory for the existing tensor cannot be re-used, a copy is made and updated.
+
+ \`indices\` is an integer tensor containing indices into a new tensor of shape
+ \`tensor.shape\`. The last dimension of \`indices\` can be at most the rank of
+ \`tensor.shape\`:
+
+ \`\`\`
+ indices.shape[-1] <= tensor.shape.rank
+ \`\`\`
+
+ The last dimension of \`indices\` corresponds to indices into elements
+ (if \`indices.shape[-1] = tensor.shape.rank\`) or slices
+ (if \`indices.shape[-1] < tensor.shape.rank\`) along dimension
+ \`indices.shape[-1]\` of \`tensor.shape\`. \`updates\` is a tensor with shape
+
+ \`\`\`
+ indices.shape[:-1] + tensor.shape[indices.shape[-1]:]
+ \`\`\`
+
+ The simplest form of \`tensor_scatter_nd_add\` is to add individual elements to a
+ tensor by index. For example, say we want to add 4 elements in a rank-1
+ tensor with 8 elements.
+
+ In Python, this scatter add operation would look like this:
+
+ >>> indices = tf.constant([[4], [3], [1], [7]])
+ >>> updates = tf.constant([9, 10, 11, 12])
+ >>> tensor = tf.ones([8], dtype=tf.int32)
+ >>> updated = tf.tensor_scatter_nd_add(tensor, indices, updates)
+ >>> updated
+ ',!1,"TODO: add doc.\n\n Args:\n tensor: A `Tensor`. Tensor to update.\n indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.\n Index tensor.\n updates: A `Tensor`. Must have the same type as `tensor`.\n Updates to scatter into output.\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor`. Has the same type as `tensor`.\n "],["tf.tensor_scatter_nd_sub","description: Subtracts sparse updates from an existing tensor according to indices.",!1,`Subtracts sparse \`updates\` from an existing tensor according to \`indices\`.
+
+ This operation creates a new tensor by subtracting sparse \`updates\` from the
+ passed in \`tensor\`.
+ This operation is very similar to \`tf.scatter_nd_sub\`, except that the updates
+ are subtracted from an existing tensor (as opposed to a variable). If the memory
+ for the existing tensor cannot be re-used, a copy is made and updated.
+
+ \`indices\` is an integer tensor containing indices into a new tensor of shape
+ \`shape\`. The last dimension of \`indices\` can be at most the rank of \`shape\`:
+
+ indices.shape[-1] <= shape.rank
+
+ The last dimension of \`indices\` corresponds to indices into elements
+ (if \`indices.shape[-1] = shape.rank\`) or slices
+ (if \`indices.shape[-1] < shape.rank\`) along dimension \`indices.shape[-1]\` of
+ \`shape\`. \`updates\` is a tensor with shape
+
+ indices.shape[:-1] + shape[indices.shape[-1]:]
+
+ The simplest form of tensor_scatter_sub is to subtract individual elements
+ from a tensor by index. For example, say we want to insert 4 scattered elements
+ in a rank-1 tensor with 8 elements.
+
+ In Python, this scatter subtract operation would look like this:
+
+ \`\`\`python
+ indices = tf.constant([[4], [3], [1], [7]])
+ updates = tf.constant([9, 10, 11, 12])
+ tensor = tf.ones([8], dtype=tf.int32)
+ updated = tf.tensor_scatter_nd_sub(tensor, indices, updates)
+ print(updated)
+ \`\`\`
+
+ The resulting tensor would look like this:
+
+ [1, -10, 1, -9, -8, 1, 1, -11]
+
+ We can also, insert entire slices of a higher rank tensor all at once. For
+ example, if we wanted to insert two slices in the first dimension of a
+ rank-3 tensor with two matrices of new values.
+
+ In Python, this scatter add operation would look like this:
+
+ \`\`\`python
+ indices = tf.constant([[0], [2]])
+ updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
+ [7, 7, 7, 7], [8, 8, 8, 8]],
+ [[5, 5, 5, 5], [6, 6, 6, 6],
+ [7, 7, 7, 7], [8, 8, 8, 8]]])
+ tensor = tf.ones([4, 4, 4],dtype=tf.int32)
+ updated = tf.tensor_scatter_nd_sub(tensor, indices, updates)
+ print(updated)
+ \`\`\`
+
+ The resulting tensor would look like this:
+
+ [[[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]],
+ [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]],
+ [[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]],
+ [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]]
+
+ Note that on CPU, if an out of bound index is found, an error is returned.
+ On GPU, if an out of bound index is found, the index is ignored.
+
+ Args:
+ tensor: A \`Tensor\`. Tensor to copy/update.
+ indices: A \`Tensor\`. Must be one of the following types: \`int32\`, \`int64\`.
+ Index tensor.
+ updates: A \`Tensor\`. Must have the same type as \`tensor\`.
+ Updates to scatter into output.
+ name: A name for the operation (optional).
+
+ Returns:
+ A \`Tensor\`. Has the same type as \`tensor\`.
+ `],["tf.tensor_scatter_nd_update","description: Scatter updates into an existing tensor according to indices.",!1,`Scatter \`updates\` into an existing tensor according to \`indices\`.
+
+ This operation creates a new tensor by applying sparse \`updates\` to the
+ input \`tensor\`. This is similar to an index assignment.
+
+ \`\`\`
+ # Not implemented: tensors cannot be updated inplace.
+ tensor[indices] = updates
+ \`\`\`
+
+ If an out of bound index is found on CPU, an error is returned.
+
+ > **WARNING**: There are some GPU specific semantics for this operation.
+ >
+ > - If an out of bound index is found, the index is ignored.
+ > - The order in which updates are applied is nondeterministic, so the output
+ > will be nondeterministic if \`indices\` contains duplicates.
+
+ This operation is very similar to \`tf.scatter_nd\`, except that the updates are
+ scattered onto an existing tensor (as opposed to a zero-tensor). If the memory
+ for the existing tensor cannot be re-used, a copy is made and updated.
+
+ In general:
+
+ * \`indices\` is an integer tensor - the indices to update in \`tensor\`.
+ * \`indices\` has **at least two** axes, the last axis is the depth of the
+ index vectors.
+ * For each index vector in \`indices\` there is a corresponding entry in
+ \`updates\`.
+ * If the length of the index vectors matches the rank of the \`tensor\`, then
+ the index vectors each point to scalars in \`tensor\` and each update is a
+ scalar.
+ * If the length of the index vectors is less than the rank of \`tensor\`, then
+ the index vectors each point to slices of \`tensor\` and shape of the updates
+ must match that slice.
+
+ Overall this leads to the following shape constraints:
+
+ \`\`\`
+ assert tf.rank(indices) >= 2
+ index_depth = indices.shape[-1]
+ batch_shape = indices.shape[:-1]
+ assert index_depth <= tf.rank(tensor)
+ outer_shape = tensor.shape[:index_depth]
+ inner_shape = tensor.shape[index_depth:]
+ assert updates.shape == batch_shape + inner_shape
+ \`\`\`
+
+ Typical usage is often much simpler than this general form, and it
+ can be better understood starting with simple examples:
+
+ ### Scalar updates
+
+ The simplest usage inserts scalar elements into a tensor by index.
+ In this case, the \`index_depth\` must equal the rank of the
+ input \`tensor\`, slice each column of \`indices\` is an index into an axis of the
+ input \`tensor\`.
+
+ In this simplest case the shape constraints are:
+
+ \`\`\`
+ num_updates, index_depth = indices.shape.as_list()
+ assert updates.shape == [num_updates]
+ assert index_depth == tf.rank(tensor)\`
+ \`\`\`
+
+ For example, to insert 4 scattered elements in a rank-1 tensor with
+ 8 elements.
+
+
+ >>> c = tf.constant([2,1], tf.int32)
+ >>> tf.tile(a, c)
+
+ >>> d = tf.constant([2,2], tf.int32)
+ >>> tf.tile(a, d)
+
+
+ Args:
+ input: A \`Tensor\`. 1-D or higher.
+ multiples: A \`Tensor\`. Must be one of the following types: \`int32\`, \`int64\`.
+ 1-D. Length must be the same as the number of dimensions in \`input\`
+ name: A name for the operation (optional).
+
+ Returns:
+ A \`Tensor\`. Has the same type as \`input\`.
+ `],["tf.timestamp","description: Provides the time since epoch in seconds.",!1,`Provides the time since epoch in seconds.
+
+ Returns the timestamp as a \`float64\` for seconds since the Unix epoch.
+
+ Note: the timestamp is computed when the op is executed, not when it is added
+ to the graph.
+
+ Args:
+ name: A name for the operation (optional).
+
+ Returns:
+ A \`Tensor\` of type \`float64\`.
+ `],["tf.tpu","description: Ops related to Tensor Processing Units.",!0,`Ops related to Tensor Processing Units.
+`],["tf.train","description: Support for training models.",!0,`Support for training models.
+
+See the [Training](https://tensorflow.org/api_guides/python/train) guide.
+
+`],["tf.transpose","description: Transposes a, where a is a Tensor.",!1,`Transposes \`a\`, where \`a\` is a Tensor.
+
+ Permutes the dimensions according to the value of \`perm\`.
+
+ The returned tensor's dimension \`i\` will correspond to the input dimension
+ \`perm[i]\`. If \`perm\` is not given, it is set to (n-1...0), where n is the rank
+ of the input tensor. Hence by default, this operation performs a regular
+ matrix transpose on 2-D input Tensors.
+
+ If conjugate is \`True\` and \`a.dtype\` is either \`complex64\` or \`complex128\`
+ then the values of \`a\` are conjugated and transposed.
+
+ @compatibility(numpy)
+ In \`numpy\` transposes are memory-efficient constant time operations as they
+ simply return a new view of the same data with adjusted \`strides\`.
+
+ TensorFlow does not support strides, so \`transpose\` returns a new tensor with
+ the items permuted.
+ @end_compatibility
+
+ For example:
+
+ >>> x = tf.constant([[1, 2, 3], [4, 5, 6]])
+ >>> tf.transpose(x)
+
+
+ Equivalently, you could call \`tf.transpose(x, perm=[1, 0])\`.
+
+ If \`x\` is complex, setting conjugate=True gives the conjugate transpose:
+
+ >>> x = tf.constant([[1 + 1j, 2 + 2j, 3 + 3j],
+ ... [4 + 4j, 5 + 5j, 6 + 6j]])
+ >>> tf.transpose(x, conjugate=True)
+
+
+ 'perm' is more useful for n-dimensional tensors where n > 2:
+
+ >>> x = tf.constant([[[ 1, 2, 3],
+ ... [ 4, 5, 6]],
+ ... [[ 7, 8, 9],
+ ... [10, 11, 12]]])
+
+ As above, simply calling \`tf.transpose\` will default to \`perm=[2,1,0]\`.
+
+ To take the transpose of the matrices in dimension-0 (such as when you are
+ transposing matrices where 0 is the batch dimension), you would set
+ \`perm=[0,2,1]\`.
+
+ >>> tf.transpose(x, perm=[0, 2, 1])
+
+
+ Note: This has a shorthand \`linalg.matrix_transpose\`):
+
+ Args:
+ a: A \`Tensor\`.
+ perm: A permutation of the dimensions of \`a\`. This should be a vector.
+ conjugate: Optional bool. Setting it to \`True\` is mathematically equivalent
+ to tf.math.conj(tf.transpose(input)).
+ name: A name for the operation (optional).
+
+ Returns:
+ A transposed \`Tensor\`.
+ `],["tf.truncatediv","description: Returns x / y element-wise for integer types.",!1,"Returns x / y element-wise for integer types.\n\n Truncation designates that negative numbers will round fractional quantities\n toward zero. I.e. -7 / 5 = -1. This matches C semantics but it is different\n than Python semantics. See `FloorDiv` for a division function that matches\n Python Semantics.\n\n *NOTE*: `truncatediv` supports broadcasting. More about broadcasting\n [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)\n\n Args:\n x: A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `uint32`, `uint64`, `int64`, `complex64`, `complex128`.\n y: A `Tensor`. Must have the same type as `x`.\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor`. Has the same type as `x`.\n "],["tf.truncatemod","description: Returns element-wise remainder of division. This emulates C semantics in that",!1,"Returns element-wise remainder of division. This emulates C semantics in that\n\n the result here is consistent with a truncating divide. E.g. `truncate(x / y) *\n y + truncate_mod(x, y) = x`.\n\n *NOTE*: `truncatemod` supports broadcasting. More about broadcasting\n [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)\n\n Args:\n x: A `Tensor`. Must be one of the following types: `int32`, `int64`, `bfloat16`, `half`, `float32`, `float64`.\n y: A `Tensor`. Must have the same type as `x`.\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor`. Has the same type as `x`.\n "],["tf.tuple","description: Groups tensors together.",!1,"Groups tensors together.\n\n The returned tensors have the same value as the input tensors, but they\n are computed only after all the input tensors have been computed.\n\n Note: *In TensorFlow 2 with eager and/or Autograph, you should not require\n this method, as ops execute in the expected order thanks to automatic control\n dependencies.* Only use `tf.tuple` when working with v1 `tf.Graph` code.\n\n See also `tf.group` and `tf.control_dependencies`.\n\n Args:\n tensors: A list of `Tensor`s or `IndexedSlices`, some entries can be `None`.\n control_inputs: List of additional ops to finish before returning.\n name: (optional) A name to use as a `name_scope` for the operation.\n\n Returns:\n Same as `tensors`.\n\n Raises:\n ValueError: If `tensors` does not contain any `Tensor` or `IndexedSlices`.\n TypeError: If `control_inputs` is not a list of `Operation` or `Tensor`\n objects.\n\n "],["tf.types","description: Public TensorFlow type definitions.",!0,`Public TensorFlow type definitions.
+
+For details, see
+https://github.com/tensorflow/community/blob/master/rfcs/20200211-tf-types.md.
+
+`],["tf.TypeSpec","description: Specifies a TensorFlow value type.",!1,`Specifies a TensorFlow value type.
+
+ A \`tf.TypeSpec\` provides metadata describing an object accepted or returned
+ by TensorFlow APIs. Concrete subclasses, such as \`tf.TensorSpec\` and
+ \`tf.RaggedTensorSpec\`, are used to describe different value types.
+
+ For example, \`tf.function\`'s \`input_signature\` argument accepts a list
+ (or nested structure) of \`TypeSpec\`s.
+
+ Creating new subclasses of \`TypeSpec\` (outside of TensorFlow core) is not
+ currently supported. In particular, we may make breaking changes to the
+ private methods and properties defined by this base class.
+
+ Example:
+
+ >>> spec = tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)
+ >>> @tf.function(input_signature=[spec])
+ ... def double(x):
+ ... return x * 2
+ >>> print(double(tf.ragged.constant([[1, 2], [3]])))
+
+ `],["tf.type_spec_from_value",'description: Returns a
+ >>> v.assign_add(0.5)
+
+
+ The \`shape\` argument to \`Variable\`'s constructor allows you to construct a
+ variable with a less defined shape than its \`initial_value\`:
+
+ >>> v = tf.Variable(1., shape=tf.TensorShape(None))
+ >>> v.assign([[1.]])
+ dtype=float32, numpy=array([[1.]], ...)>
+
+ Just like any \`Tensor\`, variables created with \`Variable()\` can be used as
+ inputs to operations. Additionally, all the operators overloaded for the
+ \`Tensor\` class are carried over to variables.
+
+ >>> w = tf.Variable([[1.], [2.]])
+ >>> x = tf.constant([[3., 4.]])
+ >>> tf.matmul(w, x)
+
+ >>> tf.sigmoid(w + x)
+
+
+ When building a machine learning model it is often convenient to distinguish
+ between variables holding trainable model parameters and other variables such
+ as a \`step\` variable used to count training steps. To make this easier, the
+ variable constructor supports a \`trainable=\`
+ parameter. \`tf.GradientTape\` watches trainable variables by default:
+
+ >>> with tf.GradientTape(persistent=True) as tape:
+ ... trainable = tf.Variable(1.)
+ ... non_trainable = tf.Variable(2., trainable=False)
+ ... x1 = trainable * 2.
+ ... x2 = non_trainable * 3.
+ >>> tape.gradient(x1, trainable)
+
+ >>> assert tape.gradient(x2, non_trainable) is None # Unwatched
+
+ Variables are automatically tracked when assigned to attributes of types
+ inheriting from \`tf.Module\`.
+
+ >>> m = tf.Module()
+ >>> m.v = tf.Variable([1.])
+ >>> m.trainable_variables
+ (,)
+
+ This tracking then allows saving variable values to
+ [training checkpoints](https://www.tensorflow.org/guide/checkpoint), or to
+ [SavedModels](https://www.tensorflow.org/guide/saved_model) which include
+ serialized TensorFlow graphs.
+
+ Variables are often captured and manipulated by \`tf.function\`s. This works the
+ same way the un-decorated function would have:
+
+ >>> v = tf.Variable(0.)
+ >>> read_and_decrement = tf.function(lambda: v.assign_sub(0.1))
+ >>> read_and_decrement()
+
+ >>> read_and_decrement()
+
+
+ Variables created inside a \`tf.function\` must be owned outside the function
+ and be created only once:
+
+ >>> class M(tf.Module):
+ ... @tf.function
+ ... def __call__(self, x):
+ ... if not hasattr(self, "v"): # Or set self.v to None in __init__
+ ... self.v = tf.Variable(x)
+ ... return self.v * x
+ >>> m = M()
+ >>> m(2.)
+
+ >>> m(3.)
+
+ >>> m.v
+
+
+ See the \`tf.function\` documentation for details.
+ `],["tf.VariableAggregation","description: Indicates how a distributed variable will be aggregated.",!1,`Indicates how a distributed variable will be aggregated.
+
+ \`tf.distribute.Strategy\` distributes a model by making multiple copies
+ (called "replicas") acting data-parallel on different elements of the input
+ batch. When performing some variable-update operation, say
+ \`var.assign_add(x)\`, in a model, we need to resolve how to combine the
+ different values for \`x\` computed in the different replicas.
+
+ * \`NONE\`: This is the default, giving an error if you use a
+ variable-update operation with multiple replicas.
+ * \`SUM\`: Add the updates across replicas.
+ * \`MEAN\`: Take the arithmetic mean ("average") of the updates across replicas.
+ * \`ONLY_FIRST_REPLICA\`: This is for when every replica is performing the same
+ update, but we only want to perform the update once. Used, e.g., for the
+ global step counter.
+ `],["tf.VariableSynchronization","description: Indicates when a distributed variable will be synced.",!1,`Indicates when a distributed variable will be synced.
+
+ * \`AUTO\`: Indicates that the synchronization will be determined by the current
+ \`DistributionStrategy\` (eg. With \`MirroredStrategy\` this would be
+ \`ON_WRITE\`).
+ * \`NONE\`: Indicates that there will only be one copy of the variable, so
+ there is no need to sync.
+ * \`ON_WRITE\`: Indicates that the variable will be updated across devices
+ every time it is written.
+ * \`ON_READ\`: Indicates that the variable will be aggregated across devices
+ when it is read (eg. when checkpointing or when evaluating an op that uses
+ the variable).
+
+ Example:
+ >>> temp_grad=[tf.Variable([0.], trainable=False,
+ ... synchronization=tf.VariableSynchronization.ON_READ,
+ ... aggregation=tf.VariableAggregation.MEAN
+ ... )]
+ `],["tf.variable_creator_scope","description: Scope which defines a variable creation function to be used by variable().",!1,`Scope which defines a variable creation function to be used by variable().
+
+ variable_creator is expected to be a function with the following signature:
+
+ \`\`\`
+ def variable_creator(next_creator, **kwargs)
+ \`\`\`
+
+ The creator is supposed to eventually call the next_creator to create a
+ variable if it does want to create a variable and not call Variable or
+ ResourceVariable directly. This helps make creators composable. A creator may
+ choose to create multiple variables, return already existing variables, or
+ simply register that a variable was created and defer to the next creators in
+ line. Creators can also modify the keyword arguments seen by the next
+ creators.
+
+ Custom getters in the variable scope will eventually resolve down to these
+ custom creators when they do create variables.
+
+ The valid keyword arguments in kwds are:
+
+ * initial_value: A \`Tensor\`, or Python object convertible to a \`Tensor\`,
+ which is the initial value for the Variable. The initial value must have
+ a shape specified unless \`validate_shape\` is set to False. Can also be a
+ callable with no argument that returns the initial value when called. In
+ that case, \`dtype\` must be specified. (Note that initializer functions
+ from init_ops.py must first be bound to a shape before being used here.)
+ * trainable: If \`True\`, the default, GradientTapes automatically watch
+ uses of this Variable.
+ * validate_shape: If \`False\`, allows the variable to be initialized with a
+ value of unknown shape. If \`True\`, the default, the shape of
+ \`initial_value\` must be known.
+ * caching_device: Optional device string describing where the Variable
+ should be cached for reading. Defaults to the Variable's device.
+ If not \`None\`, caches on another device. Typical use is to cache
+ on the device where the Ops using the Variable reside, to deduplicate
+ copying through \`Switch\` and other conditional statements.
+ * name: Optional name for the variable. Defaults to \`'Variable'\` and gets
+ uniquified automatically.
+ dtype: If set, initial_value will be converted to the given type.
+ If \`None\`, either the datatype will be kept (if \`initial_value\` is
+ a Tensor), or \`convert_to_tensor\` will decide.
+ * constraint: A constraint function to be applied to the variable after
+ updates by some algorithms.
+ * synchronization: Indicates when a distributed a variable will be
+ aggregated. Accepted values are constants defined in the class
+ \`tf.VariableSynchronization\`. By default the synchronization is set to
+ \`AUTO\` and the current \`DistributionStrategy\` chooses
+ when to synchronize.
+ * aggregation: Indicates how a distributed variable will be aggregated.
+ Accepted values are constants defined in the class
+ \`tf.VariableAggregation\`.
+
+ This set may grow over time, so it's important the signature of creators is as
+ mentioned above.
+
+ Args:
+ variable_creator: the passed creator
+
+ Yields:
+ A scope in which the creator is active
+ `],["tf.vectorized_map","description: Parallel map on the list of tensors unpacked from elems on dimension 0.",!1,`Parallel map on the list of tensors unpacked from \`elems\` on dimension 0.
+
+ This method works similar to \`tf.map_fn\` but is optimized to run much faster,
+ possibly with a much larger memory footprint. The speedups are obtained by
+ vectorization (see [Auto-Vectorizing TensorFlow Graphs: Jacobians,
+ Auto-Batching and Beyond](https://arxiv.org/pdf/1903.04243.pdf)). The idea
+ behind vectorization is to semantically launch all the invocations of \`fn\` in
+ parallel and fuse corresponding operations across all these invocations. This
+ fusion is done statically at graph generation time and the generated code is
+ often similar in performance to a manually fused version.
+
+ Because \`tf.vectorized_map\` fully parallelizes the batch, this method will
+ generally be significantly faster than using \`tf.map_fn\`, especially in eager
+ mode. However this is an experimental feature and currently has a lot of
+ limitations:
+ - There should be no data dependency between the different semantic
+ invocations of \`fn\`, i.e. it should be safe to map the elements of the
+ inputs in any order.
+ - Stateful kernels may mostly not be supported since these often imply a
+ data dependency. We do support a limited set of such stateful kernels
+ though (like RandomFoo, Variable operations like reads, etc).
+ - \`fn\` has limited support for control flow operations.
+ - \`fn\` should return nested structure of Tensors or Operations. However
+ if an Operation is returned, it should have zero outputs.
+ - The shape and dtype of any intermediate or output tensors in the
+ computation of \`fn\` should not depend on the input to \`fn\`.
+
+ Examples:
+ \`\`\`python
+ def outer_product(a):
+ return tf.tensordot(a, a, 0)
+
+ batch_size = 100
+ a = tf.ones((batch_size, 32, 32))
+ c = tf.vectorized_map(outer_product, a)
+ assert c.shape == (batch_size, 32, 32, 32, 32)
+ \`\`\`
+
+ \`\`\`python
+ # Computing per-example gradients
+
+ batch_size = 10
+ num_features = 32
+ layer = tf.keras.layers.Dense(1)
+
+ def model_fn(arg):
+ with tf.GradientTape() as g:
+ inp, label = arg
+ inp = tf.expand_dims(inp, 0)
+ label = tf.expand_dims(label, 0)
+ prediction = layer(inp)
+ loss = tf.nn.l2_loss(label - prediction)
+ return g.gradient(loss, (layer.kernel, layer.bias))
+
+ inputs = tf.random.uniform([batch_size, num_features])
+ labels = tf.random.uniform([batch_size, 1])
+ per_example_gradients = tf.vectorized_map(model_fn, (inputs, labels))
+ assert per_example_gradients[0].shape == (batch_size, num_features, 1)
+ assert per_example_gradients[1].shape == (batch_size, 1)
+ \`\`\`
+
+ Args:
+ fn: The callable to be performed. It accepts one argument, which will have
+ the same (possibly nested) structure as \`elems\`, and returns a possibly
+ nested structure of Tensors and Operations, which may be different than
+ the structure of \`elems\`.
+ elems: A tensor or (possibly nested) sequence of tensors, each of which will
+ be unpacked along their first dimension. The nested sequence of the
+ resulting slices will be mapped over by \`fn\`. The first dimensions of all
+ elements must broadcast to a consistent value; equivalently, each
+ element tensor must have first dimension of either \`B\` or \`1\`, for some
+ common batch size \`B >= 1\`.
+ fallback_to_while_loop: If true, on failing to vectorize an operation,
+ the unsupported op is wrapped in a tf.while_loop to execute the map
+ iterations. Note that this fallback only happens for unsupported ops and
+ other parts of \`fn\` are still vectorized. If false, on encountering an
+ unsupported op, a ValueError is thrown. Note that the fallbacks can result
+ in slowdowns since vectorization often yields speedup of one to two orders
+ of magnitude.
+
+ Returns:
+ A tensor or (possibly nested) sequence of tensors. Each tensor packs the
+ results of applying fn to tensors unpacked from elems along the first
+ dimension, from first to last.
+
+ Although they are less common as user-visible inputs and outputs, note that
+ tensors of type \`tf.variant\` which represent tensor lists (for example from
+ \`tf.raw_ops.TensorListFromTensor\`) are vectorized by stacking the list
+ contents rather than the variant itself, and so the container tensor will
+ have a scalar shape when returned rather than the usual stacked shape. This
+ improves the performance of control flow gradient vectorization.
+
+ Raises:
+ ValueError: If vectorization fails and fallback_to_while_loop is False.
+ `],["tf.version","description: Public API for tf.version namespace.",!1,`Public API for tf.version namespace.
+`],["tf.where","description: Returns the indices of non-zero elements, or multiplexes x and y.",!1,"Returns the indices of non-zero elements, or multiplexes `x` and `y`.\n\n This operation has two modes:\n\n 1. **Return the indices of non-zero elements** - When only\n `condition` is provided the result is an `int64` tensor where each row is\n the index of a non-zero element of `condition`. The result's shape\n is `[tf.math.count_nonzero(condition), tf.rank(condition)]`.\n 2. **Multiplex `x` and `y`** - When both `x` and `y` are provided the\n result has the shape of `x`, `y`, and `condition` broadcast together. The\n result is taken from `x` where `condition` is non-zero\n or `y` where `condition` is zero.\n\n #### 1. Return the indices of non-zero elements\n\n Note: In this mode `condition` can have a dtype of `bool` or any numeric\n dtype.\n\n If `x` and `y` are not provided (both are None):\n\n `tf.where` will return the indices of `condition` that are non-zero,\n in the form of a 2-D tensor with shape `[n, d]`, where `n` is the number of\n non-zero elements in `condition` (`tf.count_nonzero(condition)`), and `d` is\n the number of axes of `condition` (`tf.rank(condition)`).\n\n Indices are output in row-major order. The `condition` can have a `dtype` of\n `tf.bool`, or any numeric `dtype`.\n\n Here `condition` is a 1-axis `bool` tensor with 2 `True` values. The result\n has a shape of `[2,1]`\n\n >>> tf.where([True, False, False, True]).numpy()\n array([[0],\n [3]])\n\n Here `condition` is a 2-axis integer tensor, with 3 non-zero values. The\n result has a shape of `[3, 2]`.\n\n >>> tf.where([[1, 0, 0], [1, 0, 1]]).numpy()\n array([[0, 0],\n [1, 0],\n [1, 2]])\n\n Here `condition` is a 3-axis float tensor, with 5 non-zero values. The output\n shape is `[5, 3]`.\n\n >>> float_tensor = [[[0.1, 0], [0, 2.2], [3.5, 1e6]],\n ... [[0, 0], [0, 0], [99, 0]]]\n >>> tf.where(float_tensor).numpy()\n array([[0, 0, 0],\n [0, 1, 1],\n [0, 2, 0],\n [0, 2, 1],\n [1, 2, 0]])\n\n These indices are the same that `tf.sparse.SparseTensor` would use to\n represent the condition tensor:\n\n >>> sparse = tf.sparse.from_dense(float_tensor)\n >>> sparse.indices.numpy()\n array([[0, 0, 0],\n [0, 1, 1],\n [0, 2, 0],\n [0, 2, 1],\n [1, 2, 0]])\n\n A complex number is considered non-zero if either the real or imaginary\n component is non-zero:\n\n >>> tf.where([complex(0.), complex(1.), 0+1j, 1+1j]).numpy()\n array([[1],\n [2],\n [3]])\n\n #### 2. Multiplex `x` and `y`\n\n Note: In this mode `condition` must have a dtype of `bool`.\n\n If `x` and `y` are also provided (both have non-None values) the `condition`\n tensor acts as a mask that chooses whether the corresponding\n element / row in the output should be taken from `x` (if the element in\n `condition` is `True`) or `y` (if it is `False`).\n\n The shape of the result is formed by\n [broadcasting](https://docs.scipy.org/doc/numpy/reference/ufuncs.html)\n together the shapes of `condition`, `x`, and `y`.\n\n When all three inputs have the same size, each is handled element-wise.\n\n >>> tf.where([True, False, False, True],\n ... [1, 2, 3, 4],\n ... [100, 200, 300, 400]).numpy()\n array([ 1, 200, 300, 4], dtype=int32)\n\n There are two main rules for broadcasting:\n\n 1. If a tensor has fewer axes than the others, length-1 axes are added to the\n left of the shape.\n 2. Axes with length-1 are streched to match the coresponding axes of the other\n tensors.\n\n A length-1 vector is streched to match the other vectors:\n\n >>> tf.where([True, False, False, True], [1, 2, 3, 4], [100]).numpy()\n array([ 1, 100, 100, 4], dtype=int32)\n\n A scalar is expanded to match the other arguments:\n\n >>> tf.where([[True, False], [False, True]], [[1, 2], [3, 4]], 100).numpy()\n array([[ 1, 100], [100, 4]], dtype=int32)\n >>> tf.where([[True, False], [False, True]], 1, 100).numpy()\n array([[ 1, 100], [100, 1]], dtype=int32)\n\n A scalar `condition` returns the complete `x` or `y` tensor, with\n broadcasting applied.\n\n >>> tf.where(True, [1, 2, 3, 4], 100).numpy()\n array([1, 2, 3, 4], dtype=int32)\n >>> tf.where(False, [1, 2, 3, 4], 100).numpy()\n array([100, 100, 100, 100], dtype=int32)\n\n For a non-trivial example of broadcasting, here `condition` has a shape of\n `[3]`, `x` has a shape of `[3,3]`, and `y` has a shape of `[3,1]`.\n Broadcasting first expands the shape of `condition` to `[1,3]`. The final\n broadcast shape is `[3,3]`. `condition` will select columns from `x` and `y`.\n Since `y` only has one column, all columns from `y` will be identical.\n\n >>> tf.where([True, False, True],\n ... x=[[1, 2, 3],\n ... [4, 5, 6],\n ... [7, 8, 9]],\n ... y=[[100],\n ... [200],\n ... [300]]\n ... ).numpy()\n array([[ 1, 100, 3],\n [ 4, 200, 6],\n [ 7, 300, 9]], dtype=int32)\n\n Note that if the gradient of either branch of the `tf.where` generates\n a `NaN`, then the gradient of the entire `tf.where` will be `NaN`. This is\n because the gradient calculation for `tf.where` combines the two branches, for\n performance reasons.\n\n A workaround is to use an inner `tf.where` to ensure the function has\n no asymptote, and to avoid computing a value whose gradient is `NaN` by\n replacing dangerous inputs with safe inputs.\n\n Instead of this,\n\n >>> x = tf.constant(0., dtype=tf.float32)\n >>> with tf.GradientTape() as tape:\n ... tape.watch(x)\n ... y = tf.where(x < 1., 0., 1. / x)\n >>> print(tape.gradient(y, x))\n tf.Tensor(nan, shape=(), dtype=float32)\n\n Although, the `1. / x` values are never used, its gradient is a `NaN` when\n `x = 0`. Instead, we should guard that with another `tf.where`\n\n >>> x = tf.constant(0., dtype=tf.float32)\n >>> with tf.GradientTape() as tape:\n ... tape.watch(x)\n ... safe_x = tf.where(tf.equal(x, 0.), 1., x)\n ... y = tf.where(x < 1., 0., 1. / safe_x)\n >>> print(tape.gradient(y, x))\n tf.Tensor(0.0, shape=(), dtype=float32)\n\n See also:\n\n * `tf.sparse` - The indices returned by the first form of `tf.where` can be\n useful in `tf.sparse.SparseTensor` objects.\n * `tf.gather_nd`, `tf.scatter_nd`, and related ops - Given the\n list of indices returned from `tf.where` the `scatter` and `gather` family\n of ops can be used fetch values or insert values at those indices.\n * `tf.strings.length` - `tf.string` is not an allowed dtype for the\n `condition`. Use the string length instead.\n\n Args:\n condition: A `tf.Tensor` of dtype bool, or any numeric dtype. `condition`\n must have dtype `bool` when `x` and `y` are provided.\n x: If provided, a Tensor which is of the same type as `y`, and has a shape\n broadcastable with `condition` and `y`.\n y: If provided, a Tensor which is of the same type as `x`, and has a shape\n broadcastable with `condition` and `x`.\n name: A name of the operation (optional).\n\n Returns:\n If `x` and `y` are provided:\n A `Tensor` with the same type as `x` and `y`, and shape that\n is broadcast from `condition`, `x`, and `y`.\n Otherwise, a `Tensor` with shape `[tf.math.count_nonzero(condition),\n tf.rank(condition)]`.\n\n Raises:\n ValueError: When exactly one of `x` or `y` is non-None, or the shapes\n are not all broadcastable.\n "],["tf.while_loop","description: Repeat body while the condition cond is true. (deprecated argument values)",!1,`Repeat \`body\` while the condition \`cond\` is true. (deprecated argument values)
+
+Deprecated: SOME ARGUMENT VALUES ARE DEPRECATED: \`(back_prop=False)\`. They will be removed in a future version.
+Instructions for updating:
+back_prop=False is deprecated. Consider using tf.stop_gradient instead.
+Instead of:
+results = tf.while_loop(c, b, vars, back_prop=False)
+Use:
+results = tf.nest.map_structure(tf.stop_gradient, tf.while_loop(c, b, vars))
+
+\`cond\` is a callable returning a boolean scalar tensor. \`body\` is a callable
+returning a (possibly nested) tuple, namedtuple or list of tensors of the same
+arity (length and structure) and types as \`loop_vars\`. \`loop_vars\` is a
+(possibly nested) tuple, namedtuple or list of tensors that is passed to both
+\`cond\` and \`body\`. \`cond\` and \`body\` both take as many arguments as there are
+\`loop_vars\`.
+
+In addition to regular Tensors or IndexedSlices, the body may accept and
+return TensorArray objects. The flows of the TensorArray objects will
+be appropriately forwarded between loops and during gradient calculations.
+
+Note that \`while_loop\` calls \`cond\` and \`body\` *exactly once* (inside the
+call to \`while_loop\`, and not at all during \`Session.run()\`). \`while_loop\`
+stitches together the graph fragments created during the \`cond\` and \`body\`
+calls with some additional graph nodes to create the graph flow that
+repeats \`body\` until \`cond\` returns false.
+
+For correctness, \`tf.while_loop()\` strictly enforces shape invariants for
+the loop variables. A shape invariant is a (possibly partial) shape that
+is unchanged across the iterations of the loop. An error will be raised
+if the shape of a loop variable after an iteration is determined to be more
+general than or incompatible with its shape invariant. For example, a shape
+of [11, None] is more general than a shape of [11, 17], and [11, 21] is not
+compatible with [11, 17]. By default (if the argument \`shape_invariants\` is
+not specified), it is assumed that the initial shape of each tensor in
+\`loop_vars\` is the same in every iteration. The \`shape_invariants\` argument
+allows the caller to specify a less specific shape invariant for each loop
+variable, which is needed if the shape varies between iterations. The
+\`tf.Tensor.set_shape\`
+function may also be used in the \`body\` function to indicate that
+the output loop variable has a particular shape. The shape invariant for
+SparseTensor and IndexedSlices are treated specially as follows:
+
+a) If a loop variable is a SparseTensor, the shape invariant must be
+TensorShape([r]) where r is the rank of the dense tensor represented
+by the sparse tensor. It means the shapes of the three tensors of the
+SparseTensor are ([None], [None, r], [r]). NOTE: The shape invariant here
+is the shape of the SparseTensor.dense_shape property. It must be the shape of
+a vector.
+
+b) If a loop variable is an IndexedSlices, the shape invariant must be
+a shape invariant of the values tensor of the IndexedSlices. It means
+the shapes of the three tensors of the IndexedSlices are (shape, [shape[0]],
+[shape.ndims]).
+
+\`while_loop\` implements non-strict semantics, enabling multiple iterations
+to run in parallel. The maximum number of parallel iterations can be
+controlled by \`parallel_iterations\`, which gives users some control over
+memory consumption and execution order. For correct programs, \`while_loop\`
+should return the same result for any parallel_iterations > 0.
+
+For training, TensorFlow stores the tensors that are produced in the
+forward inference and are needed in back propagation. These tensors are a
+main source of memory consumption and often cause OOM errors when training
+on GPUs. When the flag swap_memory is true, we swap out these tensors from
+GPU to CPU. This for example allows us to train RNN models with very long
+sequences and large batches.
+
+Args:
+ cond: A callable that represents the termination condition of the loop.
+ body: A callable that represents the loop body.
+ loop_vars: A (possibly nested) tuple, namedtuple or list of numpy array,
+ \`Tensor\`, and \`TensorArray\` objects.
+ shape_invariants: The shape invariants for the loop variables.
+ parallel_iterations: The number of iterations allowed to run in parallel. It
+ must be a positive integer.
+ back_prop: (optional) Deprecated. False disables support for back
+ propagation. Prefer using \`tf.stop_gradient\` instead.
+ swap_memory: Whether GPU-CPU memory swap is enabled for this loop.
+ maximum_iterations: Optional maximum number of iterations of the while loop
+ to run. If provided, the \`cond\` output is AND-ed with an additional
+ condition ensuring the number of iterations executed is no greater than
+ \`maximum_iterations\`.
+ name: Optional name prefix for the returned tensors.
+
+Returns:
+ The output tensors for the loop variables after the loop. The return value
+ has the same structure as \`loop_vars\`.
+
+Raises:
+ TypeError: if \`cond\` or \`body\` is not callable.
+ ValueError: if \`loop_vars\` is empty.
+
+Example:
+
+\`\`\`python
+i = tf.constant(0)
+c = lambda i: tf.less(i, 10)
+b = lambda i: (tf.add(i, 1), )
+r = tf.while_loop(c, b, [i])
+\`\`\`
+
+Example with nesting and a namedtuple:
+
+\`\`\`python
+import collections
+Pair = collections.namedtuple('Pair', 'j, k')
+ijk_0 = (tf.constant(0), Pair(tf.constant(1), tf.constant(2)))
+c = lambda i, p: i < 10
+b = lambda i, p: (i + 1, Pair((p.j + p.k), (p.j - p.k)))
+ijk_final = tf.while_loop(c, b, ijk_0)
+\`\`\`
+
+Example using shape_invariants:
+
+\`\`\`python
+i0 = tf.constant(0)
+m0 = tf.ones([2, 2])
+c = lambda i, m: i < 10
+b = lambda i, m: [i+1, tf.concat([m, m], axis=0)]
+tf.while_loop(
+ c, b, loop_vars=[i0, m0],
+ shape_invariants=[i0.get_shape(), tf.TensorShape([None, 2])])
+\`\`\`
+
+Example which demonstrates non-strict semantics: In the following
+example, the final value of the counter \`i\` does not depend on \`x\`. So
+the \`while_loop\` can increment the counter parallel to updates of \`x\`.
+However, because the loop counter at one loop iteration depends
+on the value at the previous iteration, the loop counter itself cannot
+be incremented in parallel. Hence if we just want the final value of the
+counter (which we print on the line \`print(sess.run(i))\`), then
+\`x\` will never be incremented, but the counter will be updated on a
+single thread. Conversely, if we want the value of the output (which we
+print on the line \`print(sess.run(out).shape)\`), then the counter may be
+incremented on its own thread, while \`x\` can be incremented in
+parallel on a separate thread. In the extreme case, it is conceivable
+that the thread incrementing the counter runs until completion before
+\`x\` is incremented even a single time. The only thing that can never
+happen is that the thread updating \`x\` can never get ahead of the
+counter thread because the thread incrementing \`x\` depends on the value
+of the counter.
+
+\`\`\`python
+import tensorflow as tf
+
+n = 10000
+x = tf.constant(list(range(n)))
+c = lambda i, x: i < n
+b = lambda i, x: (tf.compat.v1.Print(i + 1, [i]), tf.compat.v1.Print(x + 1,
+[i], "x:"))
+i, out = tf.while_loop(c, b, (0, x))
+with tf.compat.v1.Session() as sess:
+ print(sess.run(i)) # prints [0] ... [9999]
+
+ # The following line may increment the counter and x in parallel.
+ # The counter thread may get ahead of the other thread, but not the
+ # other way around. So you may see things like
+ # [9996] x:[9987]
+ # meaning that the counter thread is on iteration 9996,
+ # while the other thread is on iteration 9987
+ print(sess.run(out).shape)
+\`\`\``],["tf.xla","description: Public API for tf.xla namespace.",!0,`Public API for tf.xla namespace.
+`],["tf.zeros","description: Creates a tensor with all elements set to zero.",!1,"Creates a tensor with all elements set to zero.\n\n See also `tf.zeros_like`, `tf.ones`, `tf.fill`, `tf.eye`.\n\n This operation returns a tensor of type `dtype` with shape `shape` and\n all elements set to zero.\n\n >>> tf.zeros([3, 4], tf.int32)\n \n\n Args:\n shape: A `list` of integers, a `tuple` of integers, or\n a 1-D `Tensor` of type `int32`.\n dtype: The DType of an element in the resulting `Tensor`.\n name: Optional string. A name for the operation.\n\n Returns:\n A `Tensor` with all elements set to zero.\n "],["tf.zeros_initializer","description: Initializer that generates tensors initialized to 0.",!1,`Initializer that generates tensors initialized to 0.
+
+ Initializers allow you to pre-specify an initialization strategy, encoded in
+ the Initializer object, without knowing the shape and dtype of the variable
+ being initialized.
+
+ Examples:
+
+ >>> def make_variables(k, initializer):
+ ... return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
+ ... tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
+ >>> v1, v2 = make_variables(3, tf.zeros_initializer())
+ >>> v1
+
+ >>> v2
+
+ >>> make_variables(4, tf.random_uniform_initializer(minval=-1., maxval=1.))
+ (, >> tensor = tf.constant([[1, 2, 3], [4, 5, 6]])\n >>> tf.zeros_like(tensor)\n \n\n >>> tf.zeros_like(tensor, dtype=tf.float32)\n \n\n >>> tf.zeros_like([[1, 2, 3], [4, 5, 6]])\n \n\n Args:\n input: A `Tensor` or array-like object.\n dtype: A type for the returned `Tensor`. Must be `float16`, `float32`,\n `float64`, `int8`, `uint8`, `int16`, `uint16`, `int32`, `int64`,\n `complex64`, `complex128`, `bool` or `string` (optional).\n name: A name for the operation (optional).\n\n Returns:\n A `Tensor` with all elements set to zero.\n "]];function Zb(){return{baseUrl:null,breaks:!1,extensions:null,gfm:!0,headerIds:!0,headerPrefix:"",highlight:null,langPrefix:"language-",mangle:!0,pedantic:!1,renderer:null,sanitize:!1,sanitizer:null,silent:!1,smartLists:!1,smartypants:!1,tokenizer:null,walkTokens:null,xhtml:!1}}let Fa=Zb();function b2(e){Fa=e}const v2=/[&<>"']/,y2=/[&<>"']/g,_2=/[<>"']|&(?!#?\w+;)/,w2=/[<>"']|&(?!#?\w+;)/g,x2={"&":"&","<":"<",">":">",'"':""","'":"'"},Hf=e=>x2[e];function Jt(e,t){if(t){if(v2.test(e))return e.replace(y2,Hf)}else if(_2.test(e))return e.replace(w2,Hf);return e}const k2=/&(#(?:\d+)|(?:#x[0-9A-Fa-f]+)|(?:\w+));?/ig;function Jb(e){return e.replace(k2,(t,n)=>(n=n.toLowerCase(),n==="colon"?":":n.charAt(0)==="#"?n.charAt(1)==="x"?String.fromCharCode(parseInt(n.substring(2),16)):String.fromCharCode(+n.substring(1)):""))}const T2=/(^|[^\[])\^/g;function Mt(e,t){e=typeof e=="string"?e:e.source,t=t||"";const n={replace:(o,r)=>(r=r.source||r,r=r.replace(T2,"$1"),e=e.replace(o,r),n),getRegex:()=>new RegExp(e,t)};return n}const C2=/[^\w:]/g,S2=/^$|^[a-z][a-z0-9+.-]*:|^[?#]/i;function qf(e,t,n){if(e){let o;try{o=decodeURIComponent(Jb(n)).replace(C2,"").toLowerCase()}catch{return null}if(o.indexOf("javascript:")===0||o.indexOf("vbscript:")===0||o.indexOf("data:")===0)return null}t&&!S2.test(n)&&(n=z2(t,n));try{n=encodeURI(n).replace(/%25/g,"%")}catch{return null}return n}const wi={},$2=/^[^:]+:\/*[^/]*$/,E2=/^([^:]+:)[\s\S]*$/,A2=/^([^:]+:\/*[^/]*)[\s\S]*$/;function z2(e,t){wi[" "+e]||($2.test(e)?wi[" "+e]=e+"/":wi[" "+e]=Di(e,"/",!0)),e=wi[" "+e];const n=e.indexOf(":")===-1;return t.substring(0,2)==="//"?n?t:e.replace(E2,"$1")+t:t.charAt(0)==="/"?n?t:e.replace(A2,"$1")+t:e+t}const _s={exec:function(){}};function so(e){let t=1,n,o;for(;t{let s=!1,c=l;for(;--c>=0&&i[c]==="\\";)s=!s;return s?"|":" |"}),o=n.split(/ \|/);let r=0;if(o[0].trim()||o.shift(),o.length>0&&!o[o.length-1].trim()&&o.pop(),o.length>t)o.splice(t);else for(;o.length1;)t&1&&(n+=e),t>>=1,e+=e;return n+e}function Uf(e,t,n,o){const r=t.href,a=t.title?Jt(t.title):null,l=e[1].replace(/\\([\[\]])/g,"$1");if(e[0].charAt(0)!=="!"){o.state.inLink=!0;const i={type:"link",raw:n,href:r,title:a,text:l,tokens:o.inlineTokens(l,[])};return o.state.inLink=!1,i}return{type:"image",raw:n,href:r,title:a,text:Jt(l)}}function I2(e,t){const n=e.match(/^(\s+)(?:```)/);if(n===null)return t;const o=n[1];return t.split(`
+`).map(r=>{const a=r.match(/^\s+/);if(a===null)return r;const[l]=a;return l.length>=o.length?r.slice(o.length):r}).join(`
+`)}class Fu{constructor(t){this.options=t||Fa}space(t){const n=this.rules.block.newline.exec(t);if(n&&n[0].length>0)return{type:"space",raw:n[0]}}code(t){const n=this.rules.block.code.exec(t);if(n){const o=n[0].replace(/^ {1,4}/gm,"");return{type:"code",raw:n[0],codeBlockStyle:"indented",text:this.options.pedantic?o:Di(o,`
+`)}}}fences(t){const n=this.rules.block.fences.exec(t);if(n){const o=n[0],r=I2(o,n[3]||"");return{type:"code",raw:o,lang:n[2]?n[2].trim():n[2],text:r}}}heading(t){const n=this.rules.block.heading.exec(t);if(n){let o=n[2].trim();if(/#$/.test(o)){const a=Di(o,"#");(this.options.pedantic||!a||/ $/.test(a))&&(o=a.trim())}const r={type:"heading",raw:n[0],depth:n[1].length,text:o,tokens:[]};return this.lexer.inline(r.text,r.tokens),r}}hr(t){const n=this.rules.block.hr.exec(t);if(n)return{type:"hr",raw:n[0]}}blockquote(t){const n=this.rules.block.blockquote.exec(t);if(n){const o=n[0].replace(/^ *>[ \t]?/gm,"");return{type:"blockquote",raw:n[0],tokens:this.lexer.blockTokens(o,[]),text:o}}}list(t){let n=this.rules.block.list.exec(t);if(n){let o,r,a,l,i,s,c,d,u,p,f,h,b=n[1].trim();const m=b.length>1,g={type:"list",raw:"",ordered:m,start:m?+b.slice(0,-1):"",loose:!1,items:[]};b=m?`\\d{1,9}\\${b.slice(-1)}`:`\\${b}`,this.options.pedantic&&(b=m?b:"[*+-]");const v=new RegExp(`^( {0,3}${b})((?:[ ][^\\n]*)?(?:\\n|$))`);for(;t&&(h=!1,!(!(n=v.exec(t))||this.rules.block.hr.test(t)));){if(o=n[0],t=t.substring(o.length),d=n[2].split(`
+`,1)[0],u=t.split(`
+`,1)[0],this.options.pedantic?(l=2,f=d.trimLeft()):(l=n[2].search(/[^ ]/),l=l>4?1:l,f=d.slice(l),l+=n[1].length),s=!1,!d&&/^ *$/.test(u)&&(o+=u+`
+`,t=t.substring(u.length+1),h=!0),!h){const T=new RegExp(`^ {0,${Math.min(3,l-1)}}(?:[*+-]|\\d{1,9}[.)])((?: [^\\n]*)?(?:\\n|$))`),w=new RegExp(`^ {0,${Math.min(3,l-1)}}((?:- *){3,}|(?:_ *){3,}|(?:\\* *){3,})(?:\\n+|$)`);for(;t&&(p=t.split(`
+`,1)[0],d=p,this.options.pedantic&&(d=d.replace(/^ {1,4}(?=( {4})*[^ ])/g," ")),!(T.test(d)||w.test(t)));){if(d.search(/[^ ]/)>=l||!d.trim())f+=`
+`+d.slice(l);else if(!s)f+=`
+`+d;else break;!s&&!d.trim()&&(s=!0),o+=p+`
+`,t=t.substring(p.length+1)}}g.loose||(c?g.loose=!0:/\n *\n *$/.test(o)&&(c=!0)),this.options.gfm&&(r=/^\[[ xX]\] /.exec(f),r&&(a=r[0]!=="[ ] ",f=f.replace(/^\[[ xX]\] +/,""))),g.items.push({type:"list_item",raw:o,task:!!r,checked:a,loose:!1,text:f}),g.raw+=o}g.items[g.items.length-1].raw=o.trimRight(),g.items[g.items.length-1].text=f.trimRight(),g.raw=g.raw.trimRight();const y=g.items.length;for(i=0;ik.type==="space"),w=T.every(k=>{const $=k.raw.split("");let z=0;for(const O of $)if(O===`
+`&&(z+=1),z>1)return!0;return!1});!g.loose&&T.length&&w&&(g.loose=!0,g.items[i].loose=!0)}return g}}html(t){const n=this.rules.block.html.exec(t);if(n){const o={type:"html",raw:n[0],pre:!this.options.sanitizer&&(n[1]==="pre"||n[1]==="script"||n[1]==="style"),text:n[0]};return this.options.sanitize&&(o.type="paragraph",o.text=this.options.sanitizer?this.options.sanitizer(n[0]):Jt(n[0]),o.tokens=[],this.lexer.inline(o.text,o.tokens)),o}}def(t){const n=this.rules.block.def.exec(t);if(n){n[3]&&(n[3]=n[3].substring(1,n[3].length-1));const o=n[1].toLowerCase().replace(/\s+/g," ");return{type:"def",tag:o,raw:n[0],href:n[2],title:n[3]}}}table(t){const n=this.rules.block.table.exec(t);if(n){const o={type:"table",header:Kf(n[1]).map(r=>({text:r})),align:n[2].replace(/^ *|\| *$/g,"").split(/ *\| */),rows:n[3]&&n[3].trim()?n[3].replace(/\n[ \t]*$/,"").split(`
+`):[]};if(o.header.length===o.align.length){o.raw=n[0];let r=o.align.length,a,l,i,s;for(a=0;a({text:c}));for(r=o.header.length,l=0;l/i.test(n[0])&&(this.lexer.state.inLink=!1),!this.lexer.state.inRawBlock&&/^<(pre|code|kbd|script)(\s|>)/i.test(n[0])?this.lexer.state.inRawBlock=!0:this.lexer.state.inRawBlock&&/^<\/(pre|code|kbd|script)(\s|>)/i.test(n[0])&&(this.lexer.state.inRawBlock=!1),{type:this.options.sanitize?"text":"html",raw:n[0],inLink:this.lexer.state.inLink,inRawBlock:this.lexer.state.inRawBlock,text:this.options.sanitize?this.options.sanitizer?this.options.sanitizer(n[0]):Jt(n[0]):n[0]}}link(t){const n=this.rules.inline.link.exec(t);if(n){const o=n[2].trim();if(!this.options.pedantic&&/^$/.test(o))return;const l=Di(o.slice(0,-1),"\\");if((o.length-l.length)%2===0)return}else{const l=N2(n[2],"()");if(l>-1){const s=(n[0].indexOf("!")===0?5:4)+n[1].length+l;n[2]=n[2].substring(0,l),n[0]=n[0].substring(0,s).trim(),n[3]=""}}let r=n[2],a="";if(this.options.pedantic){const l=/^([^'"]*[^\s])\s+(['"])(.*)\2/.exec(r);l&&(r=l[1],a=l[3])}else a=n[3]?n[3].slice(1,-1):"";return r=r.trim(),/^$/.test(o)?r=r.slice(1):r=r.slice(1,-1)),Uf(n,{href:r&&r.replace(this.rules.inline._escapes,"$1"),title:a&&a.replace(this.rules.inline._escapes,"$1")},n[0],this.lexer)}}reflink(t,n){let o;if((o=this.rules.inline.reflink.exec(t))||(o=this.rules.inline.nolink.exec(t))){let r=(o[2]||o[1]).replace(/\s+/g," ");if(r=n[r.toLowerCase()],!r||!r.href){const a=o[0].charAt(0);return{type:"text",raw:a,text:a}}return Uf(o,r,o[0],this.lexer)}}emStrong(t,n,o=""){let r=this.rules.inline.emStrong.lDelim.exec(t);if(!r||r[3]&&o.match(/[\p{L}\p{N}]/u))return;const a=r[1]||r[2]||"";if(!a||a&&(o===""||this.rules.inline.punctuation.exec(o))){const l=r[0].length-1;let i,s,c=l,d=0;const u=r[0][0]==="*"?this.rules.inline.emStrong.rDelimAst:this.rules.inline.emStrong.rDelimUnd;for(u.lastIndex=0,n=n.slice(-1*t.length+l);(r=u.exec(n))!=null;){if(i=r[1]||r[2]||r[3]||r[4]||r[5]||r[6],!i)continue;if(s=i.length,r[3]||r[4]){c+=s;continue}else if((r[5]||r[6])&&l%3&&!((l+s)%3)){d+=s;continue}if(c-=s,c>0)continue;if(s=Math.min(s,s+c+d),Math.min(l,s)%2){const f=t.slice(1,l+r.index+s);return{type:"em",raw:t.slice(0,l+r.index+s+1),text:f,tokens:this.lexer.inlineTokens(f,[])}}const p=t.slice(2,l+r.index+s-1);return{type:"strong",raw:t.slice(0,l+r.index+s+1),text:p,tokens:this.lexer.inlineTokens(p,[])}}}}codespan(t){const n=this.rules.inline.code.exec(t);if(n){let o=n[2].replace(/\n/g," ");const r=/[^ ]/.test(o),a=/^ /.test(o)&&/ $/.test(o);return r&&a&&(o=o.substring(1,o.length-1)),o=Jt(o,!0),{type:"codespan",raw:n[0],text:o}}}br(t){const n=this.rules.inline.br.exec(t);if(n)return{type:"br",raw:n[0]}}del(t){const n=this.rules.inline.del.exec(t);if(n)return{type:"del",raw:n[0],text:n[2],tokens:this.lexer.inlineTokens(n[2],[])}}autolink(t,n){const o=this.rules.inline.autolink.exec(t);if(o){let r,a;return o[2]==="@"?(r=Jt(this.options.mangle?n(o[1]):o[1]),a="mailto:"+r):(r=Jt(o[1]),a=r),{type:"link",raw:o[0],text:r,href:a,tokens:[{type:"text",raw:r,text:r}]}}}url(t,n){let o;if(o=this.rules.inline.url.exec(t)){let r,a;if(o[2]==="@")r=Jt(this.options.mangle?n(o[0]):o[0]),a="mailto:"+r;else{let l;do l=o[0],o[0]=this.rules.inline._backpedal.exec(o[0])[0];while(l!==o[0]);r=Jt(o[0]),o[1]==="www."?a="http://"+r:a=r}return{type:"link",raw:o[0],text:r,href:a,tokens:[{type:"text",raw:r,text:r}]}}}inlineText(t,n){const o=this.rules.inline.text.exec(t);if(o){let r;return this.lexer.state.inRawBlock?r=this.options.sanitize?this.options.sanitizer?this.options.sanitizer(o[0]):Jt(o[0]):o[0]:r=Jt(this.options.smartypants?n(o[0]):o[0]),{type:"text",raw:o[0],text:r}}}}const at={newline:/^(?: *(?:\n|$))+/,code:/^( {4}[^\n]+(?:\n(?: *(?:\n|$))*)?)+/,fences:/^ {0,3}(`{3,}(?=[^`\n]*\n)|~{3,})([^\n]*)\n(?:|([\s\S]*?)\n)(?: {0,3}\1[~`]* *(?=\n|$)|$)/,hr:/^ {0,3}((?:-[\t ]*){3,}|(?:_[ \t]*){3,}|(?:\*[ \t]*){3,})(?:\n+|$)/,heading:/^ {0,3}(#{1,6})(?=\s|$)(.*)(?:\n+|$)/,blockquote:/^( {0,3}> ?(paragraph|[^\n]*)(?:\n|$))+/,list:/^( {0,3}bull)([ \t][^\n]+?)?(?:\n|$)/,html:"^ {0,3}(?:<(script|pre|style|textarea)[\\s>][\\s\\S]*?(?:[^\\n]*\\n+|$)|comment[^\\n]*(\\n+|$)|<\\?[\\s\\S]*?(?:\\?>\\n*|$)|\\n*|$)|\\n*|$)|)[\\s\\S]*?(?:(?:\\n *)+\\n|$)|<(?!script|pre|style|textarea)([a-z][\\w-]*)(?:attribute)*? */?>(?=[ \\t]*(?:\\n|$))[\\s\\S]*?(?:(?:\\n *)+\\n|$)|(?=[ \\t]*(?:\\n|$))[\\s\\S]*?(?:(?:\\n *)+\\n|$))",def:/^ {0,3}\[(label)\]: *(?:\n *)?]+)>?(?:(?: +(?:\n *)?| *\n *)(title))? *(?:\n+|$)/,table:_s,lheading:/^([^\n]+)\n {0,3}(=+|-+) *(?:\n+|$)/,_paragraph:/^([^\n]+(?:\n(?!hr|heading|lheading|blockquote|fences|list|html|table| +\n)[^\n]+)*)/,text:/^[^\n]+/};at._label=/(?!\s*\])(?:\\.|[^\[\]\\])+/;at._title=/(?:"(?:\\"?|[^"\\])*"|'[^'\n]*(?:\n[^'\n]+)*\n?'|\([^()]*\))/;at.def=Mt(at.def).replace("label",at._label).replace("title",at._title).getRegex();at.bullet=/(?:[*+-]|\d{1,9}[.)])/;at.listItemStart=Mt(/^( *)(bull) */).replace("bull",at.bullet).getRegex();at.list=Mt(at.list).replace(/bull/g,at.bullet).replace("hr","\\n+(?=\\1?(?:(?:- *){3,}|(?:_ *){3,}|(?:\\* *){3,})(?:\\n+|$))").replace("def","\\n+(?="+at.def.source+")").getRegex();at._tag="address|article|aside|base|basefont|blockquote|body|caption|center|col|colgroup|dd|details|dialog|dir|div|dl|dt|fieldset|figcaption|figure|footer|form|frame|frameset|h[1-6]|head|header|hr|html|iframe|legend|li|link|main|menu|menuitem|meta|nav|noframes|ol|optgroup|option|p|param|section|source|summary|table|tbody|td|tfoot|th|thead|title|tr|track|ul";at._comment=/|$)/;at.html=Mt(at.html,"i").replace("comment",at._comment).replace("tag",at._tag).replace("attribute",/ +[a-zA-Z:_][\w.:-]*(?: *= *"[^"\n]*"| *= *'[^'\n]*'| *= *[^\s"'=<>`]+)?/).getRegex();at.paragraph=Mt(at._paragraph).replace("hr",at.hr).replace("heading"," {0,3}#{1,6} ").replace("|lheading","").replace("|table","").replace("blockquote"," {0,3}>").replace("fences"," {0,3}(?:`{3,}(?=[^`\\n]*\\n)|~{3,})[^\\n]*\\n").replace("list"," {0,3}(?:[*+-]|1[.)]) ").replace("html",")|<(?:script|pre|style|textarea|!--)").replace("tag",at._tag).getRegex();at.blockquote=Mt(at.blockquote).replace("paragraph",at.paragraph).getRegex();at.normal=so({},at);at.gfm=so({},at.normal,{table:"^ *([^\\n ].*\\|.*)\\n {0,3}(?:\\| *)?(:?-+:? *(?:\\| *:?-+:? *)*)(?:\\| *)?(?:\\n((?:(?! *\\n|hr|heading|blockquote|code|fences|list|html).*(?:\\n|$))*)\\n*|$)"});at.gfm.table=Mt(at.gfm.table).replace("hr",at.hr).replace("heading"," {0,3}#{1,6} ").replace("blockquote"," {0,3}>").replace("code"," {4}[^\\n]").replace("fences"," {0,3}(?:`{3,}(?=[^`\\n]*\\n)|~{3,})[^\\n]*\\n").replace("list"," {0,3}(?:[*+-]|1[.)]) ").replace("html",")|<(?:script|pre|style|textarea|!--)").replace("tag",at._tag).getRegex();at.gfm.paragraph=Mt(at._paragraph).replace("hr",at.hr).replace("heading"," {0,3}#{1,6} ").replace("|lheading","").replace("table",at.gfm.table).replace("blockquote"," {0,3}>").replace("fences"," {0,3}(?:`{3,}(?=[^`\\n]*\\n)|~{3,})[^\\n]*\\n").replace("list"," {0,3}(?:[*+-]|1[.)]) ").replace("html",")|<(?:script|pre|style|textarea|!--)").replace("tag",at._tag).getRegex();at.pedantic=so({},at.normal,{html:Mt(`^ *(?:comment *(?:\\n|\\s*$)|<(tag)[\\s\\S]+? *(?:\\n{2,}|\\s*$)|${t}
+`}return`${t}
+`}hr(){return this.options.xhtml?`
+`:`
+`}list(t,n,o){const r=n?"ol":"ul",a=n&&o!==1?' start="'+o+'"':"";return"<"+r+a+`> +`+t+" +`}listitem(t){return`${t}
+`}checkbox(t){return" "}paragraph(t){return`
+
+`+t+`
+`+n+`
+`}tablerow(t){return`
+${t}
+`}tablecell(t,n){const o=n.header?"th":"td";return(n.align?`<${o} align="${n.align}">`:`<${o}>`)+t+`
+`}strong(t){return`${t}`}em(t){return`${t}`}codespan(t){return`
":"
"}del(t){return`${t}`}link(t,n,o){if(t=qf(this.options.sanitize,this.options.baseUrl,t),t===null)return o;let r='",r}image(t,n,o){if(t=qf(this.options.sanitize,this.options.baseUrl,t),t===null)return o;let r=` ":">",r}text(t){return t}}class ev{strong(t){return t}em(t){return t}codespan(t){return t}del(t){return t}html(t){return t}text(t){return t}link(t,n,o){return""+o}image(t,n,o){return""+o}br(){return""}}class tv{constructor(){this.seen={}}serialize(t){return t.toLowerCase().trim().replace(/<[!\/a-z].*?>/ig,"").replace(/[\u2000-\u206F\u2E00-\u2E7F\\'!"#$%&()*+,./:;<=>?@[\]^`{|}~]/g,"").replace(/\s/g,"-")}getNextSafeSlug(t,n){let o=t,r=0;if(this.seen.hasOwnProperty(o)){r=this.seen[t];do r++,o=t+"-"+r;while(this.seen.hasOwnProperty(o))}return n||(this.seen[t]=r,this.seen[o]=0),o}slug(t,n={}){const o=this.serialize(t);return this.getNextSafeSlug(o,n.dryrun)}}class Po{constructor(t){this.options=t||Fa,this.options.renderer=this.options.renderer||new Lu,this.renderer=this.options.renderer,this.renderer.options=this.options,this.textRenderer=new ev,this.slugger=new tv}static parse(t,n){return new Po(n).parse(t)}static parseInline(t,n){return new Po(n).parseInline(t)}parse(t,n=!0){let o="",r,a,l,i,s,c,d,u,p,f,h,b,m,g,v,y,T,w,k;const $=t.length;for(r=0;r<$;r++){if(f=t[r],this.options.extensions&&this.options.extensions.renderers&&this.options.extensions.renderers[f.type]&&(k=this.options.extensions.renderers[f.type].call({parser:this},f),k!==!1||!["space","hr","heading","code","table","blockquote","list","html","paragraph","text"].includes(f.type))){o+=k||"";continue}switch(f.type){case"space":continue;case"hr":{o+=this.renderer.hr();continue}case"heading":{o+=this.renderer.heading(this.parseInline(f.tokens),f.depth,Jb(this.parseInline(f.tokens,this.textRenderer)),this.slugger);continue}case"code":{o+=this.renderer.code(f.text,f.lang,f.escaped);continue}case"table":{for(u="",d="",i=f.header.length,a=0;a
":">",r}text(t){return t}}class ev{strong(t){return t}em(t){return t}codespan(t){return t}del(t){return t}html(t){return t}text(t){return t}link(t,n,o){return""+o}image(t,n,o){return""+o}br(){return""}}class tv{constructor(){this.seen={}}serialize(t){return t.toLowerCase().trim().replace(/<[!\/a-z].*?>/ig,"").replace(/[\u2000-\u206F\u2E00-\u2E7F\\'!"#$%&()*+,./:;<=>?@[\]^`{|}~]/g,"").replace(/\s/g,"-")}getNextSafeSlug(t,n){let o=t,r=0;if(this.seen.hasOwnProperty(o)){r=this.seen[t];do r++,o=t+"-"+r;while(this.seen.hasOwnProperty(o))}return n||(this.seen[t]=r,this.seen[o]=0),o}slug(t,n={}){const o=this.serialize(t);return this.getNextSafeSlug(o,n.dryrun)}}class Po{constructor(t){this.options=t||Fa,this.options.renderer=this.options.renderer||new Lu,this.renderer=this.options.renderer,this.renderer.options=this.options,this.textRenderer=new ev,this.slugger=new tv}static parse(t,n){return new Po(n).parse(t)}static parseInline(t,n){return new Po(n).parseInline(t)}parse(t,n=!0){let o="",r,a,l,i,s,c,d,u,p,f,h,b,m,g,v,y,T,w,k;const $=t.length;for(r=0;r<$;r++){if(f=t[r],this.options.extensions&&this.options.extensions.renderers&&this.options.extensions.renderers[f.type]&&(k=this.options.extensions.renderers[f.type].call({parser:this},f),k!==!1||!["space","hr","heading","code","table","blockquote","list","html","paragraph","text"].includes(f.type))){o+=k||"";continue}switch(f.type){case"space":continue;case"hr":{o+=this.renderer.hr();continue}case"heading":{o+=this.renderer.heading(this.parseInline(f.tokens),f.depth,Jb(this.parseInline(f.tokens,this.textRenderer)),this.slugger);continue}case"code":{o+=this.renderer.code(f.text,f.lang,f.escaped);continue}case"table":{for(u="",d="",i=f.header.length,a=0;a0&&v.tokens[0].type==="paragraph"?(v.tokens[0].text=w+" "+v.tokens[0].text,v.tokens[0].tokens&&v.tokens[0].tokens.length>0&&v.tokens[0].tokens[0].type==="text"&&(v.tokens[0].tokens[0].text=w+" "+v.tokens[0].tokens[0].text)):v.tokens.unshift({type:"text",text:w}):g+=w),g+=this.parse(v.tokens,m),p+=this.renderer.listitem(g,T,y);o+=this.renderer.list(p,h,b);continue}case"html":{o+=this.renderer.html(f.text);continue}case"paragraph":{o+=this.renderer.paragraph(this.parseInline(f.tokens));continue}case"text":{for(p=f.tokens?this.parseInline(f.tokens):f.text;r+1<$&&t[r+1].type==="text";)f=t[++r],p+=`
+`+(f.tokens?this.parseInline(f.tokens):f.text);o+=n?this.renderer.paragraph(p):p;continue}default:{const z='Token with "'+f.type+'" type was not found.';if(this.options.silent){console.error(z);return}else throw new Error(z)}}}return o}parseInline(t,n){n=n||this.renderer;let o="",r,a,l;const i=t.length;for(r=0;r{o(i.text,i.lang,function(s,c){if(s)return a(s);c!=null&&c!==i.text&&(i.text=c,i.escaped=!0),l--,l===0&&a()})},0))}),l===0&&a();return}try{const o=Mo.lex(e,t);return t.walkTokens&&ht.walkTokens(o,t.walkTokens),Po.parse(o,t)}catch(o){if(o.message+=`
+Please report this to https://github.com/markedjs/marked.`,t.silent)return"({left:window.pageXOffset,top:window.pageYOffset});function b3(e){let t;if("el"in e){const n=e.el,o=typeof n=="string"&&n.startsWith("#"),r=typeof n=="string"?o?document.getElementById(n.slice(1)):document.querySelector(n):n;if(!r)return;t=g3(r,e)}else t=e;"scrollBehavior"in document.documentElement.style?window.scrollTo(t):window.scrollTo(t.left!=null?t.left:window.pageXOffset,t.top!=null?t.top:window.pageYOffset)}function Jf(e,t){return(history.state?history.state.position-t:-1)+e}const Td=new Map;function v3(e,t){Td.set(e,t)}function y3(e){const t=Td.get(e);return Td.delete(e),t}let _3=()=>location.protocol+"//"+location.host;function iv(e,t){const{pathname:n,search:o,hash:r}=t,a=e.indexOf("#");if(a>-1){let i=r.includes(e.slice(a))?e.slice(a).length:1,s=r.slice(i);return s[0]!=="/"&&(s="/"+s),Xf(s,"")}return Xf(n,e)+o+r}function w3(e,t,n,o){let r=[],a=[],l=null;const i=({state:p})=>{const f=iv(e,location),h=n.value,b=t.value;let m=0;if(p){if(n.value=f,t.value=p,l&&l===h){l=null;return}m=b?p.position-b.position:0}else o(f);r.forEach(g=>{g(n.value,h,{delta:m,type:Ol.pop,direction:m?m>0?gl.forward:gl.back:gl.unknown})})};function s(){l=n.value}function c(p){r.push(p);const f=()=>{const h=r.indexOf(p);h>-1&&r.splice(h,1)};return a.push(f),f}function d(){const{history:p}=window;!p.state||p.replaceState(Nt({},p.state,{scroll:Gs()}),"")}function u(){for(const p of a)p();a=[],window.removeEventListener("popstate",i),window.removeEventListener("beforeunload",d)}return window.addEventListener("popstate",i),window.addEventListener("beforeunload",d),{pauseListeners:s,listen:c,destroy:u}}function Qf(e,t,n,o=!1,r=!1){return{back:e,current:t,forward:n,replaced:o,position:window.history.length,scroll:r?Gs():null}}function x3(e){const{history:t,location:n}=window,o={value:iv(e,n)},r={value:t.state};r.value||a(o.value,{back:null,current:o.value,forward:null,position:t.length-1,replaced:!0,scroll:null},!0);function a(s,c,d){const u=e.indexOf("#"),p=u>-1?(n.host&&document.querySelector("base")?e:e.slice(u))+s:_3()+e+s;try{t[d?"replaceState":"pushState"](c,"",p),r.value=c}catch(f){console.error(f),n[d?"replace":"assign"](p)}}function l(s,c){const d=Nt({},t.state,Qf(r.value.back,s,r.value.forward,!0),c,{position:r.value.position});a(s,d,!0),o.value=s}function i(s,c){const d=Nt({},r.value,t.state,{forward:s,scroll:Gs()});a(d.current,d,!0);const u=Nt({},Qf(o.value,s,null),{position:d.position+1},c);a(s,u,!1),o.value=s}return{location:o,state:r,push:i,replace:l}}function k3(e){e=f3(e);const t=x3(e),n=w3(e,t.state,t.location,t.replace);function o(a,l=!0){l||n.pauseListeners(),history.go(a)}const r=Nt({location:"",base:e,go:o,createHref:m3.bind(null,e)},t,n);return Object.defineProperty(r,"location",{enumerable:!0,get:()=>t.location.value}),Object.defineProperty(r,"state",{enumerable:!0,get:()=>t.state.value}),r}function T3(e){return typeof e=="string"||e&&typeof e=="object"}function sv(e){return typeof e=="string"||typeof e=="symbol"}const Yo={path:"/",name:void 0,params:{},query:{},hash:"",fullPath:"/",matched:[],meta:{},redirectedFrom:void 0},cv=La("nf");var eh;(function(e){e[e.aborted=4]="aborted",e[e.cancelled=8]="cancelled",e[e.duplicated=16]="duplicated"})(eh||(eh={}));function ka(e,t){return Nt(new Error,{type:e,[cv]:!0},t)}function Go(e,t){return e instanceof Error&&cv in e&&(t==null||!!(e.type&t))}const th="[^/]+?",C3={sensitive:!1,strict:!1,start:!0,end:!0},S3=/[.+*?^${}()[\]/\\]/g;function $3(e,t){const n=Nt({},C3,t),o=[];let r=n.start?"^":"";const a=[];for(const c of e){const d=c.length?[]:[90];n.strict&&!c.length&&(r+="/");for(let u=0;u1&&(d.endsWith("/")?d=d.slice(0,-1):u=!0);else throw new Error(`Missing required param "${h}"`);d+=v}}return d}return{re:l,score:o,keys:a,parse:i,stringify:s}}function E3(e,t){let n=0;for(;nt.length?t.length===1&&t[0]===40+40?1:-1:0}function A3(e,t){let n=0;const o=e.score,r=t.score;for(;n1&&(s==="*"||s==="+")&&t(`A repeatable param (${c}) must be alone in its segment. eg: '/:ids+.`),a.push({type:1,value:c,regexp:d,repeatable:s==="*"||s==="+",optional:s==="*"||s==="?"})):t("Invalid state to consume buffer"),c="")}function p(){c+=s}for(;i{l(v)}:ml}function l(d){if(sv(d)){const u=o.get(d);u&&(o.delete(d),n.splice(n.indexOf(u),1),u.children.forEach(l),u.alias.forEach(l))}else{const u=n.indexOf(d);u>-1&&(n.splice(u,1),d.record.name&&o.delete(d.record.name),d.children.forEach(l),d.alias.forEach(l))}}function i(){return n}function s(d){let u=0;for(;u=0&&(d.record.path!==n[u].record.path||!dv(d,n[u]));)u++;n.splice(u,0,d),d.record.name&&!nh(d)&&o.set(d.record.name,d)}function c(d,u){let p,f={},h,b;if("name"in d&&d.name){if(p=o.get(d.name),!p)throw ka(1,{location:d});b=p.record.name,f=Nt(O3(u.params,p.keys.filter(v=>!v.optional).map(v=>v.name)),d.params),h=p.stringify(f)}else if("path"in d)h=d.path,p=n.find(v=>v.re.test(h)),p&&(f=p.parse(h),b=p.record.name);else{if(p=u.name?o.get(u.name):n.find(v=>v.re.test(u.path)),!p)throw ka(1,{location:d,currentLocation:u});b=p.record.name,f=Nt({},u.params,d.params),h=p.stringify(f)}const m=[];let g=p;for(;g;)m.unshift(g.record),g=g.parent;return{name:b,path:h,params:f,matched:m,meta:F3(m)}}return e.forEach(d=>a(d)),{addRoute:a,resolve:c,removeRoute:l,getRoutes:i,getRecordMatcher:r}}function O3(e,t){const n={};for(const o of t)o in e&&(n[o]=e[o]);return n}function R3(e){return{path:e.path,redirect:e.redirect,name:e.name,meta:e.meta||{},aliasOf:void 0,beforeEnter:e.beforeEnter,props:D3(e),children:e.children||[],instances:{},leaveGuards:new Set,updateGuards:new Set,enterCallbacks:{},components:"components"in e?e.components||{}:{default:e.component}}}function D3(e){const t={},n=e.props||!1;if("component"in e)t.default=n;else for(const o in e.components)t[o]=typeof n=="boolean"?n:n[o];return t}function nh(e){for(;e;){if(e.record.aliasOf)return!0;e=e.parent}return!1}function F3(e){return e.reduce((t,n)=>Nt(t,n.meta),{})}function oh(e,t){const n={};for(const o in e)n[o]=o in t?t[o]:e[o];return n}function dv(e,t){return t.children.some(n=>n===e||dv(e,n))}const uv=/#/g,L3=/&/g,V3=/\//g,B3=/=/g,j3=/\?/g,pv=/\+/g,H3=/%5B/g,q3=/%5D/g,fv=/%5E/g,K3=/%60/g,hv=/%7B/g,W3=/%7C/g,mv=/%7D/g,U3=/%20/g;function Bu(e){return encodeURI(""+e).replace(W3,"|").replace(H3,"[").replace(q3,"]")}function Y3(e){return Bu(e).replace(hv,"{").replace(mv,"}").replace(fv,"^")}function Cd(e){return Bu(e).replace(pv,"%2B").replace(U3,"+").replace(uv,"%23").replace(L3,"%26").replace(K3,"`").replace(hv,"{").replace(mv,"}").replace(fv,"^")}function G3(e){return Cd(e).replace(B3,"%3D")}function X3(e){return Bu(e).replace(uv,"%23").replace(j3,"%3F")}function Z3(e){return e==null?"":X3(e).replace(V3,"%2F")}function ws(e){try{return decodeURIComponent(""+e)}catch{}return""+e}function J3(e){const t={};if(e===""||e==="?")return t;const o=(e[0]==="?"?e.slice(1):e).split("&");for(let r=0;ra&&Cd(a)):[o&&Cd(o)]).forEach(a=>{a!==void 0&&(t+=(t.length?"&":"")+n,a!=null&&(t+="="+a))})}return t}function Q3(e){const t={};for(const n in e){const o=e[n];o!==void 0&&(t[n]=Array.isArray(o)?o.map(r=>r==null?null:""+r):o==null?o:""+o)}return t}function Qa(){let e=[];function t(o){return e.push(o),()=>{const r=e.indexOf(o);r>-1&&e.splice(r,1)}}function n(){e=[]}return{add:t,list:()=>e,reset:n}}function nr(e,t,n,o,r){const a=o&&(o.enterCallbacks[r]=o.enterCallbacks[r]||[]);return()=>new Promise((l,i)=>{const s=u=>{u===!1?i(ka(4,{from:n,to:t})):u instanceof Error?i(u):T3(u)?i(ka(2,{from:t,to:u})):(a&&o.enterCallbacks[r]===a&&typeof u=="function"&&a.push(u),l())},c=e.call(o&&o.instances[r],t,n,s);let d=Promise.resolve(c);e.length<3&&(d=d.then(s)),d.catch(u=>i(u))})}function Sc(e,t,n,o){const r=[];for(const a of e)for(const l in a.components){let i=a.components[l];if(!(t!=="beforeRouteEnter"&&!a.instances[l]))if(ek(i)){const c=(i.__vccOpts||i)[t];c&&r.push(nr(c,n,o,a,l))}else{let s=i();r.push(()=>s.then(c=>{if(!c)return Promise.reject(new Error(`Couldn't resolve component "${l}" at "${a.path}"`));const d=l3(c)?c.default:c;a.components[l]=d;const p=(d.__vccOpts||d)[t];return p&&nr(p,n,o,a,l)()}))}}return r}function ek(e){return typeof e=="object"||"displayName"in e||"props"in e||"__vccOpts"in e}function ah(e){const t=Ne(Vu),n=Ne(av),o=C(()=>t.resolve(_(e.to))),r=C(()=>{const{matched:s}=o.value,{length:c}=s,d=s[c-1],u=n.matched;if(!d||!u.length)return-1;const p=u.findIndex(xa.bind(null,d));if(p>-1)return p;const f=lh(s[c-2]);return c>1&&lh(d)===f&&u[u.length-1].path!==f?u.findIndex(xa.bind(null,s[c-2])):p}),a=C(()=>r.value>-1&&rk(n.params,o.value.params)),l=C(()=>r.value>-1&&r.value===n.matched.length-1&&lv(n.params,o.value.params));function i(s={}){return ok(s)?t[_(e.replace)?"replace":"push"](_(e.to)).catch(ml):Promise.resolve()}return{route:o,href:C(()=>o.value.href),isActive:a,isExactActive:l,navigate:i}}const tk=ee({name:"RouterLink",props:{to:{type:[String,Object],required:!0},replace:Boolean,activeClass:String,exactActiveClass:String,custom:Boolean,ariaCurrentValue:{type:String,default:"page"}},useLink:ah,setup(e,{slots:t}){const n=vt(ah(e)),{options:o}=Ne(Vu),r=C(()=>({[ih(e.activeClass,o.linkActiveClass,"router-link-active")]:n.isActive,[ih(e.exactActiveClass,o.linkExactActiveClass,"router-link-exact-active")]:n.isExactActive}));return()=>{const a=t.default&&t.default(n);return e.custom?a:Pe("a",{"aria-current":n.isExactActive?e.ariaCurrentValue:null,href:n.href,onClick:n.navigate,class:r.value},a)}}}),nk=tk;function ok(e){if(!(e.metaKey||e.altKey||e.ctrlKey||e.shiftKey)&&!e.defaultPrevented&&!(e.button!==void 0&&e.button!==0)){if(e.currentTarget&&e.currentTarget.getAttribute){const t=e.currentTarget.getAttribute("target");if(/\b_blank\b/i.test(t))return}return e.preventDefault&&e.preventDefault(),!0}}function rk(e,t){for(const n in t){const o=t[n],r=e[n];if(typeof o=="string"){if(o!==r)return!1}else if(!Array.isArray(r)||r.length!==o.length||o.some((a,l)=>a!==r[l]))return!1}return!0}function lh(e){return e?e.aliasOf?e.aliasOf.path:e.path:""}const ih=(e,t,n)=>e!=null?e:t!=null?t:n,ak=ee({name:"RouterView",inheritAttrs:!1,props:{name:{type:String,default:"default"},route:Object},compatConfig:{MODE:3},setup(e,{attrs:t,slots:n}){const o=Ne(kd),r=C(()=>e.route||o.value),a=Ne(Gf,0),l=C(()=>r.value.matched[a]);ot(Gf,a+1),ot(a3,l),ot(kd,r);const i=E();return ge(()=>[i.value,l.value,e.name],([s,c,d],[u,p,f])=>{c&&(c.instances[d]=s,p&&p!==c&&s&&s===u&&(c.leaveGuards.size||(c.leaveGuards=p.leaveGuards),c.updateGuards.size||(c.updateGuards=p.updateGuards))),s&&c&&(!p||!xa(c,p)||!u)&&(c.enterCallbacks[d]||[]).forEach(h=>h(s))},{flush:"post"}),()=>{const s=r.value,c=l.value,d=c&&c.components[e.name],u=e.name;if(!d)return sh(n.default,{Component:d,route:s});const p=c.props[e.name],f=p?p===!0?s.params:typeof p=="function"?p(s):p:null,b=Pe(d,Nt({},f,t,{onVnodeUnmounted:m=>{m.component.isUnmounted&&(c.instances[u]=null)},ref:i}));return sh(n.default,{Component:b,route:s})||b}}});function sh(e,t){if(!e)return null;const n=e(t);return n.length===1?n[0]:n}const lk=ak;function ik(e){const t=P3(e.routes,e),n=e.parseQuery||J3,o=e.stringifyQuery||rh,r=e.history,a=Qa(),l=Qa(),i=Qa(),s=Kt(Yo);let c=Yo;ia&&e.scrollBehavior&&"scrollRestoration"in history&&(history.scrollRestoration="manual");const d=Tc.bind(null,oe=>""+oe),u=Tc.bind(null,Z3),p=Tc.bind(null,ws);function f(oe,H){let ne,le;return sv(oe)?(ne=t.getRecordMatcher(oe),le=H):le=oe,t.addRoute(le,ne)}function h(oe){const H=t.getRecordMatcher(oe);H&&t.removeRoute(H)}function b(){return t.getRoutes().map(oe=>oe.record)}function m(oe){return!!t.getRecordMatcher(oe)}function g(oe,H){if(H=Nt({},H||s.value),typeof oe=="string"){const Me=Cc(n,oe,H.path),j=t.resolve({path:Me.path},H),X=r.createHref(Me.fullPath);return Nt(Me,j,{params:p(j.params),hash:ws(Me.hash),redirectedFrom:void 0,href:X})}let ne;if("path"in oe)ne=Nt({},oe,{path:Cc(n,oe.path,H.path).path});else{const Me=Nt({},oe.params);for(const j in Me)Me[j]==null&&delete Me[j];ne=Nt({},oe,{params:u(oe.params)}),H.params=u(H.params)}const le=t.resolve(ne,H),be=oe.hash||"";le.params=d(p(le.params));const $e=c3(o,Nt({},oe,{hash:Y3(be),path:le.path})),Ie=r.createHref($e);return Nt({fullPath:$e,hash:be,query:o===rh?Q3(oe.query):oe.query||{}},le,{redirectedFrom:void 0,href:Ie})}function v(oe){return typeof oe=="string"?Cc(n,oe,s.value.path):Nt({},oe)}function y(oe,H){if(c!==oe)return ka(8,{from:H,to:oe})}function T(oe){return $(oe)}function w(oe){return T(Nt(v(oe),{replace:!0}))}function k(oe){const H=oe.matched[oe.matched.length-1];if(H&&H.redirect){const{redirect:ne}=H;let le=typeof ne=="function"?ne(oe):ne;return typeof le=="string"&&(le=le.includes("?")||le.includes("#")?le=v(le):{path:le},le.params={}),Nt({query:oe.query,hash:oe.hash,params:oe.params},le)}}function $(oe,H){const ne=c=g(oe),le=s.value,be=oe.state,$e=oe.force,Ie=oe.replace===!0,Me=k(ne);if(Me)return $(Nt(v(Me),{state:be,force:$e,replace:Ie}),H||ne);const j=ne;j.redirectedFrom=H;let X;return!$e&&d3(o,le,ne)&&(X=ka(16,{to:j,from:le}),Y(le,le,!0,!1)),(X?Promise.resolve(X):O(j,le)).catch(de=>Go(de)?Go(de,2)?de:W(de):A(de,j,le)).then(de=>{if(de){if(Go(de,2))return $(Nt(v(de.to),{state:be,force:$e,replace:Ie}),H||j)}else de=F(j,le,!0,Ie,be);return R(j,le,de),de})}function z(oe,H){const ne=y(oe,H);return ne?Promise.reject(ne):Promise.resolve()}function O(oe,H){let ne;const[le,be,$e]=sk(oe,H);ne=Sc(le.reverse(),"beforeRouteLeave",oe,H);for(const Me of le)Me.leaveGuards.forEach(j=>{ne.push(nr(j,oe,H))});const Ie=z.bind(null,oe,H);return ne.push(Ie),Qr(ne).then(()=>{ne=[];for(const Me of a.list())ne.push(nr(Me,oe,H));return ne.push(Ie),Qr(ne)}).then(()=>{ne=Sc(be,"beforeRouteUpdate",oe,H);for(const Me of be)Me.updateGuards.forEach(j=>{ne.push(nr(j,oe,H))});return ne.push(Ie),Qr(ne)}).then(()=>{ne=[];for(const Me of oe.matched)if(Me.beforeEnter&&!H.matched.includes(Me))if(Array.isArray(Me.beforeEnter))for(const j of Me.beforeEnter)ne.push(nr(j,oe,H));else ne.push(nr(Me.beforeEnter,oe,H));return ne.push(Ie),Qr(ne)}).then(()=>(oe.matched.forEach(Me=>Me.enterCallbacks={}),ne=Sc($e,"beforeRouteEnter",oe,H),ne.push(Ie),Qr(ne))).then(()=>{ne=[];for(const Me of l.list())ne.push(nr(Me,oe,H));return ne.push(Ie),Qr(ne)}).catch(Me=>Go(Me,8)?Me:Promise.reject(Me))}function R(oe,H,ne){for(const le of i.list())le(oe,H,ne)}function F(oe,H,ne,le,be){const $e=y(oe,H);if($e)return $e;const Ie=H===Yo,Me=ia?history.state:{};ne&&(le||Ie?r.replace(oe.fullPath,Nt({scroll:Ie&&Me&&Me.scroll},be)):r.push(oe.fullPath,be)),s.value=oe,Y(oe,H,ne,Ie),W()}let L;function D(){L||(L=r.listen((oe,H,ne)=>{const le=g(oe),be=k(le);if(be){$(Nt(be,{replace:!0}),le).catch(ml);return}c=le;const $e=s.value;ia&&v3(Jf($e.fullPath,ne.delta),Gs()),O(le,$e).catch(Ie=>Go(Ie,12)?Ie:Go(Ie,2)?($(Ie.to,le).then(Me=>{Go(Me,20)&&!ne.delta&&ne.type===Ol.pop&&r.go(-1,!1)}).catch(ml),Promise.reject()):(ne.delta&&r.go(-ne.delta,!1),A(Ie,le,$e))).then(Ie=>{Ie=Ie||F(le,$e,!1),Ie&&(ne.delta?r.go(-ne.delta,!1):ne.type===Ol.pop&&Go(Ie,20)&&r.go(-1,!1)),R(le,$e,Ie)}).catch(ml)}))}let V=Qa(),q=Qa(),P;function A(oe,H,ne){W(oe);const le=q.list();return le.length?le.forEach(be=>be(oe,H,ne)):console.error(oe),Promise.reject(oe)}function I(){return P&&s.value!==Yo?Promise.resolve():new Promise((oe,H)=>{V.add([oe,H])})}function W(oe){return P||(P=!oe,D(),V.list().forEach(([H,ne])=>oe?ne(oe):H()),V.reset()),oe}function Y(oe,H,ne,le){const{scrollBehavior:be}=e;if(!ia||!be)return Promise.resolve();const $e=!ne&&y3(Jf(oe.fullPath,0))||(le||!ne)&&history.state&&history.state.scroll||null;return je().then(()=>be(oe,H,$e)).then(Ie=>Ie&&b3(Ie)).catch(Ie=>A(Ie,oe,H))}const J=oe=>r.go(oe);let Z;const se=new Set;return{currentRoute:s,addRoute:f,removeRoute:h,hasRoute:m,getRoutes:b,resolve:g,options:e,push:T,replace:w,go:J,back:()=>J(-1),forward:()=>J(1),beforeEach:a.add,beforeResolve:l.add,afterEach:i.add,onError:q.add,isReady:I,install(oe){const H=this;oe.component("RouterLink",nk),oe.component("RouterView",lk),oe.config.globalProperties.$router=H,Object.defineProperty(oe.config.globalProperties,"$route",{enumerable:!0,get:()=>_(s)}),ia&&!Z&&s.value===Yo&&(Z=!0,T(r.location).catch(be=>{}));const ne={};for(const be in Yo)ne[be]=C(()=>s.value[be]);oe.provide(Vu,H),oe.provide(av,vt(ne)),oe.provide(kd,s);const le=oe.unmount;se.add(oe),oe.unmount=function(){se.delete(oe),se.size<1&&(c=Yo,L&&L(),L=null,s.value=Yo,Z=!1,P=!1),le()}}}}function Qr(e){return e.reduce((t,n)=>t.then(()=>n()),Promise.resolve())}function sk(e,t){const n=[],o=[],r=[],a=Math.max(t.matched.length,e.matched.length);for(let l=0;lxa(c,i))?o.push(i):n.push(i));const s=e.matched[l];s&&(t.matched.find(c=>xa(c,s))||r.push(s))}return[n,o,r]}const ck=[{path:"/",name:"Home",component:U2},{path:"/about",name:"About",component:r3}],dk=ik({history:k3(),routes:ck});var uk=typeof global=="object"&&global&&global.Object===Object&&global,gv=uk,pk=typeof self=="object"&&self&&self.Object===Object&&self,fk=gv||pk||Function("return this")(),co=fk,hk=co.Symbol,jn=hk,bv=Object.prototype,mk=bv.hasOwnProperty,gk=bv.toString,el=jn?jn.toStringTag:void 0;function bk(e){var t=mk.call(e,el),n=e[el];try{e[el]=void 0;var o=!0}catch{}var r=gk.call(e);return o&&(t?e[el]=n:delete e[el]),r}var vk=Object.prototype,yk=vk.toString;function _k(e){return yk.call(e)}var wk="[object Null]",xk="[object Undefined]",ch=jn?jn.toStringTag:void 0;function Va(e){return e==null?e===void 0?xk:wk:ch&&ch in Object(e)?bk(e):_k(e)}function Oo(e){return e!=null&&typeof e=="object"}var kk="[object Symbol]";function Xs(e){return typeof e=="symbol"||Oo(e)&&Va(e)==kk}function Tk(e,t){for(var n=-1,o=e==null?0:e.length,r=Array(o);++n0){if(++t>=r6)return arguments[0]}else t=0;return e.apply(void 0,arguments)}}function s6(e){return function(){return e}}var c6=function(){try{var e=Yr(Object,"defineProperty");return e({},"",{}),e}catch{}}(),xs=c6,d6=xs?function(e,t){return xs(e,"toString",{configurable:!0,enumerable:!1,value:s6(t),writable:!0})}:yv,u6=d6,p6=i6(u6),wv=p6;function f6(e,t){for(var n=-1,o=e==null?0:e.length;++n-1}var y6=9007199254740991,_6=/^(?:0|[1-9]\d*)$/;function ju(e,t){var n=typeof e;return t=t==null?y6:t,!!t&&(n=="number"||n!="symbol"&&_6.test(e))&&e>-1&&e%1==0&&e-1&&e%1==0&&e<=T6}function Wu(e){return e!=null&&Ku(e.length)&&!_v(e)}var C6=Object.prototype;function Uu(e){var t=e&&e.constructor,n=typeof t=="function"&&t.prototype||C6;return e===n}function S6(e,t){for(var n=-1,o=Array(e);++n-1}function BT(e,t){var n=this.__data__,o=Js(n,e);return o<0?(++this.size,n.push([e,t])):n[o][1]=t,this}function Vo(e){var t=-1,n=e==null?0:e.length;for(this.clear();++t0&&n(i)?t>1?nc(i,t-1,n,o,r):Qu(r,i):o||(r[r.length]=i)}return r}function aC(e){var t=e==null?0:e.length;return t?nc(e,1):[]}function lC(e){return wv(kv(e,void 0,aC),e+"")}var iC=Av(Object.getPrototypeOf,Object),Nv=iC;function Fl(){if(!arguments.length)return[];var e=arguments[0];return ro(e)?e:[e]}function sC(){this.__data__=new Vo,this.size=0}function cC(e){var t=this.__data__,n=t.delete(e);return this.size=t.size,n}function dC(e){return this.__data__.get(e)}function uC(e){return this.__data__.has(e)}var pC=200;function fC(e,t){var n=this.__data__;if(n instanceof Vo){var o=n.__data__;if(!Dl||o.lengthi))return!1;var c=a.get(e),d=a.get(t);if(c&&d)return c==t&&d==e;var u=-1,p=!0,f=n&QS?new Vl:void 0;for(a.set(e,t),a.set(t,e);++u=t||$<0||u&&z>=a}function g(){var k=zc();if(m(k))return v(k);i=setTimeout(g,b(k))}function v(k){return i=void 0,p&&o?f(k):(o=r=void 0,l)}function y(){i!==void 0&&clearTimeout(i),c=0,o=s=r=i=void 0}function T(){return i===void 0?l:v(zc())}function w(){var k=zc(),$=m(k);if(o=arguments,r=this,s=k,$){if(i===void 0)return h(s);if(u)return clearTimeout(i),i=setTimeout(g,t),f(s)}return i===void 0&&(i=setTimeout(g,t)),l}return w.cancel=y,w.flush=T,w}function A$(e){return Oo(e)&&Wu(e)}function z$(e,t,n){for(var o=-1,r=e==null?0:e.length;++o=B$){var c=t?null:V$(e);if(c)return np(c);l=!1,r=Lv,s=new Vl}else s=t?[]:i;e:for(;++ogetComputedStyle(e).position==="fixed"?!1:e.offsetParent!==null,Lh=e=>Array.from(e.querySelectorAll(q$)).filter(t=>W$(t)&&K$(t)),W$=e=>{if(e.tabIndex>0||e.tabIndex===0&&e.getAttribute("tabIndex")!==null)return!0;if(e.disabled)return!1;switch(e.nodeName){case"A":return!!e.href&&e.rel!=="ignore";case"INPUT":return!(e.type==="hidden"||e.type==="file");case"BUTTON":case"SELECT":case"TEXTAREA":return!0;default:return!1}},Li=function(e,t,...n){let o;t.includes("mouse")||t.includes("click")?o="MouseEvents":t.includes("key")?o="KeyboardEvent":o="HTMLEvents";const r=document.createEvent(o);return r.initEvent(t,...n),e.dispatchEvent(r),e},qv=e=>!e.getAttribute("aria-owns"),Kv=(e,t,n)=>{const{parentNode:o}=e;if(!o)return null;const r=o.querySelectorAll(n),a=Array.prototype.indexOf.call(r,e);return r[a+t]||null},Vi=e=>{!e||(e.focus(),!qv(e)&&e.click())},Et=(e,t,n,o=!1)=>{e&&t&&n&&(e==null||e.addEventListener(t,n,o))},Bt=(e,t,n,o=!1)=>{e&&t&&n&&(e==null||e.removeEventListener(t,n,o))},U$=(e,t,n)=>{const o=function(...r){n&&n.apply(this,r),Bt(e,t,o)};Et(e,t,o)},Rt=(e,t,{checkForDefaultPrevented:n=!0}={})=>r=>{const a=e==null?void 0:e(r);if(n===!1||!a)return t==null?void 0:t(r)},Vh=e=>t=>t.pointerType==="mouse"?e(t):void 0;var Y$=Object.defineProperty,G$=Object.defineProperties,X$=Object.getOwnPropertyDescriptors,Bh=Object.getOwnPropertySymbols,Z$=Object.prototype.hasOwnProperty,J$=Object.prototype.propertyIsEnumerable,jh=(e,t,n)=>t in e?Y$(e,t,{enumerable:!0,configurable:!0,writable:!0,value:n}):e[t]=n,Q$=(e,t)=>{for(var n in t||(t={}))Z$.call(t,n)&&jh(e,n,t[n]);if(Bh)for(var n of Bh(t))J$.call(t,n)&&jh(e,n,t[n]);return e},e4=(e,t)=>G$(e,X$(t));function Hh(e,t){var n;const o=Kt();return Fn(()=>{o.value=e()},e4(Q$({},t),{flush:(n=t==null?void 0:t.flush)!=null?n:"sync"})),Zl(o)}function oc(e){return R1()?(jg(e),!0):!1}const dt=typeof window!="undefined",on=e=>typeof e=="boolean",mt=e=>typeof e=="number",t4=e=>typeof e=="string",Ic=()=>{};function Wv(e,t){function n(...o){e(()=>t.apply(this,o),{fn:t,thisArg:this,args:o})}return n}function n4(e,t={}){let n,o;return a=>{const l=_(e),i=_(t.maxWait);if(n&&clearTimeout(n),l<=0||i!==void 0&&i<=0)return o&&(clearTimeout(o),o=null),a();i&&!o&&(o=setTimeout(()=>{n&&clearTimeout(n),o=null,a()},i)),n=setTimeout(()=>{o&&clearTimeout(o),o=null,a()},l)}}function o4(e,t=!0,n=!0){let o=0,r,a=!n;const l=()=>{r&&(clearTimeout(r),r=void 0)};return s=>{const c=_(e),d=Date.now()-o;if(l(),c<=0)return o=Date.now(),s();d>c&&(o=Date.now(),a?a=!1:s()),t&&(r=setTimeout(()=>{o=Date.now(),n||(a=!0),l(),s()},c)),!n&&!r&&(r=setTimeout(()=>a=!0,c))}}function r4(e,t=200,n={}){return Wv(n4(t,n),e)}function a4(e,t=200,n={}){if(t<=0)return e;const o=E(e.value),r=r4(()=>{o.value=e.value},t,n);return ge(e,()=>r()),o}function Uv(e,t=200,n=!0,o=!0){return Wv(o4(t,n,o),e)}function l4(e,t=!0){nt()?et(e):t?e():je(e)}function jr(e,t,n={}){const{immediate:o=!0}=n,r=E(!1);let a=null;function l(){a&&(clearTimeout(a),a=null)}function i(){r.value=!1,l()}function s(...c){l(),r.value=!0,a=setTimeout(()=>{r.value=!1,a=null,e(...c)},_(t))}return o&&(r.value=!0,dt&&s()),oc(i),{isPending:r,start:s,stop:i}}function no(e){var t;const n=_(e);return(t=n==null?void 0:n.$el)!=null?t:n}const oi=dt?window:void 0,i4=dt?window.document:void 0;function Ht(...e){let t,n,o,r;if(t4(e[0])?([n,o,r]=e,t=oi):[t,n,o,r]=e,!t)return Ic;let a=Ic;const l=ge(()=>no(t),s=>{a(),s&&(s.addEventListener(n,o,r),a=()=>{s.removeEventListener(n,o,r),a=Ic})},{immediate:!0,flush:"post"}),i=()=>{l(),a()};return oc(i),i}function Cs(e,t,n={}){const{window:o=oi,ignore:r,capture:a=!0}=n;if(!o)return;const l=E(!0),s=[Ht(o,"click",d=>{const u=no(e),p=d.composedPath();!u||u===d.target||p.includes(u)||!l.value||r&&r.length>0&&r.some(f=>{const h=no(f);return h&&(d.target===h||p.includes(h))})||t(d)},{passive:!0,capture:a}),Ht(o,"pointerdown",d=>{const u=no(e);l.value=!!u&&!d.composedPath().includes(u)},{passive:!0})];return()=>s.forEach(d=>d())}const zd=typeof globalThis!="undefined"?globalThis:typeof window!="undefined"?window:typeof global!="undefined"?global:typeof self!="undefined"?self:{},Nd="__vueuse_ssr_handlers__";zd[Nd]=zd[Nd]||{};zd[Nd];function s4({document:e=i4}={}){if(!e)return E("visible");const t=E(e.visibilityState);return Ht(e,"visibilitychange",()=>{t.value=e.visibilityState}),t}var qh=Object.getOwnPropertySymbols,c4=Object.prototype.hasOwnProperty,d4=Object.prototype.propertyIsEnumerable,u4=(e,t)=>{var n={};for(var o in e)c4.call(e,o)&&t.indexOf(o)<0&&(n[o]=e[o]);if(e!=null&&qh)for(var o of qh(e))t.indexOf(o)<0&&d4.call(e,o)&&(n[o]=e[o]);return n};function Ba(e,t,n={}){const o=n,{window:r=oi}=o,a=u4(o,["window"]);let l;const i=r&&"ResizeObserver"in r,s=()=>{l&&(l.disconnect(),l=void 0)},c=ge(()=>no(e),u=>{s(),i&&r&&u&&(l=new ResizeObserver(t),l.observe(u,a))},{immediate:!0,flush:"post"}),d=()=>{s(),c()};return oc(d),{isSupported:i,stop:d}}function Kh(e,t={}){const{reset:n=!0,windowResize:o=!0,windowScroll:r=!0}=t,a=E(0),l=E(0),i=E(0),s=E(0),c=E(0),d=E(0),u=E(0),p=E(0);function f(){const h=no(e);if(!h){n&&(a.value=0,l.value=0,i.value=0,s.value=0,c.value=0,d.value=0,u.value=0,p.value=0);return}const b=h.getBoundingClientRect();a.value=b.height,l.value=b.bottom,i.value=b.left,s.value=b.right,c.value=b.top,d.value=b.width,u.value=b.x,p.value=b.y}return Ba(e,f),ge(()=>no(e),h=>!h&&f()),r&&Ht("scroll",f,{passive:!0}),o&&Ht("resize",f,{passive:!0}),{height:a,bottom:l,left:i,right:s,top:c,width:d,x:u,y:p,update:f}}var Wh,Uh;dt&&(window==null?void 0:window.navigator)&&((Wh=window==null?void 0:window.navigator)==null?void 0:Wh.platform)&&/iP(ad|hone|od)/.test((Uh=window==null?void 0:window.navigator)==null?void 0:Uh.platform);function p4({window:e=oi}={}){if(!e)return E(!1);const t=E(e.document.hasFocus());return Ht(e,"blur",()=>{t.value=!1}),Ht(e,"focus",()=>{t.value=!0}),t}function f4({window:e=oi,initialWidth:t=1/0,initialHeight:n=1/0}={}){const o=E(t),r=E(n),a=()=>{e&&(o.value=e.innerWidth,r.value=e.innerHeight)};return a(),l4(a),Ht("resize",a,{passive:!0}),{width:o,height:r}}const h4=(e,t)=>{if(!dt||!e||!t)return!1;const n=e.getBoundingClientRect();let o;return t instanceof Element?o=t.getBoundingClientRect():o={top:0,right:window.innerWidth,bottom:window.innerHeight,left:0},n.topo.top&&n.right>o.left&&n.left{let t=0,n=e;for(;n;)t+=n.offsetTop,n=n.offsetParent;return t},m4=(e,t)=>Math.abs(Yh(e)-Yh(t)),rp=e=>{let t,n;return e.type==="touchend"?(n=e.changedTouches[0].clientY,t=e.changedTouches[0].clientX):e.type.startsWith("touch")?(n=e.touches[0].clientY,t=e.touches[0].clientX):(n=e.clientY,t=e.clientX),{clientX:t,clientY:n}},g4=function(e){for(const t of e){const n=t.target.__resizeListeners__||[];n.length&&n.forEach(o=>{o()})}},ja=function(e,t){!dt||!e||(e.__resizeListeners__||(e.__resizeListeners__=[],e.__ro__=new ResizeObserver(g4),e.__ro__.observe(e)),e.__resizeListeners__.push(t))},Ha=function(e,t){var n;!e||!e.__resizeListeners__||(e.__resizeListeners__.splice(e.__resizeListeners__.indexOf(t),1),e.__resizeListeners__.length||(n=e.__ro__)==null||n.disconnect())},Cn=e=>e===void 0,Bl=e=>!e&&e!==0||Ye(e)&&e.length===0||ut(e)&&!Object.keys(e).length,Hr=e=>typeof Element=="undefined"?!1:e instanceof Element,b4=e=>op(e),v4=(e="")=>e.replace(/[|\\{}()[\]^$+*?.]/g,"\\$&").replace(/-/g,"\\x2d"),Id=e=>Object.keys(e),y4=e=>Object.entries(e),Bi=(e,t,n)=>({get value(){return Ot(e,t,n)},set value(o){R$(e,t,o)}}),Yv=(e="")=>e.split(" ").filter(t=>!!t.trim()),oo=(e,t)=>{if(!e||!t)return!1;if(t.includes(" "))throw new Error("className should not contain space.");return e.classList.contains(t)},bo=(e,t)=>{!e||!t.trim()||e.classList.add(...Yv(t))},hn=(e,t)=>{!e||!t.trim()||e.classList.remove(...Yv(t))},go=(e,t)=>{var n;if(!dt||!e||!t)return"";Bn(t);try{const o=e.style[t];if(o)return o;const r=(n=document.defaultView)==null?void 0:n.getComputedStyle(e,"");return r?r[t]:""}catch{return e.style[t]}},_4=(e,t)=>{if(!dt)return!1;const n={undefined:"overflow",true:"overflow-y",false:"overflow-x"}[String(t)],o=go(e,n);return["scroll","auto","overlay"].some(r=>o.includes(r))},ap=(e,t)=>{if(!dt)return;let n=e;for(;n;){if([window,document,document.documentElement].includes(n))return window;if(_4(n,t))return n;n=n.parentNode}return n};let ki;const w4=()=>{var e;if(!dt)return 0;if(ki!==void 0)return ki;const t=document.createElement("div");t.className="el-scrollbar__wrap",t.style.visibility="hidden",t.style.width="100px",t.style.position="absolute",t.style.top="-9999px",document.body.appendChild(t);const n=t.offsetWidth;t.style.overflow="scroll";const o=document.createElement("div");o.style.width="100%",t.appendChild(o);const r=o.offsetWidth;return(e=t.parentNode)==null||e.removeChild(t),ki=n-r,ki};function Gv(e,t){if(!dt)return;if(!t){e.scrollTop=0;return}const n=[];let o=t.offsetParent;for(;o!==null&&e!==o&&e.contains(o);)n.push(o),o=o.offsetParent;const r=t.offsetTop+n.reduce((s,c)=>s+c.offsetTop,0),a=r+t.offsetHeight,l=e.scrollTop,i=l+e.clientHeight;ri&&(e.scrollTop=a-e.clientHeight)}var yt=(e,t)=>{const n=e.__vccOpts||e;for(const[o,r]of t)n[o]=r;return n};const x4=ee({name:"ArrowDown"}),k4={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},T4=M("path",{fill:"currentColor",d:"M831.872 340.864 512 652.672 192.128 340.864a30.592 30.592 0 0 0-42.752 0 29.12 29.12 0 0 0 0 41.6L489.664 714.24a32 32 0 0 0 44.672 0l340.288-331.712a29.12 29.12 0 0 0 0-41.728 30.592 30.592 0 0 0-42.752 0z"},null,-1),C4=[T4];function S4(e,t,n,o,r,a){return x(),N("svg",k4,C4)}var Gr=yt(x4,[["render",S4]]);const $4=ee({name:"ArrowLeft"}),E4={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},A4=M("path",{fill:"currentColor",d:"M609.408 149.376 277.76 489.6a32 32 0 0 0 0 44.672l331.648 340.352a29.12 29.12 0 0 0 41.728 0 30.592 30.592 0 0 0 0-42.752L339.264 511.936l311.872-319.872a30.592 30.592 0 0 0 0-42.688 29.12 29.12 0 0 0-41.728 0z"},null,-1),z4=[A4];function N4(e,t,n,o,r,a){return x(),N("svg",E4,z4)}var Xr=yt($4,[["render",N4]]);const I4=ee({name:"ArrowRight"}),M4={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},P4=M("path",{fill:"currentColor",d:"M340.864 149.312a30.592 30.592 0 0 0 0 42.752L652.736 512 340.864 831.872a30.592 30.592 0 0 0 0 42.752 29.12 29.12 0 0 0 41.728 0L714.24 534.336a32 32 0 0 0 0-44.672L382.592 149.376a29.12 29.12 0 0 0-41.728 0z"},null,-1),O4=[P4];function R4(e,t,n,o,r,a){return x(),N("svg",M4,O4)}var Yn=yt(I4,[["render",R4]]);const D4=ee({name:"ArrowUp"}),F4={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},L4=M("path",{fill:"currentColor",d:"m488.832 344.32-339.84 356.672a32 32 0 0 0 0 44.16l.384.384a29.44 29.44 0 0 0 42.688 0l320-335.872 319.872 335.872a29.44 29.44 0 0 0 42.688 0l.384-.384a32 32 0 0 0 0-44.16L535.168 344.32a32 32 0 0 0-46.336 0z"},null,-1),V4=[L4];function B4(e,t,n,o,r,a){return x(),N("svg",F4,V4)}var ri=yt(D4,[["render",B4]]);const j4=ee({name:"Back"}),H4={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},q4=M("path",{fill:"currentColor",d:"M224 480h640a32 32 0 1 1 0 64H224a32 32 0 0 1 0-64z"},null,-1),K4=M("path",{fill:"currentColor",d:"m237.248 512 265.408 265.344a32 32 0 0 1-45.312 45.312l-288-288a32 32 0 0 1 0-45.312l288-288a32 32 0 1 1 45.312 45.312L237.248 512z"},null,-1),W4=[q4,K4];function U4(e,t,n,o,r,a){return x(),N("svg",H4,W4)}var Y4=yt(j4,[["render",U4]]);const G4=ee({name:"Calendar"}),X4={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},Z4=M("path",{fill:"currentColor",d:"M128 384v512h768V192H768v32a32 32 0 1 1-64 0v-32H320v32a32 32 0 0 1-64 0v-32H128v128h768v64H128zm192-256h384V96a32 32 0 1 1 64 0v32h160a32 32 0 0 1 32 32v768a32 32 0 0 1-32 32H96a32 32 0 0 1-32-32V160a32 32 0 0 1 32-32h160V96a32 32 0 0 1 64 0v32zm-32 384h64a32 32 0 0 1 0 64h-64a32 32 0 0 1 0-64zm0 192h64a32 32 0 1 1 0 64h-64a32 32 0 1 1 0-64zm192-192h64a32 32 0 0 1 0 64h-64a32 32 0 0 1 0-64zm0 192h64a32 32 0 1 1 0 64h-64a32 32 0 1 1 0-64zm192-192h64a32 32 0 1 1 0 64h-64a32 32 0 1 1 0-64zm0 192h64a32 32 0 1 1 0 64h-64a32 32 0 1 1 0-64z"},null,-1),J4=[Z4];function Q4(e,t,n,o,r,a){return x(),N("svg",X4,J4)}var eE=yt(G4,[["render",Q4]]);const tE=ee({name:"CaretRight"}),nE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},oE=M("path",{fill:"currentColor",d:"M384 192v640l384-320.064z"},null,-1),rE=[oE];function aE(e,t,n,o,r,a){return x(),N("svg",nE,rE)}var Xv=yt(tE,[["render",aE]]);const lE=ee({name:"CaretTop"}),iE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},sE=M("path",{fill:"currentColor",d:"M512 320 192 704h639.936z"},null,-1),cE=[sE];function dE(e,t,n,o,r,a){return x(),N("svg",iE,cE)}var uE=yt(lE,[["render",dE]]);const pE=ee({name:"Check"}),fE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},hE=M("path",{fill:"currentColor",d:"M406.656 706.944 195.84 496.256a32 32 0 1 0-45.248 45.248l256 256 512-512a32 32 0 0 0-45.248-45.248L406.592 706.944z"},null,-1),mE=[hE];function gE(e,t,n,o,r,a){return x(),N("svg",fE,mE)}var Ca=yt(pE,[["render",gE]]);const bE=ee({name:"CircleCheckFilled"}),vE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},yE=M("path",{fill:"currentColor",d:"M512 64a448 448 0 1 1 0 896 448 448 0 0 1 0-896zm-55.808 536.384-99.52-99.584a38.4 38.4 0 1 0-54.336 54.336l126.72 126.72a38.272 38.272 0 0 0 54.336 0l262.4-262.464a38.4 38.4 0 1 0-54.272-54.336L456.192 600.384z"},null,-1),_E=[yE];function wE(e,t,n,o,r,a){return x(),N("svg",vE,_E)}var xE=yt(bE,[["render",wE]]);const kE=ee({name:"CircleCheck"}),TE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},CE=M("path",{fill:"currentColor",d:"M512 896a384 384 0 1 0 0-768 384 384 0 0 0 0 768zm0 64a448 448 0 1 1 0-896 448 448 0 0 1 0 896z"},null,-1),SE=M("path",{fill:"currentColor",d:"M745.344 361.344a32 32 0 0 1 45.312 45.312l-288 288a32 32 0 0 1-45.312 0l-160-160a32 32 0 1 1 45.312-45.312L480 626.752l265.344-265.408z"},null,-1),$E=[CE,SE];function EE(e,t,n,o,r,a){return x(),N("svg",TE,$E)}var Ss=yt(kE,[["render",EE]]);const AE=ee({name:"CircleCloseFilled"}),zE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},NE=M("path",{fill:"currentColor",d:"M512 64a448 448 0 1 1 0 896 448 448 0 0 1 0-896zm0 393.664L407.936 353.6a38.4 38.4 0 1 0-54.336 54.336L457.664 512 353.6 616.064a38.4 38.4 0 1 0 54.336 54.336L512 566.336 616.064 670.4a38.4 38.4 0 1 0 54.336-54.336L566.336 512 670.4 407.936a38.4 38.4 0 1 0-54.336-54.336L512 457.664z"},null,-1),IE=[NE];function ME(e,t,n,o,r,a){return x(),N("svg",zE,IE)}var lp=yt(AE,[["render",ME]]);const PE=ee({name:"CircleClose"}),OE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},RE=M("path",{fill:"currentColor",d:"m466.752 512-90.496-90.496a32 32 0 0 1 45.248-45.248L512 466.752l90.496-90.496a32 32 0 1 1 45.248 45.248L557.248 512l90.496 90.496a32 32 0 1 1-45.248 45.248L512 557.248l-90.496 90.496a32 32 0 0 1-45.248-45.248L466.752 512z"},null,-1),DE=M("path",{fill:"currentColor",d:"M512 896a384 384 0 1 0 0-768 384 384 0 0 0 0 768zm0 64a448 448 0 1 1 0-896 448 448 0 0 1 0 896z"},null,-1),FE=[RE,DE];function LE(e,t,n,o,r,a){return x(),N("svg",OE,FE)}var Ro=yt(PE,[["render",LE]]);const VE=ee({name:"Clock"}),BE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},jE=M("path",{fill:"currentColor",d:"M512 896a384 384 0 1 0 0-768 384 384 0 0 0 0 768zm0 64a448 448 0 1 1 0-896 448 448 0 0 1 0 896z"},null,-1),HE=M("path",{fill:"currentColor",d:"M480 256a32 32 0 0 1 32 32v256a32 32 0 0 1-64 0V288a32 32 0 0 1 32-32z"},null,-1),qE=M("path",{fill:"currentColor",d:"M480 512h256q32 0 32 32t-32 32H480q-32 0-32-32t32-32z"},null,-1),KE=[jE,HE,qE];function WE(e,t,n,o,r,a){return x(),N("svg",BE,KE)}var Zv=yt(VE,[["render",WE]]);const UE=ee({name:"Close"}),YE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},GE=M("path",{fill:"currentColor",d:"M764.288 214.592 512 466.88 259.712 214.592a31.936 31.936 0 0 0-45.12 45.12L466.752 512 214.528 764.224a31.936 31.936 0 1 0 45.12 45.184L512 557.184l252.288 252.288a31.936 31.936 0 0 0 45.12-45.12L557.12 512.064l252.288-252.352a31.936 31.936 0 1 0-45.12-45.184z"},null,-1),XE=[GE];function ZE(e,t,n,o,r,a){return x(),N("svg",YE,XE)}var Hn=yt(UE,[["render",ZE]]);const JE=ee({name:"DArrowLeft"}),QE={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},eA=M("path",{fill:"currentColor",d:"M529.408 149.376a29.12 29.12 0 0 1 41.728 0 30.592 30.592 0 0 1 0 42.688L259.264 511.936l311.872 319.936a30.592 30.592 0 0 1-.512 43.264 29.12 29.12 0 0 1-41.216-.512L197.76 534.272a32 32 0 0 1 0-44.672l331.648-340.224zm256 0a29.12 29.12 0 0 1 41.728 0 30.592 30.592 0 0 1 0 42.688L515.264 511.936l311.872 319.936a30.592 30.592 0 0 1-.512 43.264 29.12 29.12 0 0 1-41.216-.512L453.76 534.272a32 32 0 0 1 0-44.672l331.648-340.224z"},null,-1),tA=[eA];function nA(e,t,n,o,r,a){return x(),N("svg",QE,tA)}var rc=yt(JE,[["render",nA]]);const oA=ee({name:"DArrowRight"}),rA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},aA=M("path",{fill:"currentColor",d:"M452.864 149.312a29.12 29.12 0 0 1 41.728.064L826.24 489.664a32 32 0 0 1 0 44.672L494.592 874.624a29.12 29.12 0 0 1-41.728 0 30.592 30.592 0 0 1 0-42.752L764.736 512 452.864 192a30.592 30.592 0 0 1 0-42.688zm-256 0a29.12 29.12 0 0 1 41.728.064L570.24 489.664a32 32 0 0 1 0 44.672L238.592 874.624a29.12 29.12 0 0 1-41.728 0 30.592 30.592 0 0 1 0-42.752L508.736 512 196.864 192a30.592 30.592 0 0 1 0-42.688z"},null,-1),lA=[aA];function iA(e,t,n,o,r,a){return x(),N("svg",rA,lA)}var ac=yt(oA,[["render",iA]]);const sA=ee({name:"Delete"}),cA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},dA=M("path",{fill:"currentColor",d:"M160 256H96a32 32 0 0 1 0-64h256V95.936a32 32 0 0 1 32-32h256a32 32 0 0 1 32 32V192h256a32 32 0 1 1 0 64h-64v672a32 32 0 0 1-32 32H192a32 32 0 0 1-32-32V256zm448-64v-64H416v64h192zM224 896h576V256H224v640zm192-128a32 32 0 0 1-32-32V416a32 32 0 0 1 64 0v320a32 32 0 0 1-32 32zm192 0a32 32 0 0 1-32-32V416a32 32 0 0 1 64 0v320a32 32 0 0 1-32 32z"},null,-1),uA=[dA];function pA(e,t,n,o,r,a){return x(),N("svg",cA,uA)}var fA=yt(sA,[["render",pA]]);const hA=ee({name:"Document"}),mA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},gA=M("path",{fill:"currentColor",d:"M832 384H576V128H192v768h640V384zm-26.496-64L640 154.496V320h165.504zM160 64h480l256 256v608a32 32 0 0 1-32 32H160a32 32 0 0 1-32-32V96a32 32 0 0 1 32-32zm160 448h384v64H320v-64zm0-192h160v64H320v-64zm0 384h384v64H320v-64z"},null,-1),bA=[gA];function vA(e,t,n,o,r,a){return x(),N("svg",mA,bA)}var yA=yt(hA,[["render",vA]]);const _A=ee({name:"FullScreen"}),wA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},xA=M("path",{fill:"currentColor",d:"m160 96.064 192 .192a32 32 0 0 1 0 64l-192-.192V352a32 32 0 0 1-64 0V96h64v.064zm0 831.872V928H96V672a32 32 0 1 1 64 0v191.936l192-.192a32 32 0 1 1 0 64l-192 .192zM864 96.064V96h64v256a32 32 0 1 1-64 0V160.064l-192 .192a32 32 0 1 1 0-64l192-.192zm0 831.872-192-.192a32 32 0 0 1 0-64l192 .192V672a32 32 0 1 1 64 0v256h-64v-.064z"},null,-1),kA=[xA];function TA(e,t,n,o,r,a){return x(),N("svg",wA,kA)}var CA=yt(_A,[["render",TA]]);const SA=ee({name:"Hide"}),$A={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},EA=M("path",{d:"M876.8 156.8c0-9.6-3.2-16-9.6-22.4-6.4-6.4-12.8-9.6-22.4-9.6-9.6 0-16 3.2-22.4 9.6L736 220.8c-64-32-137.6-51.2-224-60.8-160 16-288 73.6-377.6 176C44.8 438.4 0 496 0 512s48 73.6 134.4 176c22.4 25.6 44.8 48 73.6 67.2l-86.4 89.6c-6.4 6.4-9.6 12.8-9.6 22.4 0 9.6 3.2 16 9.6 22.4 6.4 6.4 12.8 9.6 22.4 9.6 9.6 0 16-3.2 22.4-9.6l704-710.4c3.2-6.4 6.4-12.8 6.4-22.4Zm-646.4 528c-76.8-70.4-128-128-153.6-172.8 28.8-48 80-105.6 153.6-172.8C304 272 400 230.4 512 224c64 3.2 124.8 19.2 176 44.8l-54.4 54.4C598.4 300.8 560 288 512 288c-64 0-115.2 22.4-160 64s-64 96-64 160c0 48 12.8 89.6 35.2 124.8L256 707.2c-9.6-6.4-19.2-16-25.6-22.4Zm140.8-96c-12.8-22.4-19.2-48-19.2-76.8 0-44.8 16-83.2 48-112 32-28.8 67.2-48 112-48 28.8 0 54.4 6.4 73.6 19.2L371.2 588.8ZM889.599 336c-12.8-16-28.8-28.8-41.6-41.6l-48 48c73.6 67.2 124.8 124.8 150.4 169.6-28.8 48-80 105.6-153.6 172.8-73.6 67.2-172.8 108.8-284.8 115.2-51.2-3.2-99.2-12.8-140.8-28.8l-48 48c57.6 22.4 118.4 38.4 188.8 44.8 160-16 288-73.6 377.6-176C979.199 585.6 1024 528 1024 512s-48.001-73.6-134.401-176Z",fill:"currentColor"},null,-1),AA=M("path",{d:"M511.998 672c-12.8 0-25.6-3.2-38.4-6.4l-51.2 51.2c28.8 12.8 57.6 19.2 89.6 19.2 64 0 115.2-22.4 160-64 41.6-41.6 64-96 64-160 0-32-6.4-64-19.2-89.6l-51.2 51.2c3.2 12.8 6.4 25.6 6.4 38.4 0 44.8-16 83.2-48 112-32 28.8-67.2 48-112 48Z",fill:"currentColor"},null,-1),zA=[EA,AA];function NA(e,t,n,o,r,a){return x(),N("svg",$A,zA)}var IA=yt(SA,[["render",NA]]);const MA=ee({name:"InfoFilled"}),PA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},OA=M("path",{fill:"currentColor",d:"M512 64a448 448 0 1 1 0 896.064A448 448 0 0 1 512 64zm67.2 275.072c33.28 0 60.288-23.104 60.288-57.344s-27.072-57.344-60.288-57.344c-33.28 0-60.16 23.104-60.16 57.344s26.88 57.344 60.16 57.344zM590.912 699.2c0-6.848 2.368-24.64 1.024-34.752l-52.608 60.544c-10.88 11.456-24.512 19.392-30.912 17.28a12.992 12.992 0 0 1-8.256-14.72l87.68-276.992c7.168-35.136-12.544-67.2-54.336-71.296-44.096 0-108.992 44.736-148.48 101.504 0 6.784-1.28 23.68.064 33.792l52.544-60.608c10.88-11.328 23.552-19.328 29.952-17.152a12.8 12.8 0 0 1 7.808 16.128L388.48 728.576c-10.048 32.256 8.96 63.872 55.04 71.04 67.84 0 107.904-43.648 147.456-100.416z"},null,-1),RA=[OA];function DA(e,t,n,o,r,a){return x(),N("svg",PA,RA)}var ip=yt(MA,[["render",DA]]);const FA=ee({name:"Loading"}),LA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},VA=M("path",{fill:"currentColor",d:"M512 64a32 32 0 0 1 32 32v192a32 32 0 0 1-64 0V96a32 32 0 0 1 32-32zm0 640a32 32 0 0 1 32 32v192a32 32 0 1 1-64 0V736a32 32 0 0 1 32-32zm448-192a32 32 0 0 1-32 32H736a32 32 0 1 1 0-64h192a32 32 0 0 1 32 32zm-640 0a32 32 0 0 1-32 32H96a32 32 0 0 1 0-64h192a32 32 0 0 1 32 32zM195.2 195.2a32 32 0 0 1 45.248 0L376.32 331.008a32 32 0 0 1-45.248 45.248L195.2 240.448a32 32 0 0 1 0-45.248zm452.544 452.544a32 32 0 0 1 45.248 0L828.8 783.552a32 32 0 0 1-45.248 45.248L647.744 692.992a32 32 0 0 1 0-45.248zM828.8 195.264a32 32 0 0 1 0 45.184L692.992 376.32a32 32 0 0 1-45.248-45.248l135.808-135.808a32 32 0 0 1 45.248 0zm-452.544 452.48a32 32 0 0 1 0 45.248L240.448 828.8a32 32 0 0 1-45.248-45.248l135.808-135.808a32 32 0 0 1 45.248 0z"},null,-1),BA=[VA];function jA(e,t,n,o,r,a){return x(),N("svg",LA,BA)}var hr=yt(FA,[["render",jA]]);const HA=ee({name:"Minus"}),qA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},KA=M("path",{fill:"currentColor",d:"M128 544h768a32 32 0 1 0 0-64H128a32 32 0 0 0 0 64z"},null,-1),WA=[KA];function UA(e,t,n,o,r,a){return x(),N("svg",qA,WA)}var YA=yt(HA,[["render",UA]]);const GA=ee({name:"MoreFilled"}),XA={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},ZA=M("path",{fill:"currentColor",d:"M176 416a112 112 0 1 1 0 224 112 112 0 0 1 0-224zm336 0a112 112 0 1 1 0 224 112 112 0 0 1 0-224zm336 0a112 112 0 1 1 0 224 112 112 0 0 1 0-224z"},null,-1),JA=[ZA];function QA(e,t,n,o,r,a){return x(),N("svg",XA,JA)}var e5=yt(GA,[["render",QA]]);const t5=ee({name:"More"}),n5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},o5=M("path",{fill:"currentColor",d:"M176 416a112 112 0 1 0 0 224 112 112 0 0 0 0-224m0 64a48 48 0 1 1 0 96 48 48 0 0 1 0-96zm336-64a112 112 0 1 1 0 224 112 112 0 0 1 0-224zm0 64a48 48 0 1 0 0 96 48 48 0 0 0 0-96zm336-64a112 112 0 1 1 0 224 112 112 0 0 1 0-224zm0 64a48 48 0 1 0 0 96 48 48 0 0 0 0-96z"},null,-1),r5=[o5];function a5(e,t,n,o,r,a){return x(),N("svg",n5,r5)}var l5=yt(t5,[["render",a5]]);const i5=ee({name:"PictureFilled"}),s5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},c5=M("path",{fill:"currentColor",d:"M96 896a32 32 0 0 1-32-32V160a32 32 0 0 1 32-32h832a32 32 0 0 1 32 32v704a32 32 0 0 1-32 32H96zm315.52-228.48-68.928-68.928a32 32 0 0 0-45.248 0L128 768.064h778.688l-242.112-290.56a32 32 0 0 0-49.216 0L458.752 665.408a32 32 0 0 1-47.232 2.112zM256 384a96 96 0 1 0 192.064-.064A96 96 0 0 0 256 384z"},null,-1),d5=[c5];function u5(e,t,n,o,r,a){return x(),N("svg",s5,d5)}var p5=yt(i5,[["render",u5]]);const f5=ee({name:"Plus"}),h5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},m5=M("path",{fill:"currentColor",d:"M480 480V128a32 32 0 0 1 64 0v352h352a32 32 0 1 1 0 64H544v352a32 32 0 1 1-64 0V544H128a32 32 0 0 1 0-64h352z"},null,-1),g5=[m5];function b5(e,t,n,o,r,a){return x(),N("svg",h5,g5)}var Jv=yt(f5,[["render",b5]]);const v5=ee({name:"QuestionFilled"}),y5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},_5=M("path",{fill:"currentColor",d:"M512 64a448 448 0 1 1 0 896 448 448 0 0 1 0-896zm23.744 191.488c-52.096 0-92.928 14.784-123.2 44.352-30.976 29.568-45.76 70.4-45.76 122.496h80.256c0-29.568 5.632-52.8 17.6-68.992 13.376-19.712 35.2-28.864 66.176-28.864 23.936 0 42.944 6.336 56.32 19.712 12.672 13.376 19.712 31.68 19.712 54.912 0 17.6-6.336 34.496-19.008 49.984l-8.448 9.856c-45.76 40.832-73.216 70.4-82.368 89.408-9.856 19.008-14.08 42.24-14.08 68.992v9.856h80.96v-9.856c0-16.896 3.52-31.68 10.56-45.76 6.336-12.672 15.488-24.64 28.16-35.2 33.792-29.568 54.208-48.576 60.544-55.616 16.896-22.528 26.048-51.392 26.048-86.592 0-42.944-14.08-76.736-42.24-101.376-28.16-25.344-65.472-37.312-111.232-37.312zm-12.672 406.208a54.272 54.272 0 0 0-38.72 14.784 49.408 49.408 0 0 0-15.488 38.016c0 15.488 4.928 28.16 15.488 38.016A54.848 54.848 0 0 0 523.072 768c15.488 0 28.16-4.928 38.72-14.784a51.52 51.52 0 0 0 16.192-38.72 51.968 51.968 0 0 0-15.488-38.016 55.936 55.936 0 0 0-39.424-14.784z"},null,-1),w5=[_5];function x5(e,t,n,o,r,a){return x(),N("svg",y5,w5)}var k5=yt(v5,[["render",x5]]);const T5=ee({name:"RefreshLeft"}),C5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},S5=M("path",{fill:"currentColor",d:"M289.088 296.704h92.992a32 32 0 0 1 0 64H232.96a32 32 0 0 1-32-32V179.712a32 32 0 0 1 64 0v50.56a384 384 0 0 1 643.84 282.88 384 384 0 0 1-383.936 384 384 384 0 0 1-384-384h64a320 320 0 1 0 640 0 320 320 0 0 0-555.712-216.448z"},null,-1),$5=[S5];function E5(e,t,n,o,r,a){return x(),N("svg",C5,$5)}var A5=yt(T5,[["render",E5]]);const z5=ee({name:"RefreshRight"}),N5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},I5=M("path",{fill:"currentColor",d:"M784.512 230.272v-50.56a32 32 0 1 1 64 0v149.056a32 32 0 0 1-32 32H667.52a32 32 0 1 1 0-64h92.992A320 320 0 1 0 524.8 833.152a320 320 0 0 0 320-320h64a384 384 0 0 1-384 384 384 384 0 0 1-384-384 384 384 0 0 1 643.712-282.88z"},null,-1),M5=[I5];function P5(e,t,n,o,r,a){return x(),N("svg",N5,M5)}var O5=yt(z5,[["render",P5]]);const R5=ee({name:"ScaleToOriginal"}),D5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},F5=M("path",{fill:"currentColor",d:"M813.176 180.706a60.235 60.235 0 0 1 60.236 60.235v481.883a60.235 60.235 0 0 1-60.236 60.235H210.824a60.235 60.235 0 0 1-60.236-60.235V240.94a60.235 60.235 0 0 1 60.236-60.235h602.352zm0-60.235H210.824A120.47 120.47 0 0 0 90.353 240.94v481.883a120.47 120.47 0 0 0 120.47 120.47h602.353a120.47 120.47 0 0 0 120.471-120.47V240.94a120.47 120.47 0 0 0-120.47-120.47zm-120.47 180.705a30.118 30.118 0 0 0-30.118 30.118v301.177a30.118 30.118 0 0 0 60.236 0V331.294a30.118 30.118 0 0 0-30.118-30.118zm-361.412 0a30.118 30.118 0 0 0-30.118 30.118v301.177a30.118 30.118 0 1 0 60.236 0V331.294a30.118 30.118 0 0 0-30.118-30.118zM512 361.412a30.118 30.118 0 0 0-30.118 30.117v30.118a30.118 30.118 0 0 0 60.236 0V391.53A30.118 30.118 0 0 0 512 361.412zM512 512a30.118 30.118 0 0 0-30.118 30.118v30.117a30.118 30.118 0 0 0 60.236 0v-30.117A30.118 30.118 0 0 0 512 512z"},null,-1),L5=[F5];function V5(e,t,n,o,r,a){return x(),N("svg",D5,L5)}var B5=yt(R5,[["render",V5]]);const j5=ee({name:"Search"}),H5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},q5=M("path",{fill:"currentColor",d:"m795.904 750.72 124.992 124.928a32 32 0 0 1-45.248 45.248L750.656 795.904a416 416 0 1 1 45.248-45.248zM480 832a352 352 0 1 0 0-704 352 352 0 0 0 0 704z"},null,-1),K5=[q5];function W5(e,t,n,o,r,a){return x(),N("svg",H5,K5)}var U5=yt(j5,[["render",W5]]);const Y5=ee({name:"StarFilled"}),G5={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},X5=M("path",{fill:"currentColor",d:"M283.84 867.84 512 747.776l228.16 119.936a6.4 6.4 0 0 0 9.28-6.72l-43.52-254.08 184.512-179.904a6.4 6.4 0 0 0-3.52-10.88l-255.104-37.12L517.76 147.904a6.4 6.4 0 0 0-11.52 0L392.192 379.072l-255.104 37.12a6.4 6.4 0 0 0-3.52 10.88L318.08 606.976l-43.584 254.08a6.4 6.4 0 0 0 9.28 6.72z"},null,-1),Z5=[X5];function J5(e,t,n,o,r,a){return x(),N("svg",G5,Z5)}var Ti=yt(Y5,[["render",J5]]);const Q5=ee({name:"Star"}),ez={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},tz=M("path",{fill:"currentColor",d:"m512 747.84 228.16 119.936a6.4 6.4 0 0 0 9.28-6.72l-43.52-254.08 184.512-179.904a6.4 6.4 0 0 0-3.52-10.88l-255.104-37.12L517.76 147.904a6.4 6.4 0 0 0-11.52 0L392.192 379.072l-255.104 37.12a6.4 6.4 0 0 0-3.52 10.88L318.08 606.976l-43.584 254.08a6.4 6.4 0 0 0 9.28 6.72L512 747.84zM313.6 924.48a70.4 70.4 0 0 1-102.144-74.24l37.888-220.928L88.96 472.96A70.4 70.4 0 0 1 128 352.896l221.76-32.256 99.2-200.96a70.4 70.4 0 0 1 126.208 0l99.2 200.96 221.824 32.256a70.4 70.4 0 0 1 39.04 120.064L774.72 629.376l37.888 220.928a70.4 70.4 0 0 1-102.144 74.24L512 820.096l-198.4 104.32z"},null,-1),nz=[tz];function oz(e,t,n,o,r,a){return x(),N("svg",ez,nz)}var rz=yt(Q5,[["render",oz]]);const az=ee({name:"SuccessFilled"}),lz={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},iz=M("path",{fill:"currentColor",d:"M512 64a448 448 0 1 1 0 896 448 448 0 0 1 0-896zm-55.808 536.384-99.52-99.584a38.4 38.4 0 1 0-54.336 54.336l126.72 126.72a38.272 38.272 0 0 0 54.336 0l262.4-262.464a38.4 38.4 0 1 0-54.272-54.336L456.192 600.384z"},null,-1),sz=[iz];function cz(e,t,n,o,r,a){return x(),N("svg",lz,sz)}var Qv=yt(az,[["render",cz]]);const dz=ee({name:"View"}),uz={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},pz=M("path",{fill:"currentColor",d:"M512 160c320 0 512 352 512 352S832 864 512 864 0 512 0 512s192-352 512-352zm0 64c-225.28 0-384.128 208.064-436.8 288 52.608 79.872 211.456 288 436.8 288 225.28 0 384.128-208.064 436.8-288-52.608-79.872-211.456-288-436.8-288zm0 64a224 224 0 1 1 0 448 224 224 0 0 1 0-448zm0 64a160.192 160.192 0 0 0-160 160c0 88.192 71.744 160 160 160s160-71.808 160-160-71.744-160-160-160z"},null,-1),fz=[pz];function hz(e,t,n,o,r,a){return x(),N("svg",uz,fz)}var mz=yt(dz,[["render",hz]]);const gz=ee({name:"WarningFilled"}),bz={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},vz=M("path",{fill:"currentColor",d:"M512 64a448 448 0 1 1 0 896 448 448 0 0 1 0-896zm0 192a58.432 58.432 0 0 0-58.24 63.744l23.36 256.384a35.072 35.072 0 0 0 69.76 0l23.296-256.384A58.432 58.432 0 0 0 512 256zm0 512a51.2 51.2 0 1 0 0-102.4 51.2 51.2 0 0 0 0 102.4z"},null,-1),yz=[vz];function _z(e,t,n,o,r,a){return x(),N("svg",bz,yz)}var jl=yt(gz,[["render",_z]]);const wz=ee({name:"ZoomIn"}),xz={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},kz=M("path",{fill:"currentColor",d:"m795.904 750.72 124.992 124.928a32 32 0 0 1-45.248 45.248L750.656 795.904a416 416 0 1 1 45.248-45.248zM480 832a352 352 0 1 0 0-704 352 352 0 0 0 0 704zm-32-384v-96a32 32 0 0 1 64 0v96h96a32 32 0 0 1 0 64h-96v96a32 32 0 0 1-64 0v-96h-96a32 32 0 0 1 0-64h96z"},null,-1),Tz=[kz];function Cz(e,t,n,o,r,a){return x(),N("svg",xz,Tz)}var ey=yt(wz,[["render",Cz]]);const Sz=ee({name:"ZoomOut"}),$z={viewBox:"0 0 1024 1024",xmlns:"http://www.w3.org/2000/svg"},Ez=M("path",{fill:"currentColor",d:"m795.904 750.72 124.992 124.928a32 32 0 0 1-45.248 45.248L750.656 795.904a416 416 0 1 1 45.248-45.248zM480 832a352 352 0 1 0 0-704 352 352 0 0 0 0 704zM352 448h256a32 32 0 0 1 0 64H352a32 32 0 0 1 0-64z"},null,-1),Az=[Ez];function zz(e,t,n,o,r,a){return x(),N("svg",$z,Az)}var Nz=yt(Sz,[["render",zz]]);const Md=Symbol(),Gh="__elPropsReservedKey";function uo(e,t){if(!ut(e)||!!e[Gh])return e;const{values:n,required:o,default:r,type:a,validator:l}=e,i=n||l?c=>{let d=!1,u=[];if(n&&(u=Array.from(n),it(e,"default")&&u.push(r),d||(d=u.includes(c))),l&&(d||(d=l(c))),!d&&u.length>0){const p=[...new Set(u)].map(f=>JSON.stringify(f)).join(", ");hw(`Invalid prop: validation failed${t?` for prop "${t}"`:""}. Expected one of [${p}], got value ${JSON.stringify(c)}.`)}return d}:void 0,s={type:ut(a)&&Object.getOwnPropertySymbols(a).includes(Md)?a[Md]:a,required:!!o,validator:i,[Gh]:!0};return it(e,"default")&&(s.default=r),s}const Le=e=>jv(Object.entries(e).map(([t,n])=>[t,uo(n,t)])),Te=e=>({[Md]:e}),an=Te([String,Object,Function]),Iz={Close:Hn},lc={Close:Hn,SuccessFilled:Qv,InfoFilled:ip,WarningFilled:jl,CircleCloseFilled:lp},Do={success:Qv,warning:jl,error:lp,info:ip},ty={validating:hr,success:Ss,error:Ro},rt=(e,t)=>{if(e.install=n=>{for(const o of[e,...Object.values(t!=null?t:{})])n.component(o.name,o)},t)for(const[n,o]of Object.entries(t))e[n]=o;return e},ny=(e,t)=>(e.install=n=>{e._context=n._context,n.config.globalProperties[t]=e},e),Ft=e=>(e.install=wt,e),sp=(...e)=>t=>{e.forEach(n=>{Je(n)?n(t):n.value=t})};class Mz extends Error{constructor(t){super(t),this.name="ElementPlusError"}}function Wt(e,t){throw new Mz(`[${e}] ${t}`)}function lo(e,t="px"){if(!e)return"";if(Qe(e))return e;if(mt(e))return`${e}${t}`}const Oe={tab:"Tab",enter:"Enter",space:"Space",left:"ArrowLeft",up:"ArrowUp",right:"ArrowRight",down:"ArrowDown",esc:"Escape",delete:"Delete",backspace:"Backspace",numpadEnter:"NumpadEnter",pageUp:"PageUp",pageDown:"PageDown",home:"Home",end:"End"},Pz=["year","month","date","dates","week","datetime","datetimerange","daterange","monthrange"],Mc=["sun","mon","tue","wed","thu","fri","sat"],tt="update:modelValue",Xt="change",pr="input",wo=["","default","small","large"],Oz={large:40,default:32,small:24},oy=(e="default")=>Oz[e||"default"],In=e=>["",...wo].includes(e),ry=e=>[...Pz].includes(e);var Rn=(e=>(e[e.TEXT=1]="TEXT",e[e.CLASS=2]="CLASS",e[e.STYLE=4]="STYLE",e[e.PROPS=8]="PROPS",e[e.FULL_PROPS=16]="FULL_PROPS",e[e.HYDRATE_EVENTS=32]="HYDRATE_EVENTS",e[e.STABLE_FRAGMENT=64]="STABLE_FRAGMENT",e[e.KEYED_FRAGMENT=128]="KEYED_FRAGMENT",e[e.UNKEYED_FRAGMENT=256]="UNKEYED_FRAGMENT",e[e.NEED_PATCH=512]="NEED_PATCH",e[e.DYNAMIC_SLOTS=1024]="DYNAMIC_SLOTS",e[e.HOISTED=-1]="HOISTED",e[e.BAIL=-2]="BAIL",e))(Rn||{});function ay(e){return jt(e)&&e.type===De}function Rz(e){return jt(e)&&e.type===dn}function Dz(e){return jt(e)&&!ay(e)&&!Rz(e)}const Fz=e=>{if(!jt(e))return{};const t=e.props||{},n=(jt(e.type)?e.type.props:void 0)||{},o={};return Object.keys(n).forEach(r=>{it(n[r],"default")&&(o[r]=n[r].default)}),Object.keys(t).forEach(r=>{o[Bn(r)]=t[r]}),o},Lz=e=>{if(!Ye(e)||e.length>1)throw new Error("expect to receive a single Vue element child");return e[0]},Xh=e=>e**3,Vz=e=>e<.5?Xh(e*2)/2:1-Xh((1-e)*2)/2,Zh=e=>[...new Set(e)],Rr=e=>!e&&e!==0?[]:Array.isArray(e)?e:[e],cp=()=>dt&&/firefox/i.test(window.navigator.userAgent),ic=e=>/([(\uAC00-\uD7AF)|(\u3130-\u318F)])+/gi.test(e),ly=e=>dt?window.requestAnimationFrame(e):setTimeout(e,16),iy=e=>dt?window.cancelAnimationFrame(e):clearTimeout(e),ai=()=>Math.floor(Math.random()*1e4),Dt=e=>e,Bz=["class","style"],jz=/^on[A-Z]/,dp=(e={})=>{const{excludeListeners:t=!1,excludeKeys:n=[]}=e,o=n.concat(Bz),r=nt();return C(r?()=>{var a;return jv(Object.entries((a=r.proxy)==null?void 0:a.$attrs).filter(([l])=>!o.includes(l)&&!(t&&jz.test(l))))}:()=>({}))},sy=Symbol("breadcrumbKey"),cy=Symbol("buttonGroupContextKey"),dy=Symbol("carouselContextKey"),uy=Symbol("collapseContextKey"),py=Symbol(),fy=Symbol("dialogInjectionKey"),Mn=Symbol("formContextKey"),qn=Symbol("formItemContextKey"),hy=Symbol("elPaginationKey"),my=Symbol("radioGroupKey"),gy=Symbol("rowContextKey"),by=Symbol("scrollbarContextKey"),sc=Symbol("tabsRootContextKey"),vy=Symbol("uploadContextKey"),up=Symbol("popper"),yy=Symbol("popperContent"),cc=Symbol("tooltipV2"),_y=Symbol("tooltipV2Content"),Pc="tooltip_v2.open",wy=e=>{const t=nt();return C(()=>{var n,o;return(o=(n=t.proxy)==null?void 0:n.$props[e])!=null?o:void 0})},$s=E();function qa(e,t=void 0){const n=nt()?Ne(py,$s):$s;return e?C(()=>{var o,r;return(r=(o=n.value)==null?void 0:o[e])!=null?r:t}):n}const xy=(e,t,n=!1)=>{var o;const r=!!nt(),a=r?qa():void 0,l=(o=t==null?void 0:t.provide)!=null?o:r?ot:void 0;if(!l)return;const i=C(()=>{const s=_(e);return a!=null&&a.value?Hz(a.value,s):s});return l(py,i),(n||!$s.value)&&($s.value=i.value),i},Hz=(e,t)=>{var n;const o=[...new Set([...Id(e),...Id(t)])],r={};for(const a of o)r[a]=(n=t[a])!=null?n:e[a];return r},dc=uo({type:String,values:wo,required:!1}),Ut=(e,t={})=>{const n=E(void 0),o=t.prop?n:wy("size"),r=t.global?n:qa("size"),a=t.form?{size:void 0}:Ne(Mn,void 0),l=t.formItem?{size:void 0}:Ne(qn,void 0);return C(()=>o.value||_(e)||(l==null?void 0:l.size)||(a==null?void 0:a.size)||r.value||"")},Zr=e=>{const t=wy("disabled"),n=Ne(Mn,void 0);return C(()=>t.value||_(e)||(n==null?void 0:n.disabled)||!1)},li=({from:e,replacement:t,scope:n,version:o,ref:r,type:a="API"},l)=>{ge(()=>_(l),i=>{},{immediate:!0})},ky=(e,t,n)=>{let o={offsetX:0,offsetY:0};const r=i=>{const s=i.clientX,c=i.clientY,{offsetX:d,offsetY:u}=o,p=e.value.getBoundingClientRect(),f=p.left,h=p.top,b=p.width,m=p.height,g=document.documentElement.clientWidth,v=document.documentElement.clientHeight,y=-f+d,T=-h+u,w=g-f-b+d,k=v-h-m+u,$=O=>{const R=Math.min(Math.max(d+O.clientX-s,y),w),F=Math.min(Math.max(u+O.clientY-c,T),k);o={offsetX:R,offsetY:F},e.value.style.transform=`translate(${lo(R)}, ${lo(F)})`},z=()=>{document.removeEventListener("mousemove",$),document.removeEventListener("mouseup",z)};document.addEventListener("mousemove",$),document.addEventListener("mouseup",z)},a=()=>{t.value&&e.value&&t.value.addEventListener("mousedown",r)},l=()=>{t.value&&e.value&&t.value.removeEventListener("mousedown",r)};et(()=>{Fn(()=>{n.value?a():l()})}),$t(()=>{l()})},qz=e=>({focus:()=>{var t,n;(n=(t=e.value)==null?void 0:t.focus)==null||n.call(t)}}),Ka=()=>{const e=Ne(Mn,void 0),t=Ne(qn,void 0);return{form:e,formItem:t}};var Kz={name:"en",el:{colorpicker:{confirm:"OK",clear:"Clear"},datepicker:{now:"Now",today:"Today",cancel:"Cancel",clear:"Clear",confirm:"OK",selectDate:"Select date",selectTime:"Select time",startDate:"Start Date",startTime:"Start Time",endDate:"End Date",endTime:"End Time",prevYear:"Previous Year",nextYear:"Next Year",prevMonth:"Previous Month",nextMonth:"Next Month",year:"",month1:"January",month2:"February",month3:"March",month4:"April",month5:"May",month6:"June",month7:"July",month8:"August",month9:"September",month10:"October",month11:"November",month12:"December",week:"week",weeks:{sun:"Sun",mon:"Mon",tue:"Tue",wed:"Wed",thu:"Thu",fri:"Fri",sat:"Sat"},months:{jan:"Jan",feb:"Feb",mar:"Mar",apr:"Apr",may:"May",jun:"Jun",jul:"Jul",aug:"Aug",sep:"Sep",oct:"Oct",nov:"Nov",dec:"Dec"}},select:{loading:"Loading",noMatch:"No matching data",noData:"No data",placeholder:"Select"},cascader:{noMatch:"No matching data",loading:"Loading",placeholder:"Select",noData:"No data"},pagination:{goto:"Go to",pagesize:"/page",total:"Total {total}",pageClassifier:"",deprecationWarning:"Deprecated usages detected, please refer to the el-pagination documentation for more details"},messagebox:{title:"Message",confirm:"OK",cancel:"Cancel",error:"Illegal input"},upload:{deleteTip:"press delete to remove",delete:"Delete",preview:"Preview",continue:"Continue"},table:{emptyText:"No Data",confirmFilter:"Confirm",resetFilter:"Reset",clearFilter:"All",sumText:"Sum"},tree:{emptyText:"No Data"},transfer:{noMatch:"No matching data",noData:"No data",titles:["List 1","List 2"],filterPlaceholder:"Enter keyword",noCheckedFormat:"{total} items",hasCheckedFormat:"{checked}/{total} checked"},image:{error:"FAILED"},pageHeader:{title:"Back"},popconfirm:{confirmButtonText:"Yes",cancelButtonText:"No"}}};const Wz=e=>(t,n)=>Uz(t,n,_(e)),Uz=(e,t,n)=>Ot(n,e,e).replace(/\{(\w+)\}/g,(o,r)=>{var a;return`${(a=t==null?void 0:t[r])!=null?a:`{${r}}`}`}),Yz=e=>{const t=C(()=>_(e).name),n=Vt(e)?e:E(e);return{lang:t,locale:n,t:Wz(e)}},Tt=()=>{const e=qa("locale");return Yz(C(()=>e.value||Kz))},Ty=e=>{if(Vt(e)||Wt("[useLockscreen]","You need to pass a ref param to this function"),!dt||oo(document.body,"el-popup-parent--hidden"))return;let t=0,n=!1,o="0",r=0;const a=()=>{hn(document.body,"el-popup-parent--hidden"),n&&(document.body.style.paddingRight=o)};ge(e,l=>{if(!l){a();return}n=!oo(document.body,"el-popup-parent--hidden"),n&&(o=document.body.style.paddingRight,r=Number.parseInt(go(document.body,"paddingRight"),10)),t=w4();const i=document.documentElement.clientHeight0&&(i||s==="scroll")&&n&&(document.body.style.paddingRight=`${r+t}px`),bo(document.body,"el-popup-parent--hidden")}),jg(()=>a())},ma=[],Gz=e=>{ma.length!==0&&e.code===Oe.esc&&(e.stopPropagation(),ma[ma.length-1].handleClose())},Cy=(e,t)=>{ge(t,n=>{n?ma.push(e):ma.splice(ma.indexOf(e),1)})};dt&&Ht(document,"keydown",Gz);const Xz=uo({type:Te(Boolean),default:null}),Zz=uo({type:Te(Function)}),Jz=e=>{const t={[e]:Xz,[`onUpdate:${e}`]:Zz},n=[`update:${e}`];return{useModelToggle:({indicator:r,shouldHideWhenRouteChanges:a,shouldProceed:l,onShow:i,onHide:s})=>{const c=nt(),d=c.props,{emit:u}=c,p=`update:${e}`,f=C(()=>Je(d[`onUpdate:${e}`])),h=C(()=>d[e]===null),b=()=>{r.value!==!0&&(r.value=!0,Je(i)&&i())},m=()=>{r.value!==!1&&(r.value=!1,Je(s)&&s())},g=()=>{if(d.disabled===!0||Je(l)&&!l())return;const w=f.value&&dt;w&&u(p,!0),(h.value||!w)&&b()},v=()=>{if(d.disabled===!0||!dt)return;const w=f.value&&dt;w&&u(p,!1),(h.value||!w)&&m()},y=w=>{!on(w)||(d.disabled&&w?f.value&&u(p,!1):r.value!==w&&(w?b():m()))},T=()=>{r.value?v():g()};return ge(()=>d[e],y),a&&c.appContext.config.globalProperties.$route!==void 0&&ge(()=>he({},c.proxy.$route),()=>{a.value&&r.value&&v()}),et(()=>{y(d[e])}),{hide:v,show:g,toggle:T}},useModelToggleProps:t,useModelToggleEmits:n}},Qz=(e,t,n)=>{const o=a=>{n(a)&&a.stopImmediatePropagation()};let r;ge(()=>e.value,a=>{a?r=Ht(document,t,o,!0):r==null||r()},{immediate:!0})},Sy=(e,t)=>{let n;ge(()=>e.value,o=>{var r,a;o?(n=document.activeElement,Vt(t)&&((a=(r=t.value).focus)==null||a.call(r))):n.focus()})},pp=e=>{if(!e)return{onClick:wt,onMousedown:wt,onMouseup:wt};let t=!1,n=!1;return{onClick:l=>{t&&n&&e(l),t=n=!1},onMousedown:l=>{t=l.target===l.currentTarget},onMouseup:l=>{n=l.target===l.currentTarget}}},eN=(e,t=0)=>{if(t===0)return e;const n=E(!1);let o=0;const r=()=>{o&&clearTimeout(o),o=window.setTimeout(()=>{n.value=e.value},t)};return et(r),ge(()=>e.value,a=>{a?r():n.value=a}),n};function tN(){let e;const t=(o,r)=>{n(),e=window.setTimeout(o,r)},n=()=>window.clearTimeout(e);return oc(()=>n()),{registerTimeout:t,cancelTimeout:n}}const nN={prefix:Math.floor(Math.random()*1e4),current:0},oN=Symbol("elIdInjection"),fp=e=>{const t=Ne(oN,nN);return C(()=>_(e)||`el-id-${t.prefix}-${t.current++}`)},rN=e=>{const t=n=>{const o=n;o.key===Oe.esc&&(e==null||e(o))};et(()=>{Et(document,"keydown",t)}),$t(()=>{Bt(document,"keydown",t)})};let Jh;const $y=`el-popper-container-${ai()}`,Ey=`#${$y}`,aN=()=>{const e=document.createElement("div");return e.id=$y,document.body.appendChild(e),e},lN=()=>{Jl(()=>{!dt||(!Jh||!document.body.querySelector(Ey))&&(Jh=aN())})},iN=Le({showAfter:{type:Number,default:0},hideAfter:{type:Number,default:200}}),sN=({showAfter:e,hideAfter:t,open:n,close:o})=>{const{registerTimeout:r}=tN();return{onOpen:()=>{r(()=>{n()},_(e))},onClose:()=>{r(()=>{o()},_(t))}}},Ay=Symbol("elForwardRef"),cN=e=>{ot(Ay,{setForwardRef:n=>{e.value=n}})},dN=e=>({mounted(t){e(t)},updated(t){e(t)},unmounted(){e(null)}}),uN="el",pN="is-",_r=(e,t,n,o,r)=>{let a=`${e}-${t}`;return n&&(a+=`-${n}`),o&&(a+=`__${o}`),r&&(a+=`--${r}`),a},ke=e=>{const t=qa("namespace"),n=C(()=>t.value||uN);return{namespace:n,b:(u="")=>_r(_(n),e,u,"",""),e:u=>u?_r(_(n),e,"",u,""):"",m:u=>u?_r(_(n),e,"","",u):"",be:(u,p)=>u&&p?_r(_(n),e,u,p,""):"",em:(u,p)=>u&&p?_r(_(n),e,"",u,p):"",bm:(u,p)=>u&&p?_r(_(n),e,u,"",p):"",bem:(u,p,f)=>u&&p&&f?_r(_(n),e,u,p,f):"",is:(u,...p)=>{const f=p.length>=1?p[0]:!0;return u&&f?`${pN}${u}`:""}}},Qh=E(0),jo=()=>{const e=qa("zIndex",2e3),t=C(()=>e.value+Qh.value);return{initialZIndex:e,currentZIndex:t,nextZIndex:()=>(Qh.value++,t.value)}};function hp(e){return e.split("-")[0]}function zy(e){return e.split("-")[1]}function mp(e){return["top","bottom"].includes(hp(e))?"x":"y"}function Ny(e){return e==="y"?"height":"width"}function em(e,t,n){let{reference:o,floating:r}=e;const a=o.x+o.width/2-r.width/2,l=o.y+o.height/2-r.height/2,i=mp(t),s=Ny(i),c=o[s]/2-r[s]/2,d=i==="x";let u;switch(hp(t)){case"top":u={x:a,y:o.y-r.height};break;case"bottom":u={x:a,y:o.y+o.height};break;case"right":u={x:o.x+o.width,y:l};break;case"left":u={x:o.x-r.width,y:l};break;default:u={x:o.x,y:o.y}}switch(zy(t)){case"start":u[i]-=c*(n&&d?-1:1);break;case"end":u[i]+=c*(n&&d?-1:1)}return u}const fN=async(e,t,n)=>{const{placement:o="bottom",strategy:r="absolute",middleware:a=[],platform:l}=n,i=await(l.isRTL==null?void 0:l.isRTL(t));let s=await l.getElementRects({reference:e,floating:t,strategy:r}),{x:c,y:d}=em(s,o,i),u=o,p={};for(let f=0;f({name:"arrow",options:e,async fn(t){const{element:n,padding:o=0}=e!=null?e:{},{x:r,y:a,placement:l,rects:i,platform:s}=t;if(n==null)return{};const c=hN(o),d={x:r,y:a},u=mp(l),p=Ny(u),f=await s.getDimensions(n),h=u==="y"?"top":"left",b=u==="y"?"bottom":"right",m=i.reference[p]+i.reference[u]-d[u]-i.floating[p],g=d[u]-i.reference[u],v=await(s.getOffsetParent==null?void 0:s.getOffsetParent(n)),y=v?u==="y"?v.clientHeight||0:v.clientWidth||0:0,T=m/2-g/2,w=c[h],k=y-f[p]-c[b],$=y/2-f[p]/2+T,z=bN(w,$,k);return{data:{[u]:z,centerOffset:$-z}}}}),yN=["top","right","bottom","left"];yN.reduce((e,t)=>e.concat(t,t+"-start",t+"-end"),[]);const _N=function(e){return e===void 0&&(e=0),{name:"offset",options:e,async fn(t){const{x:n,y:o,placement:r,rects:a,platform:l,elements:i}=t,s=function(c,d,u,p){p===void 0&&(p=!1);const f=hp(c),h=zy(c),b=mp(c)==="x",m=["left","top"].includes(f)?-1:1,g=p&&b?-1:1,v=typeof u=="function"?u(ze(he({},d),{placement:c})):u,y=typeof v=="number";let{mainAxis:T,crossAxis:w,alignmentAxis:k}=y?{mainAxis:v,crossAxis:0,alignmentAxis:null}:he({mainAxis:0,crossAxis:0,alignmentAxis:null},v);return h&&typeof k=="number"&&(w=h==="end"?-1*k:k),b?{x:w*g,y:T*m}:{x:T*m,y:w*g}}(r,a,e,await(l.isRTL==null?void 0:l.isRTL(i.floating)));return{x:n+s.x,y:o+s.y,data:s}}}};function Iy(e){return e&&e.document&&e.location&&e.alert&&e.setInterval}function Ho(e){if(e==null)return window;if(!Iy(e)){const t=e.ownerDocument;return t&&t.defaultView||window}return e}function ii(e){return Ho(e).getComputedStyle(e)}function zo(e){return Iy(e)?"":e?(e.nodeName||"").toLowerCase():""}function yo(e){return e instanceof Ho(e).HTMLElement}function Sa(e){return e instanceof Ho(e).Element}function gp(e){return e instanceof Ho(e).ShadowRoot||e instanceof ShadowRoot}function uc(e){const{overflow:t,overflowX:n,overflowY:o}=ii(e);return/auto|scroll|overlay|hidden/.test(t+o+n)}function wN(e){return["table","td","th"].includes(zo(e))}function nm(e){const t=navigator.userAgent.toLowerCase().includes("firefox"),n=ii(e);return n.transform!=="none"||n.perspective!=="none"||n.contain==="paint"||["transform","perspective"].includes(n.willChange)||t&&n.willChange==="filter"||t&&!!n.filter&&n.filter!=="none"}function My(){return!/^((?!chrome|android).)*safari/i.test(navigator.userAgent)}const om=Math.min,vl=Math.max,Es=Math.round;function Dr(e,t,n){var o,r,a,l;t===void 0&&(t=!1),n===void 0&&(n=!1);const i=e.getBoundingClientRect();let s=1,c=1;t&&yo(e)&&(s=e.offsetWidth>0&&Es(i.width)/e.offsetWidth||1,c=e.offsetHeight>0&&Es(i.height)/e.offsetHeight||1);const d=Sa(e)?Ho(e):window,u=!My()&&n,p=(i.left+(u&&(o=(r=d.visualViewport)==null?void 0:r.offsetLeft)!=null?o:0))/s,f=(i.top+(u&&(a=(l=d.visualViewport)==null?void 0:l.offsetTop)!=null?a:0))/c,h=i.width/s,b=i.height/c;return{width:h,height:b,top:f,right:p+h,bottom:f+b,left:p,x:p,y:f}}function ir(e){return(t=e,(t instanceof Ho(t).Node?e.ownerDocument:e.document)||window.document).documentElement;var t}function pc(e){return Sa(e)?{scrollLeft:e.scrollLeft,scrollTop:e.scrollTop}:{scrollLeft:e.pageXOffset,scrollTop:e.pageYOffset}}function Py(e){return Dr(ir(e)).left+pc(e).scrollLeft}function xN(e,t,n){const o=yo(t),r=ir(t),a=Dr(e,o&&function(s){const c=Dr(s);return Es(c.width)!==s.offsetWidth||Es(c.height)!==s.offsetHeight}(t),n==="fixed");let l={scrollLeft:0,scrollTop:0};const i={x:0,y:0};if(o||!o&&n!=="fixed")if((zo(t)!=="body"||uc(r))&&(l=pc(t)),yo(t)){const s=Dr(t,!0);i.x=s.x+t.clientLeft,i.y=s.y+t.clientTop}else r&&(i.x=Py(r));return{x:a.left+l.scrollLeft-i.x,y:a.top+l.scrollTop-i.y,width:a.width,height:a.height}}function Oy(e){return zo(e)==="html"?e:e.assignedSlot||e.parentNode||(gp(e)?e.host:null)||ir(e)}function rm(e){return yo(e)&&getComputedStyle(e).position!=="fixed"?e.offsetParent:null}function Pd(e){const t=Ho(e);let n=rm(e);for(;n&&wN(n)&&getComputedStyle(n).position==="static";)n=rm(n);return n&&(zo(n)==="html"||zo(n)==="body"&&getComputedStyle(n).position==="static"&&!nm(n))?t:n||function(o){let r=Oy(o);for(gp(r)&&(r=r.host);yo(r)&&!["html","body"].includes(zo(r));){if(nm(r))return r;r=r.parentNode}return null}(e)||t}function am(e){if(yo(e))return{width:e.offsetWidth,height:e.offsetHeight};const t=Dr(e);return{width:t.width,height:t.height}}function Ry(e){const t=Oy(e);return["html","body","#document"].includes(zo(t))?e.ownerDocument.body:yo(t)&&uc(t)?t:Ry(t)}function Dy(e,t){var n;t===void 0&&(t=[]);const o=Ry(e),r=o===((n=e.ownerDocument)==null?void 0:n.body),a=Ho(o),l=r?[a].concat(a.visualViewport||[],uc(o)?o:[]):o,i=t.concat(l);return r?i:i.concat(Dy(l))}function lm(e,t,n){return t==="viewport"?tm(function(o,r){const a=Ho(o),l=ir(o),i=a.visualViewport;let s=l.clientWidth,c=l.clientHeight,d=0,u=0;if(i){s=i.width,c=i.height;const p=My();(p||!p&&r==="fixed")&&(d=i.offsetLeft,u=i.offsetTop)}return{width:s,height:c,x:d,y:u}}(e,n)):Sa(t)?function(o,r){const a=Dr(o,!1,r==="fixed"),l=a.top+o.clientTop,i=a.left+o.clientLeft;return{top:l,left:i,x:i,y:l,right:i+o.clientWidth,bottom:l+o.clientHeight,width:o.clientWidth,height:o.clientHeight}}(t,n):tm(function(o){var r;const a=ir(o),l=pc(o),i=(r=o.ownerDocument)==null?void 0:r.body,s=vl(a.scrollWidth,a.clientWidth,i?i.scrollWidth:0,i?i.clientWidth:0),c=vl(a.scrollHeight,a.clientHeight,i?i.scrollHeight:0,i?i.clientHeight:0);let d=-l.scrollLeft+Py(o);const u=-l.scrollTop;return ii(i||a).direction==="rtl"&&(d+=vl(a.clientWidth,i?i.clientWidth:0)-s),{width:s,height:c,x:d,y:u}}(ir(e)))}function kN(e){const t=Dy(e),n=["absolute","fixed"].includes(ii(e).position)&&yo(e)?Pd(e):e;return Sa(n)?t.filter(o=>Sa(o)&&function(r,a){const l=a==null||a.getRootNode==null?void 0:a.getRootNode();if(r!=null&&r.contains(a))return!0;if(l&&gp(l)){let i=a;do{if(i&&r===i)return!0;i=i.parentNode||i.host}while(i)}return!1}(o,n)&&zo(o)!=="body"):[]}const TN={getClippingRect:function(e){let{element:t,boundary:n,rootBoundary:o,strategy:r}=e;const a=[...n==="clippingAncestors"?kN(t):[].concat(n),o],l=a[0],i=a.reduce((s,c)=>{const d=lm(t,c,r);return s.top=vl(d.top,s.top),s.right=om(d.right,s.right),s.bottom=om(d.bottom,s.bottom),s.left=vl(d.left,s.left),s},lm(t,l,r));return{width:i.right-i.left,height:i.bottom-i.top,x:i.left,y:i.top}},convertOffsetParentRelativeRectToViewportRelativeRect:function(e){let{rect:t,offsetParent:n,strategy:o}=e;const r=yo(n),a=ir(n);if(n===a)return t;let l={scrollLeft:0,scrollTop:0};const i={x:0,y:0};if((r||!r&&o!=="fixed")&&((zo(n)!=="body"||uc(a))&&(l=pc(n)),yo(n))){const s=Dr(n,!0);i.x=s.x+n.clientLeft,i.y=s.y+n.clientTop}return ze(he({},t),{x:t.x-l.scrollLeft+i.x,y:t.y-l.scrollTop+i.y})},isElement:Sa,getDimensions:am,getOffsetParent:Pd,getDocumentElement:ir,getElementRects:e=>{let{reference:t,floating:n,strategy:o}=e;return{reference:xN(t,Pd(n),o),floating:ze(he({},am(n)),{x:0,y:0})}},getClientRects:e=>Array.from(e.getClientRects()),isRTL:e=>ii(e).direction==="rtl"},CN=(e,t,n)=>fN(e,t,he({platform:TN},n));Le({});const SN=e=>{if(!dt)return;if(!e)return e;const t=no(e);return t||(Vt(e)?t:e)},$N=({middleware:e,placement:t,strategy:n})=>{const o=E(),r=E(),a=E(),l=E(),i=E({}),s={x:a,y:l,placement:t,strategy:n,middlewareData:i},c=async()=>{if(!dt)return;const d=SN(o),u=no(r);if(!d||!u)return;const p=await CN(d,u,{placement:_(t),strategy:_(n),middleware:_(e)});Object.keys(s).forEach(f=>{s[f].value=p[f]})};return et(()=>{Fn(()=>{c()})}),ze(he({},s),{update:c,referenceRef:o,contentRef:r})},EN=({arrowRef:e,padding:t})=>({name:"arrow",options:{element:e,padding:t},fn(n){const o=_(e);return o?vN({element:o,padding:t}).fn(n):{}}}),AN="2.1.9",im=Symbol("INSTALLED_KEY"),zN=(e=[])=>({version:AN,install:(n,o)=>{n[im]||(n[im]=!0,e.forEach(r=>n.use(r)),o&&xy(o,n,!0))}}),NN=Le({zIndex:{type:Te([Number,String]),default:100},target:{type:String,default:""},offset:{type:Number,default:0},position:{type:String,values:["top","bottom"],default:"top"}}),IN={scroll:({scrollTop:e,fixed:t})=>typeof e=="number"&&typeof t=="boolean",change:e=>typeof e=="boolean"};var _e=(e,t)=>{const n=e.__vccOpts||e;for(const[o,r]of t)n[o]=r;return n};const MN={name:"ElAffix"},PN=ee(ze(he({},MN),{props:NN,emits:IN,setup(e,{expose:t,emit:n}){const o=e,r="ElAffix",a=ke("affix"),l=Kt(),i=Kt(),s=Kt(),{height:c}=f4(),{height:d,width:u,top:p,bottom:f,update:h}=Kh(i),b=Kh(l),m=E(!1),g=E(0),v=E(0),y=C(()=>({height:m.value?`${d.value}px`:"",width:m.value?`${u.value}px`:""})),T=C(()=>{if(!m.value)return{};const $=o.offset?`${o.offset}px`:0;return{height:`${d.value}px`,width:`${u.value}px`,top:o.position==="top"?$:"",bottom:o.position==="bottom"?$:"",transform:v.value?`translateY(${v.value}px)`:"",zIndex:o.zIndex}}),w=()=>{if(!!s.value)if(g.value=s.value instanceof Window?document.documentElement.scrollTop:s.value.scrollTop||0,o.position==="top")if(o.target){const $=b.bottom.value-o.offset-d.value;m.value=o.offset>p.value&&b.bottom.value>0,v.value=$<0?$:0}else m.value=o.offset>p.value;else if(o.target){const $=c.value-b.top.value-o.offset-d.value;m.value=c.value-o.offsetb.top.value,v.value=$<0?-$:0}else m.value=c.value-o.offset{n("scroll",{scrollTop:g.value,fixed:m.value})};return ge(m,$=>n("change",$)),et(()=>{var $;o.target?(l.value=($=document.querySelector(o.target))!=null?$:void 0,l.value||Wt(r,`Target is not existed: ${o.target}`)):l.value=document.documentElement,s.value=ap(i.value,!0),h()}),Ht(s,"scroll",k),Fn(w),t({update:w}),($,z)=>(x(),N("div",{ref_key:"root",ref:i,class:S(_(a).b()),style:Re(_(y))},[M("div",{class:S({[_(a).m("fixed")]:m.value}),style:Re(_(T))},[ue($.$slots,"default")],6)],6))}}));var ON=_e(PN,[["__file","/home/runner/work/element-plus/element-plus/packages/components/affix/src/affix.vue"]]);const RN=rt(ON),DN=Le({size:{type:Te([Number,String])},color:{type:String}}),FN={name:"ElIcon",inheritAttrs:!1},LN=ee(ze(he({},FN),{props:DN,setup(e){const t=e,n=ke("icon"),o=C(()=>!t.size&&!t.color?{}:{fontSize:Cn(t.size)?void 0:lo(t.size),"--color":t.color});return(r,a)=>(x(),N("i",St({class:_(n).b(),style:_(o)},r.$attrs),[ue(r.$slots,"default")],16))}}));var VN=_e(LN,[["__file","/home/runner/work/element-plus/element-plus/packages/components/icon/src/icon.vue"]]);const qe=rt(VN),BN=["light","dark"],jN=Le({title:{type:String,default:""},description:{type:String,default:""},type:{type:String,values:Id(Do),default:"info"},closable:{type:Boolean,default:!0},closeText:{type:String,default:""},showIcon:Boolean,center:Boolean,effect:{type:String,values:BN,default:"light"}}),HN={close:e=>e instanceof MouseEvent},qN={name:"ElAlert"},KN=ee(ze(he({},qN),{props:jN,emits:HN,setup(e,{emit:t}){const n=e,{Close:o}=lc,r=ni(),a=ke("alert"),l=E(!0),i=C(()=>Do[n.type]||Do.info),s=C(()=>n.description||{[a.is("big")]:r.default}),c=C(()=>n.description||{[a.is("bold")]:r.default}),d=u=>{l.value=!1,t("close",u)};return(u,p)=>(x(),Q(qt,{name:_(a).b("fade")},{default:K(()=>[Ue(M("div",{class:S([_(a).b(),_(a).m(u.type),_(a).is("center",u.center),_(a).is(u.effect)]),role:"alert"},[u.showIcon&&_(i)?(x(),Q(_(qe),{key:0,class:S([_(a).e("icon"),_(s)])},{default:K(()=>[(x(),Q(pt(_(i))))]),_:1},8,["class"])):G("v-if",!0),M("div",{class:S(_(a).e("content"))},[u.title||u.$slots.title?(x(),N("span",{key:0,class:S([_(a).e("title"),_(c)])},[ue(u.$slots,"title",{},()=>[lt(ve(u.title),1)])],2)):G("v-if",!0),u.$slots.default||u.description?(x(),N("p",{key:1,class:S(_(a).e("description"))},[ue(u.$slots,"default",{},()=>[lt(ve(u.description),1)])],2)):G("v-if",!0),u.closable?(x(),N(De,{key:2},[u.closeText?(x(),N("div",{key:0,class:S([_(a).e("close-btn"),_(a).is("customed")]),onClick:d},ve(u.closeText),3)):(x(),Q(_(qe),{key:1,class:S(_(a).e("close-btn")),onClick:d},{default:K(()=>[U(_(o))]),_:1},8,["class"]))],2112)):G("v-if",!0)],2)],2),[[ft,l.value]])]),_:3},8,["name"]))}}));var WN=_e(KN,[["__file","/home/runner/work/element-plus/element-plus/packages/components/alert/src/alert.vue"]]);const UN=rt(WN);let Xn;const YN=`
+ height:0 !important;
+ visibility:hidden !important;
+ overflow:hidden !important;
+ position:absolute !important;
+ z-index:-1000 !important;
+ top:0 !important;
+ right:0 !important;
+`,GN=["letter-spacing","line-height","padding-top","padding-bottom","font-family","font-weight","font-size","text-rendering","text-transform","width","text-indent","padding-left","padding-right","border-width","box-sizing"];function XN(e){const t=window.getComputedStyle(e),n=t.getPropertyValue("box-sizing"),o=Number.parseFloat(t.getPropertyValue("padding-bottom"))+Number.parseFloat(t.getPropertyValue("padding-top")),r=Number.parseFloat(t.getPropertyValue("border-bottom-width"))+Number.parseFloat(t.getPropertyValue("border-top-width"));return{contextStyle:GN.map(l=>`${l}:${t.getPropertyValue(l)}`).join(";"),paddingSize:o,borderSize:r,boxSizing:n}}function sm(e,t=1,n){var o;Xn||(Xn=document.createElement("textarea"),document.body.appendChild(Xn));const{paddingSize:r,borderSize:a,boxSizing:l,contextStyle:i}=XN(e);Xn.setAttribute("style",`${i};${YN}`),Xn.value=e.value||e.placeholder||"";let s=Xn.scrollHeight;const c={};l==="border-box"?s=s+a:l==="content-box"&&(s=s-r),Xn.value="";const d=Xn.scrollHeight-r;if(mt(t)){let u=d*t;l==="border-box"&&(u=u+r+a),s=Math.max(u,s),c.minHeight=`${u}px`}if(mt(n)){let u=d*n;l==="border-box"&&(u=u+r+a),s=Math.min(u,s)}return c.height=`${s}px`,(o=Xn.parentNode)==null||o.removeChild(Xn),Xn=void 0,c}const ZN=Le({size:dc,disabled:Boolean,modelValue:{type:Te([String,Number,Object]),default:""},type:{type:String,default:"text"},resize:{type:String,values:["none","both","horizontal","vertical"]},autosize:{type:Te([Boolean,Object]),default:!1},autocomplete:{type:String,default:"off"},placeholder:{type:String},form:{type:String,default:""},readonly:{type:Boolean,default:!1},clearable:{type:Boolean,default:!1},showPassword:{type:Boolean,default:!1},showWordLimit:{type:Boolean,default:!1},suffixIcon:{type:an,default:""},prefixIcon:{type:an,default:""},label:{type:String},tabindex:{type:[Number,String]},validateEvent:{type:Boolean,default:!0},inputStyle:{type:Te([Object,Array,String]),default:()=>Dt({})}}),JN={[tt]:e=>Qe(e),input:e=>Qe(e),change:e=>Qe(e),focus:e=>e instanceof FocusEvent,blur:e=>e instanceof FocusEvent,clear:()=>!0,mouseleave:e=>e instanceof MouseEvent,mouseenter:e=>e instanceof MouseEvent,keydown:e=>e instanceof Event,compositionstart:e=>e instanceof CompositionEvent,compositionupdate:e=>e instanceof CompositionEvent,compositionend:e=>e instanceof CompositionEvent},QN=["type","disabled","readonly","autocomplete","tabindex","aria-label","placeholder"],e8=["tabindex","disabled","readonly","autocomplete","aria-label","placeholder"],t8={name:"ElInput",inheritAttrs:!1},n8=ee(ze(he({},t8),{props:ZN,emits:JN,setup(e,{expose:t,emit:n}){const o=e,r={suffix:"append",prefix:"prepend"},a=nt(),l=Ob(),i=ni(),s=dp(),{form:c,formItem:d}=Ka(),u=Ut(),p=Zr(),f=ke("input"),h=ke("textarea"),b=Kt(),m=Kt(),g=E(!1),v=E(!1),y=E(!1),T=E(!1),w=Kt(o.inputStyle),k=C(()=>b.value||m.value),$=C(()=>{var B;return(B=c==null?void 0:c.statusIcon)!=null?B:!1}),z=C(()=>(d==null?void 0:d.validateState)||""),O=C(()=>ty[z.value]),R=C(()=>T.value?mz:IA),F=C(()=>[l.style,o.inputStyle]),L=C(()=>[o.inputStyle,w.value,{resize:o.resize}]),D=C(()=>op(o.modelValue)?"":String(o.modelValue)),V=C(()=>o.clearable&&!p.value&&!o.readonly&&!!D.value&&(g.value||v.value)),q=C(()=>o.showPassword&&!p.value&&!o.readonly&&(!!D.value||g.value)),P=C(()=>o.showWordLimit&&!!s.value.maxlength&&(o.type==="text"||o.type==="textarea")&&!p.value&&!o.readonly&&!o.showPassword),A=C(()=>Array.from(D.value).length),I=C(()=>!!P.value&&A.value>Number(s.value.maxlength)),W=C(()=>!!i.suffix||!!o.suffixIcon||V.value||o.showPassword||P.value||!!z.value&&$.value),Y=()=>{const{type:B,autosize:me}=o;if(!(!dt||B!=="textarea"))if(me){const Be=ut(me)?me.minRows:void 0,Ze=ut(me)?me.maxRows:void 0;w.value=he({},sm(m.value,Be,Ze))}else w.value={minHeight:sm(m.value).minHeight}},J=()=>{const B=k.value;!B||B.value===D.value||(B.value=D.value)},Z=B=>{const{el:me}=a.vnode;if(!me)return;const Ze=Array.from(me.querySelectorAll(`.${f.e(B)}`)).find(re=>re.parentNode===me);if(!Ze)return;const Ve=r[B];i[Ve]?Ze.style.transform=`translateX(${B==="suffix"?"-":""}${me.querySelector(`.${f.be("group",Ve)}`).offsetWidth}px)`:Ze.removeAttribute("style")},se=()=>{Z("prefix"),Z("suffix")},Se=async B=>{const{value:me}=B.target;y.value||me!==D.value&&(n(tt,me),n("input",me),await je(),J())},oe=B=>{n("change",B.target.value)},H=B=>{n("compositionstart",B),y.value=!0},ne=B=>{var me;n("compositionupdate",B);const Be=(me=B.target)==null?void 0:me.value,Ze=Be[Be.length-1]||"";y.value=!ic(Ze)},le=B=>{n("compositionend",B),y.value&&(y.value=!1,Se(B))},be=()=>{T.value=!T.value,$e()},$e=async()=>{var B;await je(),(B=k.value)==null||B.focus()},Ie=()=>{var B;return(B=k.value)==null?void 0:B.blur()},Me=B=>{g.value=!0,n("focus",B)},j=B=>{var me;g.value=!1,n("blur",B),o.validateEvent&&((me=d==null?void 0:d.validate)==null||me.call(d,"blur").catch(Be=>void 0))},X=B=>{v.value=!1,n("mouseleave",B)},de=B=>{v.value=!0,n("mouseenter",B)},xe=B=>{n("keydown",B)},we=()=>{var B;(B=k.value)==null||B.select()},Ee=()=>{n(tt,""),n("change",""),n("clear"),n("input","")};ge(()=>o.modelValue,()=>{var B;je(()=>Y()),o.validateEvent&&((B=d==null?void 0:d.validate)==null||B.call(d,"change").catch(me=>void 0))}),ge(D,()=>J()),ge(()=>o.type,async()=>{await je(),J(),Y(),se()});const ce=E(),ae=E(),te=E({}),pe=(B,me)=>{if(B.value){const Be=B.value.offsetWidth;return Be>0?Be+16:me}return me},Fe=()=>{te.value=he({paddingRight:`${pe(ce,0)}px`,paddingLeft:`${pe(ae,11)}px`},o.inputStyle)};return ge(V,()=>{je(()=>{Fe()})}),et(async()=>{Fe(),J(),se(),await je(),Y()}),Un(async()=>{await je(),se()}),t({input:b,textarea:m,ref:k,textareaStyle:L,autosize:Yt(o,"autosize"),focus:$e,blur:Ie,select:we,clear:Ee,resizeTextarea:Y}),(B,me)=>Ue((x(),N("div",{class:S([B.type==="textarea"?_(h).b():_(f).b(),_(f).m(_(u)),_(f).is("disabled",_(p)),_(f).is("exceed",_(I)),{[_(f).b("group")]:B.$slots.prepend||B.$slots.append,[_(f).bm("group","append")]:B.$slots.append,[_(f).bm("group","prepend")]:B.$slots.prepend,[_(f).m("prefix")]:B.$slots.prefix||B.prefixIcon,[_(f).m("suffix")]:B.$slots.suffix||B.suffixIcon||B.clearable||B.showPassword,[_(f).m("suffix--password-clear")]:_(V)&&_(q)},B.$attrs.class]),style:Re(_(F)),onMouseenter:de,onMouseleave:X},[G(" input "),B.type!=="textarea"?(x(),N(De,{key:0},[G(" prepend slot "),B.$slots.prepend?(x(),N("div",{key:0,class:S(_(f).be("group","prepend"))},[ue(B.$slots,"prepend")],2)):G("v-if",!0),M("input",St({ref_key:"input",ref:b,class:_(f).e("inner")},_(s),{type:B.showPassword?T.value?"text":"password":B.type,disabled:_(p),readonly:B.readonly,autocomplete:B.autocomplete,tabindex:B.tabindex,"aria-label":B.label,placeholder:B.placeholder,style:te.value,onCompositionstart:H,onCompositionupdate:ne,onCompositionend:le,onInput:Se,onFocus:Me,onBlur:j,onChange:oe,onKeydown:xe}),null,16,QN),G(" prefix slot "),B.$slots.prefix||B.prefixIcon?(x(),N("span",{key:1,class:S(_(f).e("prefix"))},[M("span",{ref_key:"innerPrefixRef",ref:ae,class:S(_(f).e("prefix-inner"))},[ue(B.$slots,"prefix"),B.prefixIcon?(x(),Q(_(qe),{key:0,class:S(_(f).e("icon"))},{default:K(()=>[(x(),Q(pt(B.prefixIcon)))]),_:1},8,["class"])):G("v-if",!0)],2)],2)):G("v-if",!0),G(" suffix slot "),_(W)?(x(),N("span",{key:2,class:S(_(f).e("suffix"))},[M("span",{ref_key:"innerSuffixRef",ref:ce,class:S(_(f).e("suffix-inner"))},[!_(V)||!_(q)||!_(P)?(x(),N(De,{key:0},[ue(B.$slots,"suffix"),B.suffixIcon?(x(),Q(_(qe),{key:0,class:S(_(f).e("icon"))},{default:K(()=>[(x(),Q(pt(B.suffixIcon)))]),_:1},8,["class"])):G("v-if",!0)],64)):G("v-if",!0),_(V)?(x(),Q(_(qe),{key:1,class:S([_(f).e("icon"),_(f).e("clear")]),onMousedown:me[0]||(me[0]=He(()=>{},["prevent"])),onClick:Ee},{default:K(()=>[U(_(Ro))]),_:1},8,["class"])):G("v-if",!0),_(q)?(x(),Q(_(qe),{key:2,class:S([_(f).e("icon"),_(f).e("clear")]),onClick:be},{default:K(()=>[(x(),Q(pt(_(R))))]),_:1},8,["class"])):G("v-if",!0),_(P)?(x(),N("span",{key:3,class:S(_(f).e("count"))},[M("span",{class:S(_(f).e("count-inner"))},ve(_(A))+" / "+ve(_(s).maxlength),3)],2)):G("v-if",!0)],2),_(z)&&_(O)&&_($)?(x(),Q(_(qe),{key:0,class:S([_(f).e("icon"),_(f).e("validateIcon"),_(f).is("loading",_(z)==="validating")])},{default:K(()=>[(x(),Q(pt(_(O))))]),_:1},8,["class"])):G("v-if",!0)],2)):G("v-if",!0),G(" append slot "),B.$slots.append?(x(),N("div",{key:3,class:S(_(f).be("group","append"))},[ue(B.$slots,"append")],2)):G("v-if",!0)],64)):(x(),N(De,{key:1},[G(" textarea "),M("textarea",St({ref_key:"textarea",ref:m,class:_(h).e("inner")},_(s),{tabindex:B.tabindex,disabled:_(p),readonly:B.readonly,autocomplete:B.autocomplete,style:_(L),"aria-label":B.label,placeholder:B.placeholder,onCompositionstart:H,onCompositionupdate:ne,onCompositionend:le,onInput:Se,onFocus:Me,onBlur:j,onChange:oe,onKeydown:xe}),null,16,e8),_(P)?(x(),N("span",{key:0,class:S(_(f).e("count"))},ve(_(A))+" / "+ve(_(s).maxlength),3)):G("v-if",!0)],64))],38)),[[ft,B.type!=="hidden"]])}}));var o8=_e(n8,[["__file","/home/runner/work/element-plus/element-plus/packages/components/input/src/input.vue"]]);const Gn=rt(o8),Fy={vertical:{offset:"offsetHeight",scroll:"scrollTop",scrollSize:"scrollHeight",size:"height",key:"vertical",axis:"Y",client:"clientY",direction:"top"},horizontal:{offset:"offsetWidth",scroll:"scrollLeft",scrollSize:"scrollWidth",size:"width",key:"horizontal",axis:"X",client:"clientX",direction:"left"}},r8=({move:e,size:t,bar:n})=>({[n.size]:t,transform:`translate${n.axis}(${e}%)`}),a8=Le({vertical:Boolean,size:String,move:Number,ratio:{type:Number,required:!0},always:Boolean}),cm="Thumb",l8=ee({name:cm,props:a8,setup(e){const t=Ne(by),n=ke("scrollbar");t||Wt(cm,"can not inject scrollbar context");const o=E(),r=E(),a=E({}),l=E(!1);let i=!1,s=!1,c=dt?document.onselectstart:null;const d=C(()=>Fy[e.vertical?"vertical":"horizontal"]),u=C(()=>r8({size:e.size,move:e.move,bar:d.value})),p=C(()=>o.value[d.value.offset]**2/t.wrapElement[d.value.scrollSize]/e.ratio/r.value[d.value.offset]),f=w=>{var k;if(w.stopPropagation(),w.ctrlKey||[1,2].includes(w.button))return;(k=window.getSelection())==null||k.removeAllRanges(),b(w);const $=w.currentTarget;!$||(a.value[d.value.axis]=$[d.value.offset]-(w[d.value.client]-$.getBoundingClientRect()[d.value.direction]))},h=w=>{if(!r.value||!o.value||!t.wrapElement)return;const k=Math.abs(w.target.getBoundingClientRect()[d.value.direction]-w[d.value.client]),$=r.value[d.value.offset]/2,z=(k-$)*100*p.value/o.value[d.value.offset];t.wrapElement[d.value.scroll]=z*t.wrapElement[d.value.scrollSize]/100},b=w=>{w.stopImmediatePropagation(),i=!0,document.addEventListener("mousemove",m),document.addEventListener("mouseup",g),c=document.onselectstart,document.onselectstart=()=>!1},m=w=>{if(!o.value||!r.value||i===!1)return;const k=a.value[d.value.axis];if(!k)return;const $=(o.value.getBoundingClientRect()[d.value.direction]-w[d.value.client])*-1,z=r.value[d.value.offset]-k,O=($-z)*100*p.value/o.value[d.value.offset];t.wrapElement[d.value.scroll]=O*t.wrapElement[d.value.scrollSize]/100},g=()=>{i=!1,a.value[d.value.axis]=0,document.removeEventListener("mousemove",m),document.removeEventListener("mouseup",g),T(),s&&(l.value=!1)},v=()=>{s=!1,l.value=!!e.size},y=()=>{s=!0,l.value=i};$t(()=>{T(),document.removeEventListener("mouseup",g)});const T=()=>{document.onselectstart!==c&&(document.onselectstart=c)};return Ht(Yt(t,"scrollbarElement"),"mousemove",v),Ht(Yt(t,"scrollbarElement"),"mouseleave",y),{ns:n,instance:o,thumb:r,bar:d,thumbStyle:u,visible:l,clickTrackHandler:h,clickThumbHandler:f}}});function i8(e,t,n,o,r,a){return x(),Q(qt,{name:e.ns.b("fade")},{default:K(()=>[Ue(M("div",{ref:"instance",class:S([e.ns.e("bar"),e.ns.is(e.bar.key)]),onMousedown:t[1]||(t[1]=(...l)=>e.clickTrackHandler&&e.clickTrackHandler(...l))},[M("div",{ref:"thumb",class:S(e.ns.e("thumb")),style:Re(e.thumbStyle),onMousedown:t[0]||(t[0]=(...l)=>e.clickThumbHandler&&e.clickThumbHandler(...l))},null,38)],34),[[ft,e.always||e.visible]])]),_:1},8,["name"])}var s8=_e(l8,[["render",i8],["__file","/home/runner/work/element-plus/element-plus/packages/components/scrollbar/src/thumb.vue"]]);const c8=Le({always:{type:Boolean,default:!0},width:{type:String,default:""},height:{type:String,default:""},ratioX:{type:Number,default:1},ratioY:{type:Number,default:1}}),d8=ee({components:{Thumb:s8},props:c8,setup(e){const t=E(0),n=E(0),o=4;return{handleScroll:a=>{if(a){const l=a.offsetHeight-o,i=a.offsetWidth-o;n.value=a.scrollTop*100/l*e.ratioY,t.value=a.scrollLeft*100/i*e.ratioX}},moveX:t,moveY:n}}});function u8(e,t,n,o,r,a){const l=ie("thumb");return x(),N(De,null,[U(l,{move:e.moveX,ratio:e.ratioX,size:e.width,always:e.always},null,8,["move","ratio","size","always"]),U(l,{move:e.moveY,ratio:e.ratioY,size:e.height,vertical:"",always:e.always},null,8,["move","ratio","size","always"])],64)}var p8=_e(d8,[["render",u8],["__file","/home/runner/work/element-plus/element-plus/packages/components/scrollbar/src/bar.vue"]]);const f8=Le({height:{type:[String,Number],default:""},maxHeight:{type:[String,Number],default:""},native:{type:Boolean,default:!1},wrapStyle:{type:Te([String,Object,Array]),default:""},wrapClass:{type:[String,Array],default:""},viewClass:{type:[String,Array],default:""},viewStyle:{type:[String,Array,Object],default:""},noresize:Boolean,tag:{type:String,default:"div"},always:{type:Boolean,default:!1},minSize:{type:Number,default:20}}),h8={scroll:({scrollTop:e,scrollLeft:t})=>mt(e)&&mt(t)},m8=ee({name:"ElScrollbar",components:{Bar:p8},props:f8,emits:h8,setup(e,{emit:t}){const n=ke("scrollbar");let o,r;const a=E(),l=E(),i=E(),s=E("0"),c=E("0"),d=E(),u=E(0),p=E(0),f=E(1),h=E(1),b=4,m=C(()=>{const k={};return e.height&&(k.height=lo(e.height)),e.maxHeight&&(k.maxHeight=lo(e.maxHeight)),[e.wrapStyle,k]}),g=()=>{var k;l.value&&((k=d.value)==null||k.handleScroll(l.value),t("scroll",{scrollTop:l.value.scrollTop,scrollLeft:l.value.scrollLeft}))};function v(k,$){ut(k)?l.value.scrollTo(k):mt(k)&&mt($)&&l.value.scrollTo(k,$)}const y=k=>{!mt(k)||(l.value.scrollTop=k)},T=k=>{!mt(k)||(l.value.scrollLeft=k)},w=()=>{if(!l.value)return;const k=l.value.offsetHeight-b,$=l.value.offsetWidth-b,z=k**2/l.value.scrollHeight,O=$**2/l.value.scrollWidth,R=Math.max(z,e.minSize),F=Math.max(O,e.minSize);f.value=z/(k-z)/(R/(k-R)),h.value=O/($-O)/(F/($-F)),c.value=R+be.noresize,k=>{k?(o==null||o(),r==null||r()):({stop:o}=Ba(i,w),r=Ht("resize",w))},{immediate:!0}),ge(()=>[e.maxHeight,e.height],()=>{e.native||je(()=>{var k;w(),l.value&&((k=d.value)==null||k.handleScroll(l.value))})}),ot(by,vt({scrollbarElement:a,wrapElement:l})),et(()=>{e.native||je(()=>w())}),Un(()=>w()),{ns:n,scrollbar$:a,wrap$:l,resize$:i,barRef:d,moveX:u,moveY:p,ratioX:h,ratioY:f,sizeWidth:s,sizeHeight:c,style:m,update:w,handleScroll:g,scrollTo:v,setScrollTop:y,setScrollLeft:T}}});function g8(e,t,n,o,r,a){const l=ie("bar");return x(),N("div",{ref:"scrollbar$",class:S(e.ns.b())},[M("div",{ref:"wrap$",class:S([e.wrapClass,e.ns.e("wrap"),{[e.ns.em("wrap","hidden-default")]:!e.native}]),style:Re(e.style),onScroll:t[0]||(t[0]=(...i)=>e.handleScroll&&e.handleScroll(...i))},[(x(),Q(pt(e.tag),{ref:"resize$",class:S([e.ns.e("view"),e.viewClass]),style:Re(e.viewStyle)},{default:K(()=>[ue(e.$slots,"default")]),_:3},8,["class","style"]))],38),e.native?G("v-if",!0):(x(),Q(l,{key:0,ref:"barRef",height:e.sizeHeight,width:e.sizeWidth,always:e.always,"ratio-x":e.ratioX,"ratio-y":e.ratioY},null,8,["height","width","always","ratio-x","ratio-y"]))],2)}var b8=_e(m8,[["render",g8],["__file","/home/runner/work/element-plus/element-plus/packages/components/scrollbar/src/scrollbar.vue"]]);const qo=rt(b8),v8={name:"ElPopperRoot",inheritAttrs:!1},y8=ee(ze(he({},v8),{setup(e,{expose:t}){const n=E(),o=E(),r=E(),a=E(),l={triggerRef:n,popperInstanceRef:o,contentRef:r,referenceRef:a};return t(l),ot(up,l),(i,s)=>ue(i.$slots,"default")}}));var _8=_e(y8,[["__file","/home/runner/work/element-plus/element-plus/packages/components/popper/src/popper.vue"]]);const Ly=Le({arrowOffset:{type:Number,default:5}}),w8={name:"ElPopperArrow",inheritAttrs:!1},x8=ee(ze(he({},w8),{props:Ly,setup(e,{expose:t}){const n=e,o=ke("popper"),{arrowOffset:r,arrowRef:a}=Ne(yy,void 0);return ge(()=>n.arrowOffset,l=>{r.value=l}),$t(()=>{a.value=void 0}),t({arrowRef:a}),(l,i)=>(x(),N("span",{ref_key:"arrowRef",ref:a,class:S(_(o).e("arrow")),"data-popper-arrow":""},null,2))}}));var k8=_e(x8,[["__file","/home/runner/work/element-plus/element-plus/packages/components/popper/src/arrow.vue"]]);const T8="ElOnlyChild",C8=ee({name:T8,setup(e,{slots:t,attrs:n}){var o;const r=Ne(Ay),a=dN((o=r==null?void 0:r.setForwardRef)!=null?o:wt);return()=>{var l;const i=(l=t.default)==null?void 0:l.call(t,n);if(!i||i.length>1)return null;const s=Vy(i);return s?Ue(Io(s,n),[[a]]):null}}});function Vy(e){if(!e)return null;const t=e;for(const n of t){if(ut(n))switch(n.type){case dn:continue;case ti:return Oc(n);case"svg":return Oc(n);case De:return Vy(n.children);default:return n}return Oc(n)}return null}function Oc(e){return U("span",{class:"el-only-child__content"},[e])}const By=Le({virtualRef:{type:Te(Object)},virtualTriggering:Boolean,onMouseenter:Function,onMouseleave:Function,onClick:Function,onKeydown:Function,onFocus:Function,onBlur:Function,onContextmenu:Function,id:String,open:Boolean}),S8={name:"ElPopperTrigger",inheritAttrs:!1},$8=ee(ze(he({},S8),{props:By,setup(e,{expose:t}){const n=e,{triggerRef:o}=Ne(up,void 0);return cN(o),et(()=>{ge(()=>n.virtualRef,r=>{r&&(o.value=no(r))},{immediate:!0}),ge(()=>o.value,(r,a)=>{Hr(r)&&["onMouseenter","onMouseleave","onClick","onKeydown","onFocus","onBlur","onContextmenu"].forEach(l=>{var i;const s=n[l];s&&(r.addEventListener(l.slice(2).toLowerCase(),s),(i=a==null?void 0:a.removeEventListener)==null||i.call(a,l.slice(2).toLowerCase(),s))})},{immediate:!0})}),t({triggerRef:o}),(r,a)=>r.virtualTriggering?G("v-if",!0):(x(),Q(_(C8),St({key:0},r.$attrs,{"aria-describedby":r.open?r.id:void 0}),{default:K(()=>[ue(r.$slots,"default")]),_:3},16,["aria-describedby"]))}}));var E8=_e($8,[["__file","/home/runner/work/element-plus/element-plus/packages/components/popper/src/trigger.vue"]]),mn="top",Kn="bottom",Wn="right",gn="left",bp="auto",si=[mn,Kn,Wn,gn],$a="start",Hl="end",A8="clippingParents",jy="viewport",tl="popper",z8="reference",dm=si.reduce(function(e,t){return e.concat([t+"-"+$a,t+"-"+Hl])},[]),vp=[].concat(si,[bp]).reduce(function(e,t){return e.concat([t,t+"-"+$a,t+"-"+Hl])},[]),N8="beforeRead",I8="read",M8="afterRead",P8="beforeMain",O8="main",R8="afterMain",D8="beforeWrite",F8="write",L8="afterWrite",V8=[N8,I8,M8,P8,O8,R8,D8,F8,L8];function _o(e){return e?(e.nodeName||"").toLowerCase():null}function po(e){if(e==null)return window;if(e.toString()!=="[object Window]"){var t=e.ownerDocument;return t&&t.defaultView||window}return e}function Ea(e){var t=po(e).Element;return e instanceof t||e instanceof Element}function Ln(e){var t=po(e).HTMLElement;return e instanceof t||e instanceof HTMLElement}function yp(e){if(typeof ShadowRoot=="undefined")return!1;var t=po(e).ShadowRoot;return e instanceof t||e instanceof ShadowRoot}function B8(e){var t=e.state;Object.keys(t.elements).forEach(function(n){var o=t.styles[n]||{},r=t.attributes[n]||{},a=t.elements[n];!Ln(a)||!_o(a)||(Object.assign(a.style,o),Object.keys(r).forEach(function(l){var i=r[l];i===!1?a.removeAttribute(l):a.setAttribute(l,i===!0?"":i)}))})}function j8(e){var t=e.state,n={popper:{position:t.options.strategy,left:"0",top:"0",margin:"0"},arrow:{position:"absolute"},reference:{}};return Object.assign(t.elements.popper.style,n.popper),t.styles=n,t.elements.arrow&&Object.assign(t.elements.arrow.style,n.arrow),function(){Object.keys(t.elements).forEach(function(o){var r=t.elements[o],a=t.attributes[o]||{},l=Object.keys(t.styles.hasOwnProperty(o)?t.styles[o]:n[o]),i=l.reduce(function(s,c){return s[c]="",s},{});!Ln(r)||!_o(r)||(Object.assign(r.style,i),Object.keys(a).forEach(function(s){r.removeAttribute(s)}))})}}var H8={name:"applyStyles",enabled:!0,phase:"write",fn:B8,effect:j8,requires:["computeStyles"]};function vo(e){return e.split("-")[0]}var Fr=Math.max,As=Math.min,Aa=Math.round;function za(e,t){t===void 0&&(t=!1);var n=e.getBoundingClientRect(),o=1,r=1;if(Ln(e)&&t){var a=e.offsetHeight,l=e.offsetWidth;l>0&&(o=Aa(n.width)/l||1),a>0&&(r=Aa(n.height)/a||1)}return{width:n.width/o,height:n.height/r,top:n.top/r,right:n.right/o,bottom:n.bottom/r,left:n.left/o,x:n.left/o,y:n.top/r}}function _p(e){var t=za(e),n=e.offsetWidth,o=e.offsetHeight;return Math.abs(t.width-n)<=1&&(n=t.width),Math.abs(t.height-o)<=1&&(o=t.height),{x:e.offsetLeft,y:e.offsetTop,width:n,height:o}}function Hy(e,t){var n=t.getRootNode&&t.getRootNode();if(e.contains(t))return!0;if(n&&yp(n)){var o=t;do{if(o&&e.isSameNode(o))return!0;o=o.parentNode||o.host}while(o)}return!1}function Fo(e){return po(e).getComputedStyle(e)}function q8(e){return["table","td","th"].indexOf(_o(e))>=0}function mr(e){return((Ea(e)?e.ownerDocument:e.document)||window.document).documentElement}function fc(e){return _o(e)==="html"?e:e.assignedSlot||e.parentNode||(yp(e)?e.host:null)||mr(e)}function um(e){return!Ln(e)||Fo(e).position==="fixed"?null:e.offsetParent}function K8(e){var t=navigator.userAgent.toLowerCase().indexOf("firefox")!==-1,n=navigator.userAgent.indexOf("Trident")!==-1;if(n&&Ln(e)){var o=Fo(e);if(o.position==="fixed")return null}var r=fc(e);for(yp(r)&&(r=r.host);Ln(r)&&["html","body"].indexOf(_o(r))<0;){var a=Fo(r);if(a.transform!=="none"||a.perspective!=="none"||a.contain==="paint"||["transform","perspective"].indexOf(a.willChange)!==-1||t&&a.willChange==="filter"||t&&a.filter&&a.filter!=="none")return r;r=r.parentNode}return null}function ci(e){for(var t=po(e),n=um(e);n&&q8(n)&&Fo(n).position==="static";)n=um(n);return n&&(_o(n)==="html"||_o(n)==="body"&&Fo(n).position==="static")?t:n||K8(e)||t}function wp(e){return["top","bottom"].indexOf(e)>=0?"x":"y"}function yl(e,t,n){return Fr(e,As(t,n))}function W8(e,t,n){var o=yl(e,t,n);return o>n?n:o}function qy(){return{top:0,right:0,bottom:0,left:0}}function Ky(e){return Object.assign({},qy(),e)}function Wy(e,t){return t.reduce(function(n,o){return n[o]=e,n},{})}var U8=function(t,n){return t=typeof t=="function"?t(Object.assign({},n.rects,{placement:n.placement})):t,Ky(typeof t!="number"?t:Wy(t,si))};function Y8(e){var t,n=e.state,o=e.name,r=e.options,a=n.elements.arrow,l=n.modifiersData.popperOffsets,i=vo(n.placement),s=wp(i),c=[gn,Wn].indexOf(i)>=0,d=c?"height":"width";if(!(!a||!l)){var u=U8(r.padding,n),p=_p(a),f=s==="y"?mn:gn,h=s==="y"?Kn:Wn,b=n.rects.reference[d]+n.rects.reference[s]-l[s]-n.rects.popper[d],m=l[s]-n.rects.reference[s],g=ci(a),v=g?s==="y"?g.clientHeight||0:g.clientWidth||0:0,y=b/2-m/2,T=u[f],w=v-p[d]-u[h],k=v/2-p[d]/2+y,$=yl(T,k,w),z=s;n.modifiersData[o]=(t={},t[z]=$,t.centerOffset=$-k,t)}}function G8(e){var t=e.state,n=e.options,o=n.element,r=o===void 0?"[data-popper-arrow]":o;r!=null&&(typeof r=="string"&&(r=t.elements.popper.querySelector(r),!r)||!Hy(t.elements.popper,r)||(t.elements.arrow=r))}var X8={name:"arrow",enabled:!0,phase:"main",fn:Y8,effect:G8,requires:["popperOffsets"],requiresIfExists:["preventOverflow"]};function Na(e){return e.split("-")[1]}var Z8={top:"auto",right:"auto",bottom:"auto",left:"auto"};function J8(e){var t=e.x,n=e.y,o=window,r=o.devicePixelRatio||1;return{x:Aa(t*r)/r||0,y:Aa(n*r)/r||0}}function pm(e){var t,n=e.popper,o=e.popperRect,r=e.placement,a=e.variation,l=e.offsets,i=e.position,s=e.gpuAcceleration,c=e.adaptive,d=e.roundOffsets,u=e.isFixed,p=l.x,f=p===void 0?0:p,h=l.y,b=h===void 0?0:h,m=typeof d=="function"?d({x:f,y:b}):{x:f,y:b};f=m.x,b=m.y;var g=l.hasOwnProperty("x"),v=l.hasOwnProperty("y"),y=gn,T=mn,w=window;if(c){var k=ci(n),$="clientHeight",z="clientWidth";if(k===po(n)&&(k=mr(n),Fo(k).position!=="static"&&i==="absolute"&&($="scrollHeight",z="scrollWidth")),k=k,r===mn||(r===gn||r===Wn)&&a===Hl){T=Kn;var O=u&&k===w&&w.visualViewport?w.visualViewport.height:k[$];b-=O-o.height,b*=s?1:-1}if(r===gn||(r===mn||r===Kn)&&a===Hl){y=Wn;var R=u&&k===w&&w.visualViewport?w.visualViewport.width:k[z];f-=R-o.width,f*=s?1:-1}}var F=Object.assign({position:i},c&&Z8),L=d===!0?J8({x:f,y:b}):{x:f,y:b};if(f=L.x,b=L.y,s){var D;return Object.assign({},F,(D={},D[T]=v?"0":"",D[y]=g?"0":"",D.transform=(w.devicePixelRatio||1)<=1?"translate("+f+"px, "+b+"px)":"translate3d("+f+"px, "+b+"px, 0)",D))}return Object.assign({},F,(t={},t[T]=v?b+"px":"",t[y]=g?f+"px":"",t.transform="",t))}function Q8(e){var t=e.state,n=e.options,o=n.gpuAcceleration,r=o===void 0?!0:o,a=n.adaptive,l=a===void 0?!0:a,i=n.roundOffsets,s=i===void 0?!0:i,c={placement:vo(t.placement),variation:Na(t.placement),popper:t.elements.popper,popperRect:t.rects.popper,gpuAcceleration:r,isFixed:t.options.strategy==="fixed"};t.modifiersData.popperOffsets!=null&&(t.styles.popper=Object.assign({},t.styles.popper,pm(Object.assign({},c,{offsets:t.modifiersData.popperOffsets,position:t.options.strategy,adaptive:l,roundOffsets:s})))),t.modifiersData.arrow!=null&&(t.styles.arrow=Object.assign({},t.styles.arrow,pm(Object.assign({},c,{offsets:t.modifiersData.arrow,position:"absolute",adaptive:!1,roundOffsets:s})))),t.attributes.popper=Object.assign({},t.attributes.popper,{"data-popper-placement":t.placement})}var eI={name:"computeStyles",enabled:!0,phase:"beforeWrite",fn:Q8,data:{}},Ci={passive:!0};function tI(e){var t=e.state,n=e.instance,o=e.options,r=o.scroll,a=r===void 0?!0:r,l=o.resize,i=l===void 0?!0:l,s=po(t.elements.popper),c=[].concat(t.scrollParents.reference,t.scrollParents.popper);return a&&c.forEach(function(d){d.addEventListener("scroll",n.update,Ci)}),i&&s.addEventListener("resize",n.update,Ci),function(){a&&c.forEach(function(d){d.removeEventListener("scroll",n.update,Ci)}),i&&s.removeEventListener("resize",n.update,Ci)}}var nI={name:"eventListeners",enabled:!0,phase:"write",fn:function(){},effect:tI,data:{}},oI={left:"right",right:"left",bottom:"top",top:"bottom"};function ji(e){return e.replace(/left|right|bottom|top/g,function(t){return oI[t]})}var rI={start:"end",end:"start"};function fm(e){return e.replace(/start|end/g,function(t){return rI[t]})}function xp(e){var t=po(e),n=t.pageXOffset,o=t.pageYOffset;return{scrollLeft:n,scrollTop:o}}function kp(e){return za(mr(e)).left+xp(e).scrollLeft}function aI(e){var t=po(e),n=mr(e),o=t.visualViewport,r=n.clientWidth,a=n.clientHeight,l=0,i=0;return o&&(r=o.width,a=o.height,/^((?!chrome|android).)*safari/i.test(navigator.userAgent)||(l=o.offsetLeft,i=o.offsetTop)),{width:r,height:a,x:l+kp(e),y:i}}function lI(e){var t,n=mr(e),o=xp(e),r=(t=e.ownerDocument)==null?void 0:t.body,a=Fr(n.scrollWidth,n.clientWidth,r?r.scrollWidth:0,r?r.clientWidth:0),l=Fr(n.scrollHeight,n.clientHeight,r?r.scrollHeight:0,r?r.clientHeight:0),i=-o.scrollLeft+kp(e),s=-o.scrollTop;return Fo(r||n).direction==="rtl"&&(i+=Fr(n.clientWidth,r?r.clientWidth:0)-a),{width:a,height:l,x:i,y:s}}function Tp(e){var t=Fo(e),n=t.overflow,o=t.overflowX,r=t.overflowY;return/auto|scroll|overlay|hidden/.test(n+r+o)}function Uy(e){return["html","body","#document"].indexOf(_o(e))>=0?e.ownerDocument.body:Ln(e)&&Tp(e)?e:Uy(fc(e))}function _l(e,t){var n;t===void 0&&(t=[]);var o=Uy(e),r=o===((n=e.ownerDocument)==null?void 0:n.body),a=po(o),l=r?[a].concat(a.visualViewport||[],Tp(o)?o:[]):o,i=t.concat(l);return r?i:i.concat(_l(fc(l)))}function Od(e){return Object.assign({},e,{left:e.x,top:e.y,right:e.x+e.width,bottom:e.y+e.height})}function iI(e){var t=za(e);return t.top=t.top+e.clientTop,t.left=t.left+e.clientLeft,t.bottom=t.top+e.clientHeight,t.right=t.left+e.clientWidth,t.width=e.clientWidth,t.height=e.clientHeight,t.x=t.left,t.y=t.top,t}function hm(e,t){return t===jy?Od(aI(e)):Ea(t)?iI(t):Od(lI(mr(e)))}function sI(e){var t=_l(fc(e)),n=["absolute","fixed"].indexOf(Fo(e).position)>=0,o=n&&Ln(e)?ci(e):e;return Ea(o)?t.filter(function(r){return Ea(r)&&Hy(r,o)&&_o(r)!=="body"}):[]}function cI(e,t,n){var o=t==="clippingParents"?sI(e):[].concat(t),r=[].concat(o,[n]),a=r[0],l=r.reduce(function(i,s){var c=hm(e,s);return i.top=Fr(c.top,i.top),i.right=As(c.right,i.right),i.bottom=As(c.bottom,i.bottom),i.left=Fr(c.left,i.left),i},hm(e,a));return l.width=l.right-l.left,l.height=l.bottom-l.top,l.x=l.left,l.y=l.top,l}function Yy(e){var t=e.reference,n=e.element,o=e.placement,r=o?vo(o):null,a=o?Na(o):null,l=t.x+t.width/2-n.width/2,i=t.y+t.height/2-n.height/2,s;switch(r){case mn:s={x:l,y:t.y-n.height};break;case Kn:s={x:l,y:t.y+t.height};break;case Wn:s={x:t.x+t.width,y:i};break;case gn:s={x:t.x-n.width,y:i};break;default:s={x:t.x,y:t.y}}var c=r?wp(r):null;if(c!=null){var d=c==="y"?"height":"width";switch(a){case $a:s[c]=s[c]-(t[d]/2-n[d]/2);break;case Hl:s[c]=s[c]+(t[d]/2-n[d]/2);break}}return s}function ql(e,t){t===void 0&&(t={});var n=t,o=n.placement,r=o===void 0?e.placement:o,a=n.boundary,l=a===void 0?A8:a,i=n.rootBoundary,s=i===void 0?jy:i,c=n.elementContext,d=c===void 0?tl:c,u=n.altBoundary,p=u===void 0?!1:u,f=n.padding,h=f===void 0?0:f,b=Ky(typeof h!="number"?h:Wy(h,si)),m=d===tl?z8:tl,g=e.rects.popper,v=e.elements[p?m:d],y=cI(Ea(v)?v:v.contextElement||mr(e.elements.popper),l,s),T=za(e.elements.reference),w=Yy({reference:T,element:g,strategy:"absolute",placement:r}),k=Od(Object.assign({},g,w)),$=d===tl?k:T,z={top:y.top-$.top+b.top,bottom:$.bottom-y.bottom+b.bottom,left:y.left-$.left+b.left,right:$.right-y.right+b.right},O=e.modifiersData.offset;if(d===tl&&O){var R=O[r];Object.keys(z).forEach(function(F){var L=[Wn,Kn].indexOf(F)>=0?1:-1,D=[mn,Kn].indexOf(F)>=0?"y":"x";z[F]+=R[D]*L})}return z}function dI(e,t){t===void 0&&(t={});var n=t,o=n.placement,r=n.boundary,a=n.rootBoundary,l=n.padding,i=n.flipVariations,s=n.allowedAutoPlacements,c=s===void 0?vp:s,d=Na(o),u=d?i?dm:dm.filter(function(h){return Na(h)===d}):si,p=u.filter(function(h){return c.indexOf(h)>=0});p.length===0&&(p=u);var f=p.reduce(function(h,b){return h[b]=ql(e,{placement:b,boundary:r,rootBoundary:a,padding:l})[vo(b)],h},{});return Object.keys(f).sort(function(h,b){return f[h]-f[b]})}function uI(e){if(vo(e)===bp)return[];var t=ji(e);return[fm(e),t,fm(t)]}function pI(e){var t=e.state,n=e.options,o=e.name;if(!t.modifiersData[o]._skip){for(var r=n.mainAxis,a=r===void 0?!0:r,l=n.altAxis,i=l===void 0?!0:l,s=n.fallbackPlacements,c=n.padding,d=n.boundary,u=n.rootBoundary,p=n.altBoundary,f=n.flipVariations,h=f===void 0?!0:f,b=n.allowedAutoPlacements,m=t.options.placement,g=vo(m),v=g===m,y=s||(v||!h?[ji(m)]:uI(m)),T=[m].concat(y).reduce(function(Se,oe){return Se.concat(vo(oe)===bp?dI(t,{placement:oe,boundary:d,rootBoundary:u,padding:c,flipVariations:h,allowedAutoPlacements:b}):oe)},[]),w=t.rects.reference,k=t.rects.popper,$=new Map,z=!0,O=T[0],R=0;R=0,q=V?"width":"height",P=ql(t,{placement:F,boundary:d,rootBoundary:u,altBoundary:p,padding:c}),A=V?D?Wn:gn:D?Kn:mn;w[q]>k[q]&&(A=ji(A));var I=ji(A),W=[];if(a&&W.push(P[L]<=0),i&&W.push(P[A]<=0,P[I]<=0),W.every(function(Se){return Se})){O=F,z=!1;break}$.set(F,W)}if(z)for(var Y=h?3:1,J=function(oe){var H=T.find(function(ne){var le=$.get(ne);if(le)return le.slice(0,oe).every(function(be){return be})});if(H)return O=H,"break"},Z=Y;Z>0;Z--){var se=J(Z);if(se==="break")break}t.placement!==O&&(t.modifiersData[o]._skip=!0,t.placement=O,t.reset=!0)}}var fI={name:"flip",enabled:!0,phase:"main",fn:pI,requiresIfExists:["offset"],data:{_skip:!1}};function mm(e,t,n){return n===void 0&&(n={x:0,y:0}),{top:e.top-t.height-n.y,right:e.right-t.width+n.x,bottom:e.bottom-t.height+n.y,left:e.left-t.width-n.x}}function gm(e){return[mn,Wn,Kn,gn].some(function(t){return e[t]>=0})}function hI(e){var t=e.state,n=e.name,o=t.rects.reference,r=t.rects.popper,a=t.modifiersData.preventOverflow,l=ql(t,{elementContext:"reference"}),i=ql(t,{altBoundary:!0}),s=mm(l,o),c=mm(i,r,a),d=gm(s),u=gm(c);t.modifiersData[n]={referenceClippingOffsets:s,popperEscapeOffsets:c,isReferenceHidden:d,hasPopperEscaped:u},t.attributes.popper=Object.assign({},t.attributes.popper,{"data-popper-reference-hidden":d,"data-popper-escaped":u})}var mI={name:"hide",enabled:!0,phase:"main",requiresIfExists:["preventOverflow"],fn:hI};function gI(e,t,n){var o=vo(e),r=[gn,mn].indexOf(o)>=0?-1:1,a=typeof n=="function"?n(Object.assign({},t,{placement:e})):n,l=a[0],i=a[1];return l=l||0,i=(i||0)*r,[gn,Wn].indexOf(o)>=0?{x:i,y:l}:{x:l,y:i}}function bI(e){var t=e.state,n=e.options,o=e.name,r=n.offset,a=r===void 0?[0,0]:r,l=vp.reduce(function(d,u){return d[u]=gI(u,t.rects,a),d},{}),i=l[t.placement],s=i.x,c=i.y;t.modifiersData.popperOffsets!=null&&(t.modifiersData.popperOffsets.x+=s,t.modifiersData.popperOffsets.y+=c),t.modifiersData[o]=l}var vI={name:"offset",enabled:!0,phase:"main",requires:["popperOffsets"],fn:bI};function yI(e){var t=e.state,n=e.name;t.modifiersData[n]=Yy({reference:t.rects.reference,element:t.rects.popper,strategy:"absolute",placement:t.placement})}var _I={name:"popperOffsets",enabled:!0,phase:"read",fn:yI,data:{}};function wI(e){return e==="x"?"y":"x"}function xI(e){var t=e.state,n=e.options,o=e.name,r=n.mainAxis,a=r===void 0?!0:r,l=n.altAxis,i=l===void 0?!1:l,s=n.boundary,c=n.rootBoundary,d=n.altBoundary,u=n.padding,p=n.tether,f=p===void 0?!0:p,h=n.tetherOffset,b=h===void 0?0:h,m=ql(t,{boundary:s,rootBoundary:c,padding:u,altBoundary:d}),g=vo(t.placement),v=Na(t.placement),y=!v,T=wp(g),w=wI(T),k=t.modifiersData.popperOffsets,$=t.rects.reference,z=t.rects.popper,O=typeof b=="function"?b(Object.assign({},t.rects,{placement:t.placement})):b,R=typeof O=="number"?{mainAxis:O,altAxis:O}:Object.assign({mainAxis:0,altAxis:0},O),F=t.modifiersData.offset?t.modifiersData.offset[t.placement]:null,L={x:0,y:0};if(!!k){if(a){var D,V=T==="y"?mn:gn,q=T==="y"?Kn:Wn,P=T==="y"?"height":"width",A=k[T],I=A+m[V],W=A-m[q],Y=f?-z[P]/2:0,J=v===$a?$[P]:z[P],Z=v===$a?-z[P]:-$[P],se=t.elements.arrow,Se=f&&se?_p(se):{width:0,height:0},oe=t.modifiersData["arrow#persistent"]?t.modifiersData["arrow#persistent"].padding:qy(),H=oe[V],ne=oe[q],le=yl(0,$[P],Se[P]),be=y?$[P]/2-Y-le-H-R.mainAxis:J-le-H-R.mainAxis,$e=y?-$[P]/2+Y+le+ne+R.mainAxis:Z+le+ne+R.mainAxis,Ie=t.elements.arrow&&ci(t.elements.arrow),Me=Ie?T==="y"?Ie.clientTop||0:Ie.clientLeft||0:0,j=(D=F==null?void 0:F[T])!=null?D:0,X=A+be-j-Me,de=A+$e-j,xe=yl(f?As(I,X):I,A,f?Fr(W,de):W);k[T]=xe,L[T]=xe-A}if(i){var we,Ee=T==="x"?mn:gn,ce=T==="x"?Kn:Wn,ae=k[w],te=w==="y"?"height":"width",pe=ae+m[Ee],Fe=ae-m[ce],B=[mn,gn].indexOf(g)!==-1,me=(we=F==null?void 0:F[w])!=null?we:0,Be=B?pe:ae-$[te]-z[te]-me+R.altAxis,Ze=B?ae+$[te]+z[te]-me-R.altAxis:Fe,Ve=f&&B?W8(Be,ae,Ze):yl(f?Be:pe,ae,f?Ze:Fe);k[w]=Ve,L[w]=Ve-ae}t.modifiersData[o]=L}}var kI={name:"preventOverflow",enabled:!0,phase:"main",fn:xI,requiresIfExists:["offset"]};function TI(e){return{scrollLeft:e.scrollLeft,scrollTop:e.scrollTop}}function CI(e){return e===po(e)||!Ln(e)?xp(e):TI(e)}function SI(e){var t=e.getBoundingClientRect(),n=Aa(t.width)/e.offsetWidth||1,o=Aa(t.height)/e.offsetHeight||1;return n!==1||o!==1}function $I(e,t,n){n===void 0&&(n=!1);var o=Ln(t),r=Ln(t)&&SI(t),a=mr(t),l=za(e,r),i={scrollLeft:0,scrollTop:0},s={x:0,y:0};return(o||!o&&!n)&&((_o(t)!=="body"||Tp(a))&&(i=CI(t)),Ln(t)?(s=za(t,!0),s.x+=t.clientLeft,s.y+=t.clientTop):a&&(s.x=kp(a))),{x:l.left+i.scrollLeft-s.x,y:l.top+i.scrollTop-s.y,width:l.width,height:l.height}}function EI(e){var t=new Map,n=new Set,o=[];e.forEach(function(a){t.set(a.name,a)});function r(a){n.add(a.name);var l=[].concat(a.requires||[],a.requiresIfExists||[]);l.forEach(function(i){if(!n.has(i)){var s=t.get(i);s&&r(s)}}),o.push(a)}return e.forEach(function(a){n.has(a.name)||r(a)}),o}function AI(e){var t=EI(e);return V8.reduce(function(n,o){return n.concat(t.filter(function(r){return r.phase===o}))},[])}function zI(e){var t;return function(){return t||(t=new Promise(function(n){Promise.resolve().then(function(){t=void 0,n(e())})})),t}}function NI(e){var t=e.reduce(function(n,o){var r=n[o.name];return n[o.name]=r?Object.assign({},r,o,{options:Object.assign({},r.options,o.options),data:Object.assign({},r.data,o.data)}):o,n},{});return Object.keys(t).map(function(n){return t[n]})}var bm={placement:"bottom",modifiers:[],strategy:"absolute"};function vm(){for(var e=arguments.length,t=new Array(e),n=0;n[]},gpuAcceleration:{type:Boolean,default:!0},offset:{type:Number,default:12},placement:{type:String,values:vp,default:"bottom"},popperOptions:{type:Te(Object),default:()=>({})},strategy:{type:String,values:PI,default:"absolute"}}),Xy=Le(ze(he({},OI),{style:{type:Te([String,Array,Object])},className:{type:Te([String,Array,Object])},effect:{type:String,default:"dark"},visible:Boolean,enterable:{type:Boolean,default:!0},pure:Boolean,popperClass:{type:Te([String,Array,Object])},popperStyle:{type:Te([String,Array,Object])},referenceEl:{type:Te(Object)},stopPopperMouseEvent:{type:Boolean,default:!0},zIndex:Number})),ym=(e,t)=>{const{placement:n,strategy:o,popperOptions:r}=e,a=ze(he({placement:n,strategy:o},r),{modifiers:DI(e)});return FI(a,t),LI(a,r==null?void 0:r.modifiers),a},RI=e=>{if(!!dt)return no(e)};function DI(e){const{offset:t,gpuAcceleration:n,fallbackPlacements:o}=e;return[{name:"offset",options:{offset:[0,t!=null?t:12]}},{name:"preventOverflow",options:{padding:{top:2,bottom:2,left:5,right:5}}},{name:"flip",options:{padding:5,fallbackPlacements:o!=null?o:[]}},{name:"computeStyles",options:{gpuAcceleration:n,adaptive:n}}]}function FI(e,{arrowEl:t,arrowOffset:n}){e.modifiers.push({name:"arrow",options:{element:t,padding:n!=null?n:5}})}function LI(e,t){t&&(e.modifiers=[...e.modifiers,...t!=null?t:[]])}const VI={name:"ElPopperContent"},BI=ee(ze(he({},VI),{props:Xy,emits:["mouseenter","mouseleave"],setup(e,{expose:t}){const n=e,{popperInstanceRef:o,contentRef:r,triggerRef:a}=Ne(up,void 0),{nextZIndex:l}=jo(),i=ke("popper"),s=E(),c=E(),d=E();ot(yy,{arrowRef:c,arrowOffset:d});const u=E(n.zIndex||l()),p=C(()=>RI(n.referenceEl)||_(a)),f=C(()=>[{zIndex:_(u)},n.popperStyle]),h=C(()=>[i.b(),i.is("pure",n.pure),i.is(n.effect),n.popperClass]),b=({referenceEl:v,popperContentEl:y,arrowEl:T})=>{const w=ym(n,{arrowEl:T,arrowOffset:_(d)});return Gy(v,y,w)},m=()=>{var v;(v=_(o))==null||v.update(),u.value=n.zIndex||u.value||l()},g=()=>{var v,y;const T={name:"eventListeners",enabled:n.visible};(y=(v=_(o))==null?void 0:v.setOptions)==null||y.call(v,w=>ze(he({},w),{modifiers:[...w.modifiers||[],T]})),m()};return et(()=>{let v;ge(p,y=>{var T;v==null||v();const w=_(o);if((T=w==null?void 0:w.destroy)==null||T.call(w),y){const k=_(s);r.value=k,o.value=b({referenceEl:y,popperContentEl:k,arrowEl:_(c)}),v=ge(()=>y.getBoundingClientRect(),()=>m(),{immediate:!0})}else o.value=void 0},{immediate:!0}),ge(()=>n.visible,g,{immediate:!0}),ge(()=>ym(n,{arrowEl:_(c),arrowOffset:_(d)}),y=>{var T;return(T=o.value)==null?void 0:T.setOptions(y)})}),t({popperContentRef:s,popperInstanceRef:o,updatePopper:m,contentStyle:f}),(v,y)=>(x(),N("div",{ref_key:"popperContentRef",ref:s,style:Re(_(f)),class:S(_(h)),role:"tooltip",onMouseenter:y[0]||(y[0]=T=>v.$emit("mouseenter",T)),onMouseleave:y[1]||(y[1]=T=>v.$emit("mouseleave",T))},[ue(v.$slots,"default")],38))}}));var jI=_e(BI,[["__file","/home/runner/work/element-plus/element-plus/packages/components/popper/src/content.vue"]]);const HI={LIGHT:"light",DARK:"dark"};Le({autoClose:{type:Number,default:0},cutoff:{type:Boolean,default:!1},disabled:{type:Boolean,default:!1}});function Wa(e,t){const n=nt(),o=C(()=>on(n.props[t])?n.props[t]:n.props.teleported);return li({scope:e,from:t,replacement:"teleported",version:"2.1.0",ref:"https://element-plus.org/en-US/component/tooltip.html#attributes"},C(()=>on(n.props[t]))),{compatTeleported:o}}const Zy=rt(_8),qI=ee({name:"ElVisuallyHidden",props:{style:{type:[String,Object,Array]}},setup(e){return{computedStyle:C(()=>[e.style,{position:"absolute",border:0,width:1,height:1,padding:0,margin:-1,overflow:"hidden",clip:"rect(0, 0, 0, 0)",whiteSpace:"nowrap",wordWrap:"normal"}])}}});function KI(e,t,n,o,r,a){return x(),N("span",St(e.$attrs,{style:e.computedStyle}),[ue(e.$slots,"default")],16)}var Jy=_e(qI,[["render",KI],["__file","/home/runner/work/element-plus/element-plus/packages/components/visual-hidden/src/visual-hidden.vue"]]);const tn=Le(ze(he(he({},iN),Xy),{appendTo:{type:Te([String,Object]),default:Ey},content:{type:String,default:""},rawContent:{type:Boolean,default:!1},persistent:Boolean,ariaLabel:String,visible:{type:Te(Boolean),default:null},transition:{type:String,default:"el-fade-in-linear"},teleported:{type:Boolean,default:!0},disabled:{type:Boolean}})),Kl=Le(ze(he({},By),{disabled:Boolean,trigger:{type:Te([String,Array]),default:"hover"}})),WI=Le({openDelay:{type:Number},visibleArrow:{type:Boolean,default:void 0},hideAfter:{type:Number,default:200},showArrow:{type:Boolean,default:!0}}),hc=Symbol("elTooltip"),UI=ee({name:"ElTooltipContent",components:{ElPopperContent:jI,ElVisuallyHidden:Jy},inheritAttrs:!1,props:tn,setup(e){const t=E(null),n=E(!1),o=E(!1),r=E(!1),a=E(!1),{controlled:l,id:i,open:s,trigger:c,onClose:d,onOpen:u,onShow:p,onHide:f,onBeforeShow:h,onBeforeHide:b}=Ne(hc,void 0),m=C(()=>e.persistent);$t(()=>{a.value=!0});const g=C(()=>_(m)?!0:_(s)),v=C(()=>e.disabled?!1:_(s)),y=C(()=>{var D;return(D=e.style)!=null?D:{}}),T=C(()=>!_(s));rN(d);const w=()=>{f()},k=()=>{if(_(l))return!0},$=Rt(k,()=>{e.enterable&&_(c)==="hover"&&u()}),z=Rt(k,()=>{_(c)==="hover"&&d()}),O=()=>{var D,V;(V=(D=t.value)==null?void 0:D.updatePopper)==null||V.call(D),h==null||h()},R=()=>{b==null||b()},F=()=>{p()};let L;return ge(()=>_(s),D=>{D?L=Cs(C(()=>{var V;return(V=t.value)==null?void 0:V.popperContentRef}),()=>{if(_(l))return;_(c)!=="hover"&&d()}):L==null||L()},{flush:"post"}),{ariaHidden:T,entering:o,leaving:r,id:i,intermediateOpen:n,contentStyle:y,contentRef:t,destroyed:a,shouldRender:g,shouldShow:v,open:s,onAfterShow:F,onBeforeEnter:O,onBeforeLeave:R,onContentEnter:$,onContentLeave:z,onTransitionLeave:w}}});function YI(e,t,n,o,r,a){const l=ie("el-visually-hidden"),i=ie("el-popper-content");return x(),Q(ei,{disabled:!e.teleported,to:e.appendTo},[U(qt,{name:e.transition,onAfterLeave:e.onTransitionLeave,onBeforeEnter:e.onBeforeEnter,onAfterEnter:e.onAfterShow,onBeforeLeave:e.onBeforeLeave},{default:K(()=>[e.shouldRender?Ue((x(),Q(i,St({key:0,ref:"contentRef"},e.$attrs,{"aria-hidden":e.ariaHidden,"boundaries-padding":e.boundariesPadding,"fallback-placements":e.fallbackPlacements,"gpu-acceleration":e.gpuAcceleration,offset:e.offset,placement:e.placement,"popper-options":e.popperOptions,strategy:e.strategy,effect:e.effect,enterable:e.enterable,pure:e.pure,"popper-class":e.popperClass,"popper-style":[e.popperStyle,e.contentStyle],"reference-el":e.referenceEl,visible:e.shouldShow,"z-index":e.zIndex,onMouseenter:e.onContentEnter,onMouseleave:e.onContentLeave}),{default:K(()=>[G(" Workaround bug #6378 "),e.destroyed?G("v-if",!0):(x(),N(De,{key:0},[ue(e.$slots,"default"),U(l,{id:e.id,role:"tooltip"},{default:K(()=>[lt(ve(e.ariaLabel),1)]),_:1},8,["id"])],64))]),_:3},16,["aria-hidden","boundaries-padding","fallback-placements","gpu-acceleration","offset","placement","popper-options","strategy","effect","enterable","pure","popper-class","popper-style","reference-el","visible","z-index","onMouseenter","onMouseleave"])),[[ft,e.shouldShow]]):G("v-if",!0)]),_:3},8,["name","onAfterLeave","onBeforeEnter","onAfterEnter","onBeforeLeave"])],8,["disabled","to"])}var GI=_e(UI,[["render",YI],["__file","/home/runner/work/element-plus/element-plus/packages/components/tooltip/src/content.vue"]]);const XI=(e,t)=>Ye(e)?e.includes(t):e===t,ea=(e,t,n)=>o=>{XI(_(e),t)&&n(o)},ZI=ee({name:"ElTooltipTrigger",components:{ElPopperTrigger:E8},props:Kl,setup(e){const t=ke("tooltip"),{controlled:n,id:o,open:r,onOpen:a,onClose:l,onToggle:i}=Ne(hc,void 0),s=E(null),c=()=>{if(_(n)||e.disabled)return!0},d=Yt(e,"trigger"),u=Rt(c,ea(d,"hover",a)),p=Rt(c,ea(d,"hover",l)),f=Rt(c,ea(d,"click",v=>{v.button===0&&i(v)})),h=Rt(c,ea(d,"focus",a)),b=Rt(c,ea(d,"focus",l)),m=Rt(c,ea(d,"contextmenu",v=>{v.preventDefault(),i(v)})),g=Rt(c,v=>{const{code:y}=v;(y===Oe.enter||y===Oe.space)&&i(v)});return{onBlur:b,onContextMenu:m,onFocus:h,onMouseenter:u,onMouseleave:p,onClick:f,onKeydown:g,open:r,id:o,triggerRef:s,ns:t}}});function JI(e,t,n,o,r,a){const l=ie("el-popper-trigger");return x(),Q(l,{id:e.id,"virtual-ref":e.virtualRef,open:e.open,"virtual-triggering":e.virtualTriggering,class:S(e.ns.e("trigger")),onBlur:e.onBlur,onClick:e.onClick,onContextmenu:e.onContextMenu,onFocus:e.onFocus,onMouseenter:e.onMouseenter,onMouseleave:e.onMouseleave,onKeydown:e.onKeydown},{default:K(()=>[ue(e.$slots,"default")]),_:3},8,["id","virtual-ref","open","virtual-triggering","class","onBlur","onClick","onContextmenu","onFocus","onMouseenter","onMouseleave","onKeydown"])}var QI=_e(ZI,[["render",JI],["__file","/home/runner/work/element-plus/element-plus/packages/components/tooltip/src/trigger.vue"]]);const{useModelToggleProps:eM,useModelToggle:tM,useModelToggleEmits:nM}=Jz("visible"),oM=ee({name:"ElTooltip",components:{ElPopper:Zy,ElPopperArrow:k8,ElTooltipContent:GI,ElTooltipTrigger:QI},props:he(he(he(he(he({},eM),tn),Kl),Ly),WI),emits:[...nM,"before-show","before-hide","show","hide"],setup(e,{emit:t}){lN();const n=C(()=>(Cn(e.openDelay),e.openDelay||e.showAfter)),o=C(()=>(Cn(e.visibleArrow),on(e.visibleArrow)?e.visibleArrow:e.showArrow)),r=fp(),a=E(null),l=()=>{var f;const h=_(a);h&&((f=h.popperInstanceRef)==null||f.update())},i=E(!1),{show:s,hide:c}=tM({indicator:i}),{onOpen:d,onClose:u}=sN({showAfter:n,hideAfter:Yt(e,"hideAfter"),open:s,close:c}),p=C(()=>on(e.visible));return ot(hc,{controlled:p,id:r,open:Zl(i),trigger:Yt(e,"trigger"),onOpen:d,onClose:u,onToggle:()=>{_(i)?u():d()},onShow:()=>{t("show")},onHide:()=>{t("hide")},onBeforeShow:()=>{t("before-show")},onBeforeHide:()=>{t("before-hide")},updatePopper:l}),ge(()=>e.disabled,f=>{f&&i.value&&(i.value=!1)}),{compatShowAfter:n,compatShowArrow:o,popperRef:a,open:i,hide:c,updatePopper:l,onOpen:d,onClose:u}}}),rM=["innerHTML"],aM={key:1};function lM(e,t,n,o,r,a){const l=ie("el-tooltip-trigger"),i=ie("el-popper-arrow"),s=ie("el-tooltip-content"),c=ie("el-popper");return x(),Q(c,{ref:"popperRef"},{default:K(()=>[U(l,{disabled:e.disabled,trigger:e.trigger,"virtual-ref":e.virtualRef,"virtual-triggering":e.virtualTriggering},{default:K(()=>[e.$slots.default?ue(e.$slots,"default",{key:0}):G("v-if",!0)]),_:3},8,["disabled","trigger","virtual-ref","virtual-triggering"]),U(s,{"aria-label":e.ariaLabel,"boundaries-padding":e.boundariesPadding,content:e.content,disabled:e.disabled,effect:e.effect,enterable:e.enterable,"fallback-placements":e.fallbackPlacements,"hide-after":e.hideAfter,"gpu-acceleration":e.gpuAcceleration,offset:e.offset,persistent:e.persistent,"popper-class":e.popperClass,"popper-style":e.popperStyle,placement:e.placement,"popper-options":e.popperOptions,pure:e.pure,"raw-content":e.rawContent,"reference-el":e.referenceEl,"show-after":e.compatShowAfter,strategy:e.strategy,teleported:e.teleported,transition:e.transition,"z-index":e.zIndex,"append-to":e.appendTo},{default:K(()=>[ue(e.$slots,"content",{},()=>[e.rawContent?(x(),N("span",{key:0,innerHTML:e.content},null,8,rM)):(x(),N("span",aM,ve(e.content),1))]),e.compatShowArrow?(x(),Q(i,{key:0,"arrow-offset":e.arrowOffset},null,8,["arrow-offset"])):G("v-if",!0)]),_:3},8,["aria-label","boundaries-padding","content","disabled","effect","enterable","fallback-placements","hide-after","gpu-acceleration","offset","persistent","popper-class","popper-style","placement","popper-options","pure","raw-content","reference-el","show-after","strategy","teleported","transition","z-index","append-to"])]),_:3},512)}var iM=_e(oM,[["render",lM],["__file","/home/runner/work/element-plus/element-plus/packages/components/tooltip/src/tooltip.vue"]]);const vn=rt(iM),sM=Le({valueKey:{type:String,default:"value"},modelValue:{type:[String,Number],default:""},debounce:{type:Number,default:300},placement:{type:Te(String),values:["top","top-start","top-end","bottom","bottom-start","bottom-end"],default:"bottom-start"},fetchSuggestions:{type:Te([Function,Array]),default:wt},popperClass:{type:String,default:""},triggerOnFocus:{type:Boolean,default:!0},selectWhenUnmatched:{type:Boolean,default:!1},hideLoading:{type:Boolean,default:!1},popperAppendToBody:{type:Boolean,default:void 0},teleported:tn.teleported,highlightFirstItem:{type:Boolean,default:!1}}),cM={[tt]:e=>Qe(e),input:e=>Qe(e),change:e=>Qe(e),focus:e=>e instanceof FocusEvent,blur:e=>e instanceof FocusEvent,clear:()=>!0,select:e=>ut(e)},dM=["aria-expanded","aria-owns"],uM={key:0},pM=["id","aria-selected","onClick"],fM={name:"ElAutocomplete",inheritAttrs:!1},hM=ee(ze(he({},fM),{props:sM,emits:cM,setup(e,{expose:t,emit:n}){const o=e,r="ElAutocomplete",a=ke("autocomplete"),{compatTeleported:l}=Wa(r,"popperAppendToBody");let i=!1;const s=dp(),c=Ob(),d=E([]),u=E(-1),p=E(""),f=E(!1),h=E(!1),b=E(!1),m=E(),g=E(),v=E(),y=E(),T=C(()=>a.b(String(ai()))),w=C(()=>c.style),k=C(()=>(Ye(d.value)&&d.value.length>0||b.value)&&f.value),$=C(()=>!o.hideLoading&&b.value),z=()=>{je(()=>{k.value&&(p.value=`${m.value.$el.offsetWidth}px`)})},R=bn(J=>{if(h.value)return;b.value=!0;const Z=se=>{b.value=!1,!h.value&&(Ye(se)?(d.value=se,u.value=o.highlightFirstItem?0:-1):Wt(r,"autocomplete suggestions must be an array"))};if(Ye(o.fetchSuggestions))Z(o.fetchSuggestions);else{const se=o.fetchSuggestions(J,Z);Ye(se)?Z(se):Vr(se)&&se.then(Z)}},o.debounce),F=J=>{const Z=Boolean(J);if(n("input",J),n(tt,J),h.value=!1,f.value||(f.value=i&&Z),!o.triggerOnFocus&&!J){h.value=!0,d.value=[];return}i&&Z&&(i=!1),R(J)},L=J=>{n("change",J)},D=J=>{f.value=!0,n("focus",J),o.triggerOnFocus&&R(String(o.modelValue))},V=J=>{n("blur",J)},q=()=>{f.value=!1,i=!0,n(tt,""),n("clear")},P=()=>{k.value&&u.value>=0&&u.value{d.value=[],u.value=-1}))},A=()=>{f.value=!1},I=()=>{var J;(J=m.value)==null||J.focus()},W=J=>{n("input",J[o.valueKey]),n(tt,J[o.valueKey]),n("select",J),je(()=>{d.value=[],u.value=-1})},Y=J=>{if(!k.value||b.value)return;if(J<0){u.value=-1;return}J>=d.value.length&&(J=d.value.length-1);const Z=g.value.querySelector(`.${a.be("suggestion","wrap")}`),Se=Z.querySelectorAll(`.${a.be("suggestion","list")} li`)[J],oe=Z.scrollTop,{offsetTop:H,scrollHeight:ne}=Se;H+ne>oe+Z.clientHeight&&(Z.scrollTop+=ne),H{m.value.ref.setAttribute("role","textbox"),m.value.ref.setAttribute("aria-autocomplete","list"),m.value.ref.setAttribute("aria-controls","id"),m.value.ref.setAttribute("aria-activedescendant",`${T.value}-item-${u.value}`)}),t({highlightedIndex:u,activated:f,loading:b,inputRef:m,popperRef:v,suggestions:d,handleSelect:W,handleKeyEnter:P,focus:I,close:A,highlight:Y}),(J,Z)=>(x(),Q(_(vn),{ref_key:"popperRef",ref:v,visible:_(k),"onUpdate:visible":Z[2]||(Z[2]=se=>Vt(k)?k.value=se:null),placement:J.placement,"fallback-placements":["bottom-start","top-start"],"popper-class":[_(a).e("popper"),J.popperClass],teleported:_(l),"gpu-acceleration":!1,pure:"","manual-mode":"",effect:"light",trigger:"click",transition:`${_(a).namespace.value}-zoom-in-top`,persistent:"",onBeforeShow:z},{content:K(()=>[M("div",{ref_key:"regionRef",ref:g,class:S([_(a).b("suggestion"),_(a).is("loading",_($))]),style:Re({minWidth:p.value,outline:"none"}),role:"region"},[U(_(qo),{id:_(T),tag:"ul","wrap-class":_(a).be("suggestion","wrap"),"view-class":_(a).be("suggestion","list"),role:"listbox"},{default:K(()=>[_($)?(x(),N("li",uM,[U(_(qe),{class:S(_(a).is("loading"))},{default:K(()=>[U(_(hr))]),_:1},8,["class"])])):(x(!0),N(De,{key:1},ct(d.value,(se,Se)=>(x(),N("li",{id:`${_(T)}-item-${Se}`,key:Se,class:S({highlighted:u.value===Se}),role:"option","aria-selected":u.value===Se,onClick:oe=>W(se)},[ue(J.$slots,"default",{item:se},()=>[lt(ve(se[J.valueKey]),1)])],10,pM))),128))]),_:3},8,["id","wrap-class","view-class"])],6)]),default:K(()=>[M("div",{ref_key:"listboxRef",ref:y,class:S([_(a).b(),J.$attrs.class]),style:Re(_(w)),role:"combobox","aria-haspopup":"listbox","aria-expanded":_(k),"aria-owns":_(T)},[U(_(Gn),St({ref_key:"inputRef",ref:m},_(s),{"model-value":J.modelValue,onInput:F,onChange:L,onFocus:D,onBlur:V,onClear:q,onKeydown:[Z[0]||(Z[0]=st(He(se=>Y(u.value-1),["prevent"]),["up"])),Z[1]||(Z[1]=st(He(se=>Y(u.value+1),["prevent"]),["down"])),st(P,["enter"]),st(A,["tab"])]}),dr({_:2},[J.$slots.prepend?{name:"prepend",fn:K(()=>[ue(J.$slots,"prepend")])}:void 0,J.$slots.append?{name:"append",fn:K(()=>[ue(J.$slots,"append")])}:void 0,J.$slots.prefix?{name:"prefix",fn:K(()=>[ue(J.$slots,"prefix")])}:void 0,J.$slots.suffix?{name:"suffix",fn:K(()=>[ue(J.$slots,"suffix")])}:void 0]),1040,["model-value","onKeydown"])],14,dM)]),_:3},8,["visible","placement","popper-class","teleported","transition"]))}}));var mM=_e(hM,[["__file","/home/runner/work/element-plus/element-plus/packages/components/autocomplete/src/autocomplete.vue"]]);const gM=rt(mM),bM=Le({size:{type:[Number,String],values:wo,default:"",validator:e=>typeof e=="number"},shape:{type:String,values:["circle","square"],default:"circle"},icon:{type:an},src:{type:String,default:""},alt:String,srcSet:String,fit:{type:Te(String),default:"cover"}}),vM={error:e=>e instanceof Event},yM=["src","alt","srcset"],_M={name:"ElAvatar"},wM=ee(ze(he({},_M),{props:bM,emits:vM,setup(e,{emit:t}){const n=e,o=ke("avatar"),r=E(!1),a=C(()=>{const{size:c,icon:d,shape:u}=n,p=[o.b()];return Qe(c)&&p.push(o.m(c)),d&&p.push(o.m("icon")),u&&p.push(o.m(u)),p}),l=C(()=>{const{size:c}=n;return mt(c)?{"--el-avatar-size":lo(c)}:void 0}),i=C(()=>({objectFit:n.fit}));ge(()=>n.src,()=>r.value=!1);function s(c){r.value=!0,t("error",c)}return(c,d)=>(x(),N("span",{class:S(_(a)),style:Re(_(l))},[(c.src||c.srcSet)&&!r.value?(x(),N("img",{key:0,src:c.src,alt:c.alt,srcset:c.srcSet,style:Re(_(i)),onError:s},null,44,yM)):c.icon?(x(),Q(_(qe),{key:1},{default:K(()=>[(x(),Q(pt(c.icon)))]),_:1})):ue(c.$slots,"default",{key:2})],6))}}));var xM=_e(wM,[["__file","/home/runner/work/element-plus/element-plus/packages/components/avatar/src/avatar.vue"]]);const kM=rt(xM),TM={visibilityHeight:{type:Number,default:200},target:{type:String,default:""},right:{type:Number,default:40},bottom:{type:Number,default:40}},CM={click:e=>e instanceof MouseEvent},SM=["onClick"],$M={name:"ElBacktop"},EM=ee(ze(he({},$M),{props:TM,emits:CM,setup(e,{emit:t}){const n=e,o="ElBacktop",r=ke("backtop"),a=Kt(),l=Kt(),i=E(!1),s=C(()=>({right:`${n.right}px`,bottom:`${n.bottom}px`})),c=()=>{if(!a.value)return;const f=Date.now(),h=a.value.scrollTop,b=()=>{if(!a.value)return;const m=(Date.now()-f)/500;m<1?(a.value.scrollTop=h*(1-Vz(m)),requestAnimationFrame(b)):a.value.scrollTop=0};requestAnimationFrame(b)},d=()=>{a.value&&(i.value=a.value.scrollTop>=n.visibilityHeight)},u=f=>{c(),t("click",f)},p=Uv(d,300);return et(()=>{var f;l.value=document,a.value=document.documentElement,n.target&&(a.value=(f=document.querySelector(n.target))!=null?f:void 0,a.value||Wt(o,`target is not existed: ${n.target}`),l.value=a.value),Ht(l,"scroll",p)}),(f,h)=>(x(),Q(qt,{name:`${_(r).namespace.value}-fade-in`},{default:K(()=>[i.value?(x(),N("div",{key:0,style:Re(_(s)),class:S(_(r).b()),onClick:He(u,["stop"])},[ue(f.$slots,"default",{},()=>[U(_(qe),{class:S(_(r).e("icon"))},{default:K(()=>[U(_(uE))]),_:1},8,["class"])])],14,SM)):G("v-if",!0)]),_:3},8,["name"]))}}));var AM=_e(EM,[["__file","/home/runner/work/element-plus/element-plus/packages/components/backtop/src/backtop.vue"]]);const zM=rt(AM),NM=Le({value:{type:[String,Number],default:""},max:{type:Number,default:99},isDot:Boolean,hidden:Boolean,type:{type:String,values:["primary","success","warning","info","danger"],default:"danger"}}),IM=["textContent"],MM={name:"ElBadge"},PM=ee(ze(he({},MM),{props:NM,setup(e,{expose:t}){const n=e,o=ke("badge"),r=C(()=>n.isDot?"":mt(n.value)&&mt(n.max)?n.max(x(),N("div",{class:S(_(o).b())},[ue(a.$slots,"default"),U(qt,{name:`${_(o).namespace.value}-zoom-in-center`},{default:K(()=>[Ue(M("sup",{class:S([_(o).e("content"),_(o).em("content",a.type),_(o).is("fixed",!!a.$slots.default),_(o).is("dot",a.isDot)]),textContent:ve(_(r))},null,10,IM),[[ft,!a.hidden&&(_(r)||_(r)==="0"||a.isDot)]])]),_:1},8,["name"])],2))}}));var OM=_e(PM,[["__file","/home/runner/work/element-plus/element-plus/packages/components/badge/src/badge.vue"]]);const Qy=rt(OM),RM=Le({separator:{type:String,default:"/"},separatorIcon:{type:an,default:""}}),DM={name:"ElBreadcrumb"},FM=ee(ze(he({},DM),{props:RM,setup(e){const t=e,n=ke("breadcrumb"),o=E();return ot(sy,t),et(()=>{const r=o.value.querySelectorAll(`.${n.e("item")}`);r.length&&r[r.length-1].setAttribute("aria-current","page")}),(r,a)=>(x(),N("div",{ref_key:"breadcrumb",ref:o,class:S(_(n).b()),"aria-label":"Breadcrumb",role:"navigation"},[ue(r.$slots,"default")],2))}}));var LM=_e(FM,[["__file","/home/runner/work/element-plus/element-plus/packages/components/breadcrumb/src/breadcrumb.vue"]]);const VM=Le({to:{type:Te([String,Object]),default:""},replace:{type:Boolean,default:!1}}),BM={name:"ElBreadcrumbItem"},jM=ee(ze(he({},BM),{props:VM,setup(e){const t=e,o=nt().appContext.config.globalProperties.$router,r=Ne(sy,{}),a=ke("breadcrumb"),{separator:l,separatorIcon:i}=r,s=E(),c=()=>{!t.to||!o||(t.replace?o.replace(t.to):o.push(t.to))};return(d,u)=>(x(),N("span",{class:S(_(a).e("item"))},[M("span",{ref_key:"link",ref:s,class:S([_(a).e("inner"),_(a).is("link",!!d.to)]),role:"link",onClick:c},[ue(d.$slots,"default")],2),_(i)?(x(),Q(_(qe),{key:0,class:S(_(a).e("separator"))},{default:K(()=>[(x(),Q(pt(_(i))))]),_:1},8,["class"])):(x(),N("span",{key:1,class:S(_(a).e("separator")),role:"presentation"},ve(_(l)),3))],2))}}));var e0=_e(jM,[["__file","/home/runner/work/element-plus/element-plus/packages/components/breadcrumb/src/breadcrumb-item.vue"]]);const HM=rt(LM,{BreadcrumbItem:e0}),qM=Ft(e0),Rd=["default","primary","success","warning","info","danger","text",""],KM=["button","submit","reset"],Dd=Le({size:dc,disabled:Boolean,type:{type:String,values:Rd,default:""},icon:{type:an,default:""},nativeType:{type:String,values:KM,default:"button"},loading:Boolean,loadingIcon:{type:an,default:()=>hr},plain:Boolean,autofocus:Boolean,round:Boolean,circle:Boolean,color:String,dark:Boolean,autoInsertSpace:{type:Boolean,default:void 0}}),WM={click:e=>e instanceof MouseEvent};function rn(e,t){UM(e)&&(e="100%");var n=YM(e);return e=t===360?e:Math.min(t,Math.max(0,parseFloat(e))),n&&(e=parseInt(String(e*t),10)/100),Math.abs(e-t)<1e-6?1:(t===360?e=(e<0?e%t+t:e%t)/parseFloat(String(t)):e=e%t/parseFloat(String(t)),e)}function Si(e){return Math.min(1,Math.max(0,e))}function UM(e){return typeof e=="string"&&e.indexOf(".")!==-1&&parseFloat(e)===1}function YM(e){return typeof e=="string"&&e.indexOf("%")!==-1}function t0(e){return e=parseFloat(e),(isNaN(e)||e<0||e>1)&&(e=1),e}function $i(e){return e<=1?"".concat(Number(e)*100,"%"):e}function Ar(e){return e.length===1?"0"+e:String(e)}function GM(e,t,n){return{r:rn(e,255)*255,g:rn(t,255)*255,b:rn(n,255)*255}}function _m(e,t,n){e=rn(e,255),t=rn(t,255),n=rn(n,255);var o=Math.max(e,t,n),r=Math.min(e,t,n),a=0,l=0,i=(o+r)/2;if(o===r)l=0,a=0;else{var s=o-r;switch(l=i>.5?s/(2-o-r):s/(o+r),o){case e:a=(t-n)/s+(t1&&(n-=1),n<1/6?e+(t-e)*(6*n):n<1/2?t:n<2/3?e+(t-e)*(2/3-n)*6:e}function XM(e,t,n){var o,r,a;if(e=rn(e,360),t=rn(t,100),n=rn(n,100),t===0)r=n,a=n,o=n;else{var l=n<.5?n*(1+t):n+t-n*t,i=2*n-l;o=Rc(i,l,e+1/3),r=Rc(i,l,e),a=Rc(i,l,e-1/3)}return{r:o*255,g:r*255,b:a*255}}function wm(e,t,n){e=rn(e,255),t=rn(t,255),n=rn(n,255);var o=Math.max(e,t,n),r=Math.min(e,t,n),a=0,l=o,i=o-r,s=o===0?0:i/o;if(o===r)a=0;else{switch(o){case e:a=(t-n)/i+(t>16,g:(e&65280)>>8,b:e&255}}var Fd={aliceblue:"#f0f8ff",antiquewhite:"#faebd7",aqua:"#00ffff",aquamarine:"#7fffd4",azure:"#f0ffff",beige:"#f5f5dc",bisque:"#ffe4c4",black:"#000000",blanchedalmond:"#ffebcd",blue:"#0000ff",blueviolet:"#8a2be2",brown:"#a52a2a",burlywood:"#deb887",cadetblue:"#5f9ea0",chartreuse:"#7fff00",chocolate:"#d2691e",coral:"#ff7f50",cornflowerblue:"#6495ed",cornsilk:"#fff8dc",crimson:"#dc143c",cyan:"#00ffff",darkblue:"#00008b",darkcyan:"#008b8b",darkgoldenrod:"#b8860b",darkgray:"#a9a9a9",darkgreen:"#006400",darkgrey:"#a9a9a9",darkkhaki:"#bdb76b",darkmagenta:"#8b008b",darkolivegreen:"#556b2f",darkorange:"#ff8c00",darkorchid:"#9932cc",darkred:"#8b0000",darksalmon:"#e9967a",darkseagreen:"#8fbc8f",darkslateblue:"#483d8b",darkslategray:"#2f4f4f",darkslategrey:"#2f4f4f",darkturquoise:"#00ced1",darkviolet:"#9400d3",deeppink:"#ff1493",deepskyblue:"#00bfff",dimgray:"#696969",dimgrey:"#696969",dodgerblue:"#1e90ff",firebrick:"#b22222",floralwhite:"#fffaf0",forestgreen:"#228b22",fuchsia:"#ff00ff",gainsboro:"#dcdcdc",ghostwhite:"#f8f8ff",goldenrod:"#daa520",gold:"#ffd700",gray:"#808080",green:"#008000",greenyellow:"#adff2f",grey:"#808080",honeydew:"#f0fff0",hotpink:"#ff69b4",indianred:"#cd5c5c",indigo:"#4b0082",ivory:"#fffff0",khaki:"#f0e68c",lavenderblush:"#fff0f5",lavender:"#e6e6fa",lawngreen:"#7cfc00",lemonchiffon:"#fffacd",lightblue:"#add8e6",lightcoral:"#f08080",lightcyan:"#e0ffff",lightgoldenrodyellow:"#fafad2",lightgray:"#d3d3d3",lightgreen:"#90ee90",lightgrey:"#d3d3d3",lightpink:"#ffb6c1",lightsalmon:"#ffa07a",lightseagreen:"#20b2aa",lightskyblue:"#87cefa",lightslategray:"#778899",lightslategrey:"#778899",lightsteelblue:"#b0c4de",lightyellow:"#ffffe0",lime:"#00ff00",limegreen:"#32cd32",linen:"#faf0e6",magenta:"#ff00ff",maroon:"#800000",mediumaquamarine:"#66cdaa",mediumblue:"#0000cd",mediumorchid:"#ba55d3",mediumpurple:"#9370db",mediumseagreen:"#3cb371",mediumslateblue:"#7b68ee",mediumspringgreen:"#00fa9a",mediumturquoise:"#48d1cc",mediumvioletred:"#c71585",midnightblue:"#191970",mintcream:"#f5fffa",mistyrose:"#ffe4e1",moccasin:"#ffe4b5",navajowhite:"#ffdead",navy:"#000080",oldlace:"#fdf5e6",olive:"#808000",olivedrab:"#6b8e23",orange:"#ffa500",orangered:"#ff4500",orchid:"#da70d6",palegoldenrod:"#eee8aa",palegreen:"#98fb98",paleturquoise:"#afeeee",palevioletred:"#db7093",papayawhip:"#ffefd5",peachpuff:"#ffdab9",peru:"#cd853f",pink:"#ffc0cb",plum:"#dda0dd",powderblue:"#b0e0e6",purple:"#800080",rebeccapurple:"#663399",red:"#ff0000",rosybrown:"#bc8f8f",royalblue:"#4169e1",saddlebrown:"#8b4513",salmon:"#fa8072",sandybrown:"#f4a460",seagreen:"#2e8b57",seashell:"#fff5ee",sienna:"#a0522d",silver:"#c0c0c0",skyblue:"#87ceeb",slateblue:"#6a5acd",slategray:"#708090",slategrey:"#708090",snow:"#fffafa",springgreen:"#00ff7f",steelblue:"#4682b4",tan:"#d2b48c",teal:"#008080",thistle:"#d8bfd8",tomato:"#ff6347",turquoise:"#40e0d0",violet:"#ee82ee",wheat:"#f5deb3",white:"#ffffff",whitesmoke:"#f5f5f5",yellow:"#ffff00",yellowgreen:"#9acd32"};function tP(e){var t={r:0,g:0,b:0},n=1,o=null,r=null,a=null,l=!1,i=!1;return typeof e=="string"&&(e=rP(e)),typeof e=="object"&&(To(e.r)&&To(e.g)&&To(e.b)?(t=GM(e.r,e.g,e.b),l=!0,i=String(e.r).substr(-1)==="%"?"prgb":"rgb"):To(e.h)&&To(e.s)&&To(e.v)?(o=$i(e.s),r=$i(e.v),t=ZM(e.h,o,r),l=!0,i="hsv"):To(e.h)&&To(e.s)&&To(e.l)&&(o=$i(e.s),a=$i(e.l),t=XM(e.h,o,a),l=!0,i="hsl"),Object.prototype.hasOwnProperty.call(e,"a")&&(n=e.a)),n=t0(n),{ok:l,format:e.format||i,r:Math.min(255,Math.max(t.r,0)),g:Math.min(255,Math.max(t.g,0)),b:Math.min(255,Math.max(t.b,0)),a:n}}var nP="[-\\+]?\\d+%?",oP="[-\\+]?\\d*\\.\\d+%?",ar="(?:".concat(oP,")|(?:").concat(nP,")"),Dc="[\\s|\\(]+(".concat(ar,")[,|\\s]+(").concat(ar,")[,|\\s]+(").concat(ar,")\\s*\\)?"),Fc="[\\s|\\(]+(".concat(ar,")[,|\\s]+(").concat(ar,")[,|\\s]+(").concat(ar,")[,|\\s]+(").concat(ar,")\\s*\\)?"),Zn={CSS_UNIT:new RegExp(ar),rgb:new RegExp("rgb"+Dc),rgba:new RegExp("rgba"+Fc),hsl:new RegExp("hsl"+Dc),hsla:new RegExp("hsla"+Fc),hsv:new RegExp("hsv"+Dc),hsva:new RegExp("hsva"+Fc),hex3:/^#?([0-9a-fA-F]{1})([0-9a-fA-F]{1})([0-9a-fA-F]{1})$/,hex6:/^#?([0-9a-fA-F]{2})([0-9a-fA-F]{2})([0-9a-fA-F]{2})$/,hex4:/^#?([0-9a-fA-F]{1})([0-9a-fA-F]{1})([0-9a-fA-F]{1})([0-9a-fA-F]{1})$/,hex8:/^#?([0-9a-fA-F]{2})([0-9a-fA-F]{2})([0-9a-fA-F]{2})([0-9a-fA-F]{2})$/};function rP(e){if(e=e.trim().toLowerCase(),e.length===0)return!1;var t=!1;if(Fd[e])e=Fd[e],t=!0;else if(e==="transparent")return{r:0,g:0,b:0,a:0,format:"name"};var n=Zn.rgb.exec(e);return n?{r:n[1],g:n[2],b:n[3]}:(n=Zn.rgba.exec(e),n?{r:n[1],g:n[2],b:n[3],a:n[4]}:(n=Zn.hsl.exec(e),n?{h:n[1],s:n[2],l:n[3]}:(n=Zn.hsla.exec(e),n?{h:n[1],s:n[2],l:n[3],a:n[4]}:(n=Zn.hsv.exec(e),n?{h:n[1],s:n[2],v:n[3]}:(n=Zn.hsva.exec(e),n?{h:n[1],s:n[2],v:n[3],a:n[4]}:(n=Zn.hex8.exec(e),n?{r:_n(n[1]),g:_n(n[2]),b:_n(n[3]),a:km(n[4]),format:t?"name":"hex8"}:(n=Zn.hex6.exec(e),n?{r:_n(n[1]),g:_n(n[2]),b:_n(n[3]),format:t?"name":"hex"}:(n=Zn.hex4.exec(e),n?{r:_n(n[1]+n[1]),g:_n(n[2]+n[2]),b:_n(n[3]+n[3]),a:km(n[4]+n[4]),format:t?"name":"hex8"}:(n=Zn.hex3.exec(e),n?{r:_n(n[1]+n[1]),g:_n(n[2]+n[2]),b:_n(n[3]+n[3]),format:t?"name":"hex"}:!1)))))))))}function To(e){return Boolean(Zn.CSS_UNIT.exec(String(e)))}var n0=function(){function e(t,n){t===void 0&&(t=""),n===void 0&&(n={});var o;if(t instanceof e)return t;typeof t=="number"&&(t=eP(t)),this.originalInput=t;var r=tP(t);this.originalInput=t,this.r=r.r,this.g=r.g,this.b=r.b,this.a=r.a,this.roundA=Math.round(100*this.a)/100,this.format=(o=n.format)!==null&&o!==void 0?o:r.format,this.gradientType=n.gradientType,this.r<1&&(this.r=Math.round(this.r)),this.g<1&&(this.g=Math.round(this.g)),this.b<1&&(this.b=Math.round(this.b)),this.isValid=r.ok}return e.prototype.isDark=function(){return this.getBrightness()<128},e.prototype.isLight=function(){return!this.isDark()},e.prototype.getBrightness=function(){var t=this.toRgb();return(t.r*299+t.g*587+t.b*114)/1e3},e.prototype.getLuminance=function(){var t=this.toRgb(),n,o,r,a=t.r/255,l=t.g/255,i=t.b/255;return a<=.03928?n=a/12.92:n=Math.pow((a+.055)/1.055,2.4),l<=.03928?o=l/12.92:o=Math.pow((l+.055)/1.055,2.4),i<=.03928?r=i/12.92:r=Math.pow((i+.055)/1.055,2.4),.2126*n+.7152*o+.0722*r},e.prototype.getAlpha=function(){return this.a},e.prototype.setAlpha=function(t){return this.a=t0(t),this.roundA=Math.round(100*this.a)/100,this},e.prototype.toHsv=function(){var t=wm(this.r,this.g,this.b);return{h:t.h*360,s:t.s,v:t.v,a:this.a}},e.prototype.toHsvString=function(){var t=wm(this.r,this.g,this.b),n=Math.round(t.h*360),o=Math.round(t.s*100),r=Math.round(t.v*100);return this.a===1?"hsv(".concat(n,", ").concat(o,"%, ").concat(r,"%)"):"hsva(".concat(n,", ").concat(o,"%, ").concat(r,"%, ").concat(this.roundA,")")},e.prototype.toHsl=function(){var t=_m(this.r,this.g,this.b);return{h:t.h*360,s:t.s,l:t.l,a:this.a}},e.prototype.toHslString=function(){var t=_m(this.r,this.g,this.b),n=Math.round(t.h*360),o=Math.round(t.s*100),r=Math.round(t.l*100);return this.a===1?"hsl(".concat(n,", ").concat(o,"%, ").concat(r,"%)"):"hsla(".concat(n,", ").concat(o,"%, ").concat(r,"%, ").concat(this.roundA,")")},e.prototype.toHex=function(t){return t===void 0&&(t=!1),xm(this.r,this.g,this.b,t)},e.prototype.toHexString=function(t){return t===void 0&&(t=!1),"#"+this.toHex(t)},e.prototype.toHex8=function(t){return t===void 0&&(t=!1),JM(this.r,this.g,this.b,this.a,t)},e.prototype.toHex8String=function(t){return t===void 0&&(t=!1),"#"+this.toHex8(t)},e.prototype.toRgb=function(){return{r:Math.round(this.r),g:Math.round(this.g),b:Math.round(this.b),a:this.a}},e.prototype.toRgbString=function(){var t=Math.round(this.r),n=Math.round(this.g),o=Math.round(this.b);return this.a===1?"rgb(".concat(t,", ").concat(n,", ").concat(o,")"):"rgba(".concat(t,", ").concat(n,", ").concat(o,", ").concat(this.roundA,")")},e.prototype.toPercentageRgb=function(){var t=function(n){return"".concat(Math.round(rn(n,255)*100),"%")};return{r:t(this.r),g:t(this.g),b:t(this.b),a:this.a}},e.prototype.toPercentageRgbString=function(){var t=function(n){return Math.round(rn(n,255)*100)};return this.a===1?"rgb(".concat(t(this.r),"%, ").concat(t(this.g),"%, ").concat(t(this.b),"%)"):"rgba(".concat(t(this.r),"%, ").concat(t(this.g),"%, ").concat(t(this.b),"%, ").concat(this.roundA,")")},e.prototype.toName=function(){if(this.a===0)return"transparent";if(this.a<1)return!1;for(var t="#"+xm(this.r,this.g,this.b,!1),n=0,o=Object.entries(Fd);n=0,a=!n&&r&&(t.startsWith("hex")||t==="name");return a?t==="name"&&this.a===0?this.toName():this.toRgbString():(t==="rgb"&&(o=this.toRgbString()),t==="prgb"&&(o=this.toPercentageRgbString()),(t==="hex"||t==="hex6")&&(o=this.toHexString()),t==="hex3"&&(o=this.toHexString(!0)),t==="hex4"&&(o=this.toHex8String(!0)),t==="hex8"&&(o=this.toHex8String()),t==="name"&&(o=this.toName()),t==="hsl"&&(o=this.toHslString()),t==="hsv"&&(o=this.toHsvString()),o||this.toHexString())},e.prototype.toNumber=function(){return(Math.round(this.r)<<16)+(Math.round(this.g)<<8)+Math.round(this.b)},e.prototype.clone=function(){return new e(this.toString())},e.prototype.lighten=function(t){t===void 0&&(t=10);var n=this.toHsl();return n.l+=t/100,n.l=Si(n.l),new e(n)},e.prototype.brighten=function(t){t===void 0&&(t=10);var n=this.toRgb();return n.r=Math.max(0,Math.min(255,n.r-Math.round(255*-(t/100)))),n.g=Math.max(0,Math.min(255,n.g-Math.round(255*-(t/100)))),n.b=Math.max(0,Math.min(255,n.b-Math.round(255*-(t/100)))),new e(n)},e.prototype.darken=function(t){t===void 0&&(t=10);var n=this.toHsl();return n.l-=t/100,n.l=Si(n.l),new e(n)},e.prototype.tint=function(t){return t===void 0&&(t=10),this.mix("white",t)},e.prototype.shade=function(t){return t===void 0&&(t=10),this.mix("black",t)},e.prototype.desaturate=function(t){t===void 0&&(t=10);var n=this.toHsl();return n.s-=t/100,n.s=Si(n.s),new e(n)},e.prototype.saturate=function(t){t===void 0&&(t=10);var n=this.toHsl();return n.s+=t/100,n.s=Si(n.s),new e(n)},e.prototype.greyscale=function(){return this.desaturate(100)},e.prototype.spin=function(t){var n=this.toHsl(),o=(n.h+t)%360;return n.h=o<0?360+o:o,new e(n)},e.prototype.mix=function(t,n){n===void 0&&(n=50);var o=this.toRgb(),r=new e(t).toRgb(),a=n/100,l={r:(r.r-o.r)*a+o.r,g:(r.g-o.g)*a+o.g,b:(r.b-o.b)*a+o.b,a:(r.a-o.a)*a+o.a};return new e(l)},e.prototype.analogous=function(t,n){t===void 0&&(t=6),n===void 0&&(n=30);var o=this.toHsl(),r=360/n,a=[this];for(o.h=(o.h-(r*t>>1)+720)%360;--t;)o.h=(o.h+r)%360,a.push(new e(o));return a},e.prototype.complement=function(){var t=this.toHsl();return t.h=(t.h+180)%360,new e(t)},e.prototype.monochromatic=function(t){t===void 0&&(t=6);for(var n=this.toHsv(),o=n.h,r=n.s,a=n.v,l=[],i=1/t;t--;)l.push(new e({h:o,s:r,v:a})),a=(a+i)%1;return l},e.prototype.splitcomplement=function(){var t=this.toHsl(),n=t.h;return[this,new e({h:(n+72)%360,s:t.s,l:t.l}),new e({h:(n+216)%360,s:t.s,l:t.l})]},e.prototype.onBackground=function(t){var n=this.toRgb(),o=new e(t).toRgb();return new e({r:o.r+(n.r-o.r)*n.a,g:o.g+(n.g-o.g)*n.a,b:o.b+(n.b-o.b)*n.a})},e.prototype.triad=function(){return this.polyad(3)},e.prototype.tetrad=function(){return this.polyad(4)},e.prototype.polyad=function(t){for(var n=this.toHsl(),o=n.h,r=[this],a=360/t,l=1;l{let n={};const o=e.color;if(o){const r=new n0(o),a=e.dark?r.tint(20).toString():Xo(r,20);if(e.plain)n={"--el-button-bg-color":e.dark?Xo(r,90):r.tint(90).toString(),"--el-button-text-color":o,"--el-button-border-color":e.dark?Xo(r,50):r.tint(50).toString(),"--el-button-hover-text-color":"var(--el-color-white)","--el-button-hover-bg-color":o,"--el-button-hover-border-color":o,"--el-button-active-bg-color":a,"--el-button-active-text-color":"var(--el-color-white)","--el-button-active-border-color":a},t.value&&(n["--el-button-disabled-bg-color"]=e.dark?Xo(r,90):r.tint(90).toString(),n["--el-button-disabled-text-color"]=e.dark?Xo(r,50):r.tint(50).toString(),n["--el-button-disabled-border-color"]=e.dark?Xo(r,80):r.tint(80).toString());else{const l=e.dark?Xo(r,30):r.tint(30).toString(),i=r.isDark()?"var(--el-color-white)":"var(--el-color-black)";if(n={"--el-button-bg-color":o,"--el-button-text-color":i,"--el-button-border-color":o,"--el-button-hover-bg-color":l,"--el-button-hover-text-color":i,"--el-button-hover-border-color":l,"--el-button-active-bg-color":a,"--el-button-active-border-color":a},t.value){const s=e.dark?Xo(r,50):r.tint(50).toString();n["--el-button-disabled-bg-color"]=s,n["--el-button-disabled-text-color"]=e.dark?"rgba(255, 255, 255, 0.5)":"var(--el-color-white)",n["--el-button-disabled-border-color"]=s}}}return n})}const lP=["disabled","autofocus","type"],iP={name:"ElButton"},sP=ee(ze(he({},iP),{props:Dd,emits:WM,setup(e,{expose:t,emit:n}){const o=e,r=ni(),a=Ne(cy,void 0),l=qa("button"),i=ke("button"),{form:s}=Ka(),c=Ut(C(()=>a==null?void 0:a.size)),d=Zr(),u=E(),p=C(()=>o.type||(a==null?void 0:a.type)||""),f=C(()=>{var g,v,y;return(y=(v=o.autoInsertSpace)!=null?v:(g=l.value)==null?void 0:g.autoInsertSpace)!=null?y:!1}),h=C(()=>{var g;const v=(g=r.default)==null?void 0:g.call(r);if(f.value&&(v==null?void 0:v.length)===1){const y=v[0];if((y==null?void 0:y.type)===ti){const T=y.children;return/^\p{Unified_Ideograph}{2}$/u.test(T.trim())}}return!1}),b=aP(o),m=g=>{o.nativeType==="reset"&&(s==null||s.resetFields()),n("click",g)};return t({ref:u,size:c,type:p,disabled:d,shouldAddSpace:h}),(g,v)=>(x(),N("button",{ref_key:"_ref",ref:u,class:S([_(i).b(),_(i).m(_(p)),_(i).m(_(c)),_(i).is("disabled",_(d)),_(i).is("loading",g.loading),_(i).is("plain",g.plain),_(i).is("round",g.round),_(i).is("circle",g.circle)]),disabled:_(d)||g.loading,autofocus:g.autofocus,type:g.nativeType,style:Re(_(b)),onClick:m},[g.loading?(x(),N(De,{key:0},[g.$slots.loading?ue(g.$slots,"loading",{key:0}):(x(),Q(_(qe),{key:1,class:S(_(i).is("loading"))},{default:K(()=>[(x(),Q(pt(g.loadingIcon)))]),_:1},8,["class"]))],2112)):g.icon||g.$slots.icon?(x(),Q(_(qe),{key:1},{default:K(()=>[g.icon?(x(),Q(pt(g.icon),{key:0})):ue(g.$slots,"icon",{key:1})]),_:3})):G("v-if",!0),g.$slots.default?(x(),N("span",{key:2,class:S({[_(i).em("text","expand")]:_(h)})},[ue(g.$slots,"default")],2)):G("v-if",!0)],14,lP))}}));var cP=_e(sP,[["__file","/home/runner/work/element-plus/element-plus/packages/components/button/src/button.vue"]]);const dP={size:Dd.size,type:Dd.type},uP={name:"ElButtonGroup"},pP=ee(ze(he({},uP),{props:dP,setup(e){const t=e;ot(cy,vt({size:Yt(t,"size"),type:Yt(t,"type")}));const n=ke("button");return(o,r)=>(x(),N("div",{class:S(`${_(n).b("group")}`)},[ue(o.$slots,"default")],2))}}));var o0=_e(pP,[["__file","/home/runner/work/element-plus/element-plus/packages/components/button/src/button-group.vue"]]);const Vn=rt(cP,{ButtonGroup:o0}),r0=Ft(o0);var Ko=typeof globalThis!="undefined"?globalThis:typeof window!="undefined"?window:typeof global!="undefined"?global:typeof self!="undefined"?self:{},a0={exports:{}};(function(e,t){(function(n,o){e.exports=o()})(Ko,function(){var n=1e3,o=6e4,r=36e5,a="millisecond",l="second",i="minute",s="hour",c="day",d="week",u="month",p="quarter",f="year",h="date",b="Invalid Date",m=/^(\d{4})[-/]?(\d{1,2})?[-/]?(\d{0,2})[Tt\s]*(\d{1,2})?:?(\d{1,2})?:?(\d{1,2})?[.:]?(\d+)?$/,g=/\[([^\]]+)]|Y{1,4}|M{1,4}|D{1,2}|d{1,4}|H{1,2}|h{1,2}|a|A|m{1,2}|s{1,2}|Z{1,2}|SSS/g,v={name:"en",weekdays:"Sunday_Monday_Tuesday_Wednesday_Thursday_Friday_Saturday".split("_"),months:"January_February_March_April_May_June_July_August_September_October_November_December".split("_")},y=function(D,V,q){var P=String(D);return!P||P.length>=V?D:""+Array(V+1-P.length).join(q)+D},T={s:y,z:function(D){var V=-D.utcOffset(),q=Math.abs(V),P=Math.floor(q/60),A=q%60;return(V<=0?"+":"-")+y(P,2,"0")+":"+y(A,2,"0")},m:function D(V,q){if(V.date()1)return D(W[0])}else{var Y=V.name;k[Y]=V,A=Y}return!P&&A&&(w=A),A||!P&&w},O=function(D,V){if($(D))return D.clone();var q=typeof V=="object"?V:{};return q.date=D,q.args=arguments,new F(q)},R=T;R.l=z,R.i=$,R.w=function(D,V){return O(D,{locale:V.$L,utc:V.$u,x:V.$x,$offset:V.$offset})};var F=function(){function D(q){this.$L=z(q.locale,null,!0),this.parse(q)}var V=D.prototype;return V.parse=function(q){this.$d=function(P){var A=P.date,I=P.utc;if(A===null)return new Date(NaN);if(R.u(A))return new Date;if(A instanceof Date)return new Date(A);if(typeof A=="string"&&!/Z$/i.test(A)){var W=A.match(m);if(W){var Y=W[2]-1||0,J=(W[7]||"0").substring(0,3);return I?new Date(Date.UTC(W[1],Y,W[3]||1,W[4]||0,W[5]||0,W[6]||0,J)):new Date(W[1],Y,W[3]||1,W[4]||0,W[5]||0,W[6]||0,J)}}return new Date(A)}(q),this.$x=q.x||{},this.init()},V.init=function(){var q=this.$d;this.$y=q.getFullYear(),this.$M=q.getMonth(),this.$D=q.getDate(),this.$W=q.getDay(),this.$H=q.getHours(),this.$m=q.getMinutes(),this.$s=q.getSeconds(),this.$ms=q.getMilliseconds()},V.$utils=function(){return R},V.isValid=function(){return this.$d.toString()!==b},V.isSame=function(q,P){var A=O(q);return this.startOf(P)<=A&&A<=this.endOf(P)},V.isAfter=function(q,P){return O(q)68?1900:2e3)},c=function(b){return function(m){this[b]=+m}},d=[/[+-]\d\d:?(\d\d)?|Z/,function(b){(this.zone||(this.zone={})).offset=function(m){if(!m||m==="Z")return 0;var g=m.match(/([+-]|\d\d)/g),v=60*g[1]+(+g[2]||0);return v===0?0:g[0]==="+"?-v:v}(b)}],u=function(b){var m=i[b];return m&&(m.indexOf?m:m.s.concat(m.f))},p=function(b,m){var g,v=i.meridiem;if(v){for(var y=1;y<=24;y+=1)if(b.indexOf(v(y,0,m))>-1){g=y>12;break}}else g=b===(m?"pm":"PM");return g},f={A:[l,function(b){this.afternoon=p(b,!1)}],a:[l,function(b){this.afternoon=p(b,!0)}],S:[/\d/,function(b){this.milliseconds=100*+b}],SS:[r,function(b){this.milliseconds=10*+b}],SSS:[/\d{3}/,function(b){this.milliseconds=+b}],s:[a,c("seconds")],ss:[a,c("seconds")],m:[a,c("minutes")],mm:[a,c("minutes")],H:[a,c("hours")],h:[a,c("hours")],HH:[a,c("hours")],hh:[a,c("hours")],D:[a,c("day")],DD:[r,c("day")],Do:[l,function(b){var m=i.ordinal,g=b.match(/\d+/);if(this.day=g[0],m)for(var v=1;v<=31;v+=1)m(v).replace(/\[|\]/g,"")===b&&(this.day=v)}],M:[a,c("month")],MM:[r,c("month")],MMM:[l,function(b){var m=u("months"),g=(u("monthsShort")||m.map(function(v){return v.slice(0,3)})).indexOf(b)+1;if(g<1)throw new Error;this.month=g%12||g}],MMMM:[l,function(b){var m=u("months").indexOf(b)+1;if(m<1)throw new Error;this.month=m%12||m}],Y:[/[+-]?\d+/,c("year")],YY:[r,function(b){this.year=s(b)}],YYYY:[/\d{4}/,c("year")],Z:d,ZZ:d};function h(b){var m,g;m=b,g=i&&i.formats;for(var v=(b=m.replace(/(\[[^\]]+])|(LTS?|l{1,4}|L{1,4})/g,function(O,R,F){var L=F&&F.toUpperCase();return R||g[F]||n[F]||g[L].replace(/(\[[^\]]+])|(MMMM|MM|DD|dddd)/g,function(D,V,q){return V||q.slice(1)})})).match(o),y=v.length,T=0;T-1)return new Date((A==="X"?1e3:1)*P);var W=h(A)(P),Y=W.year,J=W.month,Z=W.day,se=W.hours,Se=W.minutes,oe=W.seconds,H=W.milliseconds,ne=W.zone,le=new Date,be=Z||(Y||J?1:le.getDate()),$e=Y||le.getFullYear(),Ie=0;Y&&!J||(Ie=J>0?J-1:le.getMonth());var Me=se||0,j=Se||0,X=oe||0,de=H||0;return ne?new Date(Date.UTC($e,Ie,be,Me,j,X,de+60*ne.offset*1e3)):I?new Date(Date.UTC($e,Ie,be,Me,j,X,de)):new Date($e,Ie,be,Me,j,X,de)}catch{return new Date("")}}(w,z,k),this.init(),L&&L!==!0&&(this.$L=this.locale(L).$L),F&&w!=this.format(z)&&(this.$d=new Date("")),i={}}else if(z instanceof Array)for(var D=z.length,V=1;V<=D;V+=1){$[1]=z[V-1];var q=g.apply(this,$);if(q.isValid()){this.$d=q.$d,this.$L=q.$L,this.init();break}V===D&&(this.$d=new Date(""))}else y.call(this,T)}}})})(s0);var Cp=s0.exports;const Ld="HH:mm:ss",ll="YYYY-MM-DD",fP={date:ll,week:"gggg[w]ww",year:"YYYY",month:"YYYY-MM",datetime:`${ll} ${Ld}`,monthrange:"YYYY-MM",daterange:ll,datetimerange:`${ll} ${Ld}`},Sp={id:{type:[Array,String]},name:{type:[Array,String],default:""},popperClass:{type:String,default:""},format:{type:String},valueFormat:{type:String},type:{type:String,default:""},clearable:{type:Boolean,default:!0},clearIcon:{type:[String,Object],default:Ro},editable:{type:Boolean,default:!0},prefixIcon:{type:[String,Object],default:""},size:{type:String,validator:In},readonly:{type:Boolean,default:!1},disabled:{type:Boolean,default:!1},placeholder:{type:String,default:""},popperOptions:{type:Object,default:()=>({})},modelValue:{type:[Date,Array,String,Number],default:""},rangeSeparator:{type:String,default:"-"},startPlaceholder:String,endPlaceholder:String,defaultValue:{type:[Date,Array]},defaultTime:{type:[Date,Array]},isRange:{type:Boolean,default:!1},disabledHours:{type:Function},disabledMinutes:{type:Function},disabledSeconds:{type:Function},disabledDate:{type:Function},cellClassName:{type:Function},shortcuts:{type:Array,default:()=>[]},arrowControl:{type:Boolean,default:!1},validateEvent:{type:Boolean,default:!0},unlinkPanels:Boolean},Tm=function(e,t){const n=e instanceof Date,o=t instanceof Date;return n&&o?e.getTime()===t.getTime():!n&&!o?e===t:!1},Cm=function(e,t){const n=Array.isArray(e),o=Array.isArray(t);return n&&o?e.length!==t.length?!1:e.every((r,a)=>Tm(r,t[a])):!n&&!o?Tm(e,t):!1},Sm=function(e,t,n){const o=Bl(t)||t==="x"?Ge(e).locale(n):Ge(e,t).locale(n);return o.isValid()?o:void 0},$m=function(e,t,n){return Bl(t)?e:t==="x"?+e:Ge(e).locale(n).format(t)},hP=ee({name:"Picker",components:{ElInput:Gn,ElTooltip:vn,ElIcon:qe},props:Sp,emits:["update:modelValue","change","focus","blur","calendar-change","panel-change","visible-change"],setup(e,t){const{lang:n}=Tt(),o=ke("date"),r=ke("input"),a=ke("range"),l=Ne(Mn,{}),i=Ne(qn,{}),s=Ne("ElPopperOptions",{}),c=E(),d=E(),u=E(!1),p=E(!1),f=E(null);ge(u,B=>{var me;B?f.value=e.modelValue:(le.value=null,je(()=>{h(e.modelValue)}),t.emit("blur"),$e(),e.validateEvent&&((me=i.validate)==null||me.call(i,"blur").catch(Be=>void 0)))});const h=(B,me)=>{var Be;(me||!Cm(B,f.value))&&(t.emit("change",B),e.validateEvent&&((Be=i.validate)==null||Be.call(i,"change").catch(Ze=>void 0)))},b=B=>{if(!Cm(e.modelValue,B)){let me;Array.isArray(B)?me=B.map(Be=>$m(Be,e.valueFormat,n.value)):B&&(me=$m(B,e.valueFormat,n.value)),t.emit("update:modelValue",B&&me,n.value)}},m=C(()=>{if(d.value){const B=se.value?d.value:d.value.$el;return Array.from(B.querySelectorAll("input"))}return[]}),g=C(()=>m==null?void 0:m.value[0]),v=C(()=>m==null?void 0:m.value[1]),y=(B,me,Be)=>{const Ze=m.value;!Ze.length||(!Be||Be==="min"?(Ze[0].setSelectionRange(B,me),Ze[0].focus()):Be==="max"&&(Ze[1].setSelectionRange(B,me),Ze[1].focus()))},T=(B="",me=!1)=>{u.value=me;let Be;Array.isArray(B)?Be=B.map(Ze=>Ze.toDate()):Be=B&&B.toDate(),le.value=null,b(Be)},w=()=>{p.value=!0},k=()=>{t.emit("visible-change",!0)},$=()=>{p.value=!1,t.emit("visible-change",!1)},z=(B=!0)=>{let me=g.value;!B&&se.value&&(me=v.value),me&&me.focus()},O=B=>{e.readonly||F.value||u.value||(u.value=!0,t.emit("focus",B))},R=()=>{var B;(B=c.value)==null||B.onClose(),$e()},F=C(()=>e.disabled||l.disabled),L=C(()=>{let B;if(Y.value?ae.value.getDefaultValue&&(B=ae.value.getDefaultValue()):Array.isArray(e.modelValue)?B=e.modelValue.map(me=>Sm(me,e.valueFormat,n.value)):B=Sm(e.modelValue,e.valueFormat,n.value),ae.value.getRangeAvailableTime){const me=ae.value.getRangeAvailableTime(B);An(me,B)||(B=me,b(Array.isArray(B)?B.map(Be=>Be.toDate()):B.toDate()))}return Array.isArray(B)&&B.some(me=>!me)&&(B=[]),B}),D=C(()=>{if(!ae.value.panelReady)return;const B=Me(L.value);if(Array.isArray(le.value))return[le.value[0]||B&&B[0]||"",le.value[1]||B&&B[1]||""];if(le.value!==null)return le.value;if(!(!q.value&&Y.value)&&!(!u.value&&Y.value))return B?P.value?B.join(", "):B:""}),V=C(()=>e.type.includes("time")),q=C(()=>e.type.startsWith("time")),P=C(()=>e.type==="dates"),A=C(()=>e.prefixIcon||(V.value?Zv:eE)),I=E(!1),W=B=>{e.readonly||F.value||I.value&&(B.stopPropagation(),b(null),h(null,!0),I.value=!1,u.value=!1,ae.value.handleClear&&ae.value.handleClear())},Y=C(()=>!e.modelValue||Array.isArray(e.modelValue)&&!e.modelValue.length),J=()=>{e.readonly||F.value||!Y.value&&e.clearable&&(I.value=!0)},Z=()=>{I.value=!1},se=C(()=>e.type.includes("range")),Se=Ut(),oe=C(()=>{var B,me;return(me=(B=c.value)==null?void 0:B.popperRef)==null?void 0:me.contentRef}),H=C(()=>{var B,me;return(me=(B=_(c))==null?void 0:B.popperRef)==null?void 0:me.contentRef}),ne=C(()=>{var B;return _(se)?_(d):(B=_(d))==null?void 0:B.$el});Cs(ne,B=>{const me=_(H),Be=_(ne);me&&(B.target===me||B.composedPath().includes(me))||B.target===Be||B.composedPath().includes(Be)||(u.value=!1)});const le=E(null),be=()=>{if(le.value){const B=Ie(D.value);B&&j(B)&&(b(Array.isArray(B)?B.map(me=>me.toDate()):B.toDate()),le.value=null)}le.value===""&&(b(null),h(null),le.value=null)},$e=()=>{m.value.forEach(B=>B.blur())},Ie=B=>B?ae.value.parseUserInput(B):null,Me=B=>B?ae.value.formatToString(B):null,j=B=>ae.value.isValidValue(B),X=B=>{const me=B.code;if(me===Oe.esc){u.value=!1,B.stopPropagation();return}if(me===Oe.tab){se.value?setTimeout(()=>{m.value.includes(document.activeElement)||(u.value=!1,$e())},0):(be(),u.value=!1,B.stopPropagation());return}if(me===Oe.enter||me===Oe.numpadEnter){(le.value===null||le.value===""||j(Ie(D.value)))&&(be(),u.value=!1),B.stopPropagation();return}if(le.value){B.stopPropagation();return}ae.value.handleKeydown&&ae.value.handleKeydown(B)},de=B=>{le.value=B},xe=B=>{le.value?le.value=[B.target.value,le.value[1]]:le.value=[B.target.value,null]},we=B=>{le.value?le.value=[le.value[0],B.target.value]:le.value=[null,B.target.value]},Ee=()=>{const B=Ie(le.value&&le.value[0]);if(B&&B.isValid()){le.value=[Me(B),D.value[1]];const me=[B,L.value&&L.value[1]];j(me)&&(b(me),le.value=null)}},ce=()=>{const B=Ie(le.value&&le.value[1]);if(B&&B.isValid()){le.value=[D.value[0],Me(B)];const me=[L.value&&L.value[0],B];j(me)&&(b(me),le.value=null)}},ae=E({}),te=B=>{ae.value[B[0]]=B[1],ae.value.panelReady=!0},pe=B=>{t.emit("calendar-change",B)},Fe=(B,me,Be)=>{t.emit("panel-change",B,me,Be)};return ot("EP_PICKER_BASE",{props:e}),{nsDate:o,nsInput:r,nsRange:a,elPopperOptions:s,isDatesPicker:P,handleEndChange:ce,handleStartChange:Ee,handleStartInput:xe,handleEndInput:we,onUserInput:de,handleChange:be,handleKeydown:X,popperPaneRef:oe,onClickOutside:Cs,pickerSize:Se,isRangeInput:se,onMouseLeave:Z,onMouseEnter:J,onClearIconClick:W,showClose:I,triggerIcon:A,onPick:T,handleFocus:O,handleBlur:R,pickerVisible:u,pickerActualVisible:p,displayValue:D,parsedValue:L,setSelectionRange:y,refPopper:c,inputRef:d,pickerDisabled:F,onSetPickerOption:te,onCalendarChange:pe,onPanelChange:Fe,focus:z,onShow:k,onBeforeShow:w,onHide:$}}}),mP=["id","name","placeholder","value","disabled","readonly"],gP=["id","name","placeholder","value","disabled","readonly"];function bP(e,t,n,o,r,a){const l=ie("el-icon"),i=ie("el-input"),s=ie("el-tooltip");return x(),Q(s,St({ref:"refPopper",visible:e.pickerVisible,"onUpdate:visible":t[17]||(t[17]=c=>e.pickerVisible=c),effect:"light",pure:"",trigger:"click"},e.$attrs,{"append-to-body":"",transition:`${e.nsDate.namespace.value}-zoom-in-top`,"popper-class":[`${e.nsDate.namespace.value}-picker__popper`,e.popperClass],"popper-options":e.elPopperOptions,"fallback-placements":["bottom","top","right","left"],"gpu-acceleration":!1,"stop-popper-mouse-event":!1,"hide-after":0,persistent:"",onBeforeShow:e.onBeforeShow,onShow:e.onShow,onHide:e.onHide}),{default:K(()=>[e.isRangeInput?(x(),N("div",{key:1,ref:"inputRef",class:S([e.nsDate.b("editor"),e.nsDate.bm("editor",e.type),e.nsInput.e("inner"),e.nsDate.is("disabled",e.pickerDisabled),e.nsDate.is("active",e.pickerVisible),e.nsRange.b("editor"),e.pickerSize?e.nsRange.bm("editor",e.pickerSize):"",e.$attrs.class]),style:Re(e.$attrs.style),onClick:t[7]||(t[7]=(...c)=>e.handleFocus&&e.handleFocus(...c)),onMouseenter:t[8]||(t[8]=(...c)=>e.onMouseEnter&&e.onMouseEnter(...c)),onMouseleave:t[9]||(t[9]=(...c)=>e.onMouseLeave&&e.onMouseLeave(...c)),onKeydown:t[10]||(t[10]=(...c)=>e.handleKeydown&&e.handleKeydown(...c))},[e.triggerIcon?(x(),Q(l,{key:0,class:S([e.nsInput.e("icon"),e.nsRange.e("icon")]),onClick:e.handleFocus},{default:K(()=>[(x(),Q(pt(e.triggerIcon)))]),_:1},8,["class","onClick"])):G("v-if",!0),M("input",{id:e.id&&e.id[0],autocomplete:"off",name:e.name&&e.name[0],placeholder:e.startPlaceholder,value:e.displayValue&&e.displayValue[0],disabled:e.pickerDisabled,readonly:!e.editable||e.readonly,class:S(e.nsRange.b("input")),onInput:t[1]||(t[1]=(...c)=>e.handleStartInput&&e.handleStartInput(...c)),onChange:t[2]||(t[2]=(...c)=>e.handleStartChange&&e.handleStartChange(...c)),onFocus:t[3]||(t[3]=(...c)=>e.handleFocus&&e.handleFocus(...c))},null,42,mP),ue(e.$slots,"range-separator",{},()=>[M("span",{class:S(e.nsRange.b("separator"))},ve(e.rangeSeparator),3)]),M("input",{id:e.id&&e.id[1],autocomplete:"off",name:e.name&&e.name[1],placeholder:e.endPlaceholder,value:e.displayValue&&e.displayValue[1],disabled:e.pickerDisabled,readonly:!e.editable||e.readonly,class:S(e.nsRange.b("input")),onFocus:t[4]||(t[4]=(...c)=>e.handleFocus&&e.handleFocus(...c)),onInput:t[5]||(t[5]=(...c)=>e.handleEndInput&&e.handleEndInput(...c)),onChange:t[6]||(t[6]=(...c)=>e.handleEndChange&&e.handleEndChange(...c))},null,42,gP),e.clearIcon?(x(),Q(l,{key:1,class:S([e.nsInput.e("icon"),e.nsRange.e("close-icon"),{[e.nsRange.e("close-icon--hidden")]:!e.showClose}]),onClick:e.onClearIconClick},{default:K(()=>[(x(),Q(pt(e.clearIcon)))]),_:1},8,["class","onClick"])):G("v-if",!0)],38)):(x(),Q(i,{key:0,id:e.id,ref:"inputRef","model-value":e.displayValue,name:e.name,size:e.pickerSize,disabled:e.pickerDisabled,placeholder:e.placeholder,class:S([e.nsDate.b("editor"),e.nsDate.bm("editor",e.type),e.$attrs.class]),style:Re(e.$attrs.style),readonly:!e.editable||e.readonly||e.isDatesPicker||e.type==="week",onInput:e.onUserInput,onFocus:e.handleFocus,onKeydown:e.handleKeydown,onChange:e.handleChange,onMouseenter:e.onMouseEnter,onMouseleave:e.onMouseLeave,onClick:t[0]||(t[0]=He(()=>{},["stop"]))},{prefix:K(()=>[e.triggerIcon?(x(),Q(l,{key:0,class:S(e.nsInput.e("icon")),onClick:e.handleFocus},{default:K(()=>[(x(),Q(pt(e.triggerIcon)))]),_:1},8,["class","onClick"])):G("v-if",!0)]),suffix:K(()=>[e.showClose&&e.clearIcon?(x(),Q(l,{key:0,class:S(`${e.nsInput.e("icon")} clear-icon`),onClick:e.onClearIconClick},{default:K(()=>[(x(),Q(pt(e.clearIcon)))]),_:1},8,["class","onClick"])):G("v-if",!0)]),_:1},8,["id","model-value","name","size","disabled","placeholder","class","style","readonly","onInput","onFocus","onKeydown","onChange","onMouseenter","onMouseleave"]))]),content:K(()=>[ue(e.$slots,"default",{visible:e.pickerVisible,actualVisible:e.pickerActualVisible,parsedValue:e.parsedValue,format:e.format,unlinkPanels:e.unlinkPanels,type:e.type,defaultValue:e.defaultValue,onPick:t[11]||(t[11]=(...c)=>e.onPick&&e.onPick(...c)),onSelectRange:t[12]||(t[12]=(...c)=>e.setSelectionRange&&e.setSelectionRange(...c)),onSetPickerOption:t[13]||(t[13]=(...c)=>e.onSetPickerOption&&e.onSetPickerOption(...c)),onCalendarChange:t[14]||(t[14]=(...c)=>e.onCalendarChange&&e.onCalendarChange(...c)),onPanelChange:t[15]||(t[15]=(...c)=>e.onPanelChange&&e.onPanelChange(...c)),onMousedown:t[16]||(t[16]=He(()=>{},["stop"]))})]),_:3},16,["visible","transition","popper-class","popper-options","onBeforeShow","onShow","onHide"])}var c0=_e(hP,[["render",bP],["__file","/home/runner/work/element-plus/element-plus/packages/components/time-picker/src/common/picker.vue"]]);const Qo=new Map;let Em;dt&&(document.addEventListener("mousedown",e=>Em=e),document.addEventListener("mouseup",e=>{for(const t of Qo.values())for(const{documentHandler:n}of t)n(e,Em)}));function Am(e,t){let n=[];return Array.isArray(t.arg)?n=t.arg:Hr(t.arg)&&n.push(t.arg),function(o,r){const a=t.instance.popperRef,l=o.target,i=r==null?void 0:r.target,s=!t||!t.instance,c=!l||!i,d=e.contains(l)||e.contains(i),u=e===l,p=n.length&&n.some(h=>h==null?void 0:h.contains(l))||n.length&&n.includes(i),f=a&&(a.contains(l)||a.contains(i));s||c||d||u||p||f||t.value(o,r)}}const Jr={beforeMount(e,t){Qo.has(e)||Qo.set(e,[]),Qo.get(e).push({documentHandler:Am(e,t),bindingFn:t.value})},updated(e,t){Qo.has(e)||Qo.set(e,[]);const n=Qo.get(e),o=n.findIndex(a=>a.bindingFn===t.oldValue),r={documentHandler:Am(e,t),bindingFn:t.value};o>=0?n.splice(o,1,r):n.push(r)},unmounted(e){Qo.delete(e)}};var d0={beforeMount(e,t){let n=null,o;const r=()=>t.value&&t.value(),a=()=>{Date.now()-o<100&&r(),clearInterval(n),n=null};Et(e,"mousedown",l=>{l.button===0&&(o=Date.now(),U$(document,"mouseup",a),clearInterval(n),n=setInterval(r,100))})}};const Vd="_trap-focus-children",zr=[],zm=e=>{if(zr.length===0)return;const t=zr[zr.length-1][Vd];if(t.length>0&&e.code===Oe.tab){if(t.length===1){e.preventDefault(),document.activeElement!==t[0]&&t[0].focus();return}const n=e.shiftKey,o=e.target===t[0],r=e.target===t[t.length-1];o&&n&&(e.preventDefault(),t[t.length-1].focus()),r&&!n&&(e.preventDefault(),t[0].focus())}},u0={beforeMount(e){e[Vd]=Lh(e),zr.push(e),zr.length<=1&&Et(document,"keydown",zm)},updated(e){je(()=>{e[Vd]=Lh(e)})},unmounted(){zr.shift(),zr.length===0&&Bt(document,"keydown",zm)}};var Nm=!1,$r,Bd,jd,Hi,qi,p0,Ki,Hd,qd,Kd,f0,Wd,Ud,h0,m0;function pn(){if(!Nm){Nm=!0;var e=navigator.userAgent,t=/(?:MSIE.(\d+\.\d+))|(?:(?:Firefox|GranParadiso|Iceweasel).(\d+\.\d+))|(?:Opera(?:.+Version.|.)(\d+\.\d+))|(?:AppleWebKit.(\d+(?:\.\d+)?))|(?:Trident\/\d+\.\d+.*rv:(\d+\.\d+))/.exec(e),n=/(Mac OS X)|(Windows)|(Linux)/.exec(e);if(Wd=/\b(iPhone|iP[ao]d)/.exec(e),Ud=/\b(iP[ao]d)/.exec(e),Kd=/Android/i.exec(e),h0=/FBAN\/\w+;/i.exec(e),m0=/Mobile/i.exec(e),f0=!!/Win64/.exec(e),t){$r=t[1]?parseFloat(t[1]):t[5]?parseFloat(t[5]):NaN,$r&&document&&document.documentMode&&($r=document.documentMode);var o=/(?:Trident\/(\d+.\d+))/.exec(e);p0=o?parseFloat(o[1])+4:$r,Bd=t[2]?parseFloat(t[2]):NaN,jd=t[3]?parseFloat(t[3]):NaN,Hi=t[4]?parseFloat(t[4]):NaN,Hi?(t=/(?:Chrome\/(\d+\.\d+))/.exec(e),qi=t&&t[1]?parseFloat(t[1]):NaN):qi=NaN}else $r=Bd=jd=qi=Hi=NaN;if(n){if(n[1]){var r=/(?:Mac OS X (\d+(?:[._]\d+)?))/.exec(e);Ki=r?parseFloat(r[1].replace("_",".")):!0}else Ki=!1;Hd=!!n[2],qd=!!n[3]}else Ki=Hd=qd=!1}}var Yd={ie:function(){return pn()||$r},ieCompatibilityMode:function(){return pn()||p0>$r},ie64:function(){return Yd.ie()&&f0},firefox:function(){return pn()||Bd},opera:function(){return pn()||jd},webkit:function(){return pn()||Hi},safari:function(){return Yd.webkit()},chrome:function(){return pn()||qi},windows:function(){return pn()||Hd},osx:function(){return pn()||Ki},linux:function(){return pn()||qd},iphone:function(){return pn()||Wd},mobile:function(){return pn()||Wd||Ud||Kd||m0},nativeApp:function(){return pn()||h0},android:function(){return pn()||Kd},ipad:function(){return pn()||Ud}},vP=Yd,Ei=!!(typeof window<"u"&&window.document&&window.document.createElement),yP={canUseDOM:Ei,canUseWorkers:typeof Worker<"u",canUseEventListeners:Ei&&!!(window.addEventListener||window.attachEvent),canUseViewport:Ei&&!!window.screen,isInWorker:!Ei},g0=yP,b0;g0.canUseDOM&&(b0=document.implementation&&document.implementation.hasFeature&&document.implementation.hasFeature("","")!==!0);function _P(e,t){if(!g0.canUseDOM||t&&!("addEventListener"in document))return!1;var n="on"+e,o=n in document;if(!o){var r=document.createElement("div");r.setAttribute(n,"return;"),o=typeof r[n]=="function"}return!o&&b0&&e==="wheel"&&(o=document.implementation.hasFeature("Events.wheel","3.0")),o}var wP=_P,Im=10,Mm=40,Pm=800;function v0(e){var t=0,n=0,o=0,r=0;return"detail"in e&&(n=e.detail),"wheelDelta"in e&&(n=-e.wheelDelta/120),"wheelDeltaY"in e&&(n=-e.wheelDeltaY/120),"wheelDeltaX"in e&&(t=-e.wheelDeltaX/120),"axis"in e&&e.axis===e.HORIZONTAL_AXIS&&(t=n,n=0),o=t*Im,r=n*Im,"deltaY"in e&&(r=e.deltaY),"deltaX"in e&&(o=e.deltaX),(o||r)&&e.deltaMode&&(e.deltaMode==1?(o*=Mm,r*=Mm):(o*=Pm,r*=Pm)),o&&!t&&(t=o<1?-1:1),r&&!n&&(n=r<1?-1:1),{spinX:t,spinY:n,pixelX:o,pixelY:r}}v0.getEventType=function(){return vP.firefox()?"DOMMouseScroll":wP("wheel")?"wheel":"mousewheel"};var xP=v0;/**
+* Checks if an event is supported in the current execution environment.
+*
+* NOTE: This will not work correctly for non-generic events such as `change`,
+* `reset`, `load`, `error`, and `select`.
+*
+* Borrows from Modernizr.
+*
+* @param {string} eventNameSuffix Event name, e.g. "click".
+* @param {?boolean} capture Check if the capture phase is supported.
+* @return {boolean} True if the event is supported.
+* @internal
+* @license Modernizr 3.0.0pre (Custom Build) | MIT
+*/const kP=function(e,t){if(e&&e.addEventListener){const n=function(o){const r=xP(o);t&&Reflect.apply(t,this,[o,r])};cp()?e.addEventListener("DOMMouseScroll",n):e.onmousewheel=n}},TP={beforeMount(e,t){kP(e,t.value)}},CP={beforeMount(e,t){e._handleResize=()=>{var n;e&&((n=t.value)==null||n.call(t,e))},ja(e,e._handleResize)},beforeUnmount(e){Ha(e,e._handleResize)}},Lc=(e,t,n)=>{const o=[],r=t&&n();for(let a=0;ae.map((t,n)=>t||n).filter(t=>t!==!0),y0=(e,t,n)=>({getHoursList:(l,i)=>Lc(24,e,()=>e(l,i)),getMinutesList:(l,i,s)=>Lc(60,t,()=>t(l,i,s)),getSecondsList:(l,i,s,c)=>Lc(60,n,()=>n(l,i,s,c))}),_0=(e,t,n)=>{const{getHoursList:o,getMinutesList:r,getSecondsList:a}=y0(e,t,n);return{getAvailableHours:(c,d)=>Vc(o(c,d)),getAvailableMinutes:(c,d,u)=>Vc(r(c,d,u)),getAvailableSeconds:(c,d,u,p)=>Vc(a(c,d,u,p))}},w0=e=>{const t=E(e.parsedValue);return ge(()=>e.visible,n=>{n||(t.value=e.parsedValue)}),t},SP=ee({directives:{repeatClick:d0},components:{ElScrollbar:qo,ElIcon:qe,ArrowUp:ri,ArrowDown:Gr},props:{role:{type:String,required:!0},spinnerDate:{type:Object,required:!0},showSeconds:{type:Boolean,default:!0},arrowControl:Boolean,amPmMode:{type:String,default:""},disabledHours:{type:Function},disabledMinutes:{type:Function},disabledSeconds:{type:Function}},emits:["change","select-range","set-option"],setup(e,t){const n=ke("time");let o=!1;const r=bn(H=>{o=!1,O(H)},200),a=E(null),l=E(null),i=E(null),s=E(null),c={hours:l,minutes:i,seconds:s},d=C(()=>{const H=["hours","minutes","seconds"];return e.showSeconds?H:H.slice(0,2)}),u=C(()=>e.spinnerDate.hour()),p=C(()=>e.spinnerDate.minute()),f=C(()=>e.spinnerDate.second()),h=C(()=>({hours:u,minutes:p,seconds:f})),b=C(()=>se(e.role)),m=C(()=>Se(u.value,e.role)),g=C(()=>oe(u.value,p.value,e.role)),v=C(()=>({hours:b,minutes:m,seconds:g})),y=C(()=>{const H=u.value;return[H>0?H-1:void 0,H,H<23?H+1:void 0]}),T=C(()=>{const H=p.value;return[H>0?H-1:void 0,H,H<59?H+1:void 0]}),w=C(()=>{const H=f.value;return[H>0?H-1:void 0,H,H<59?H+1:void 0]}),k=C(()=>({hours:y,minutes:T,seconds:w})),$=H=>{if(!!!e.amPmMode)return"";const le=e.amPmMode==="A";let be=H<12?" am":" pm";return le&&(be=be.toUpperCase()),be},z=H=>{H==="hours"?t.emit("select-range",0,2):H==="minutes"?t.emit("select-range",3,5):H==="seconds"&&t.emit("select-range",6,8),a.value=H},O=H=>{L(H,h.value[H].value)},R=()=>{O("hours"),O("minutes"),O("seconds")},F=H=>H.querySelector(`.${n.namespace.value}-scrollbar__wrap`),L=(H,ne)=>{if(e.arrowControl)return;const le=c[H];le&&le.$el&&(F(le.$el).scrollTop=Math.max(0,ne*D(H)))},D=H=>c[H].$el.querySelector("li").offsetHeight,V=()=>{P(1)},q=()=>{P(-1)},P=H=>{a.value||z("hours");const ne=a.value;let le=h.value[ne].value;const be=a.value==="hours"?24:60;le=(le+H+be)%be,A(ne,le),L(ne,le),je(()=>z(a.value))},A=(H,ne)=>{if(!v.value[H].value[ne])switch(H){case"hours":t.emit("change",e.spinnerDate.hour(ne).minute(p.value).second(f.value));break;case"minutes":t.emit("change",e.spinnerDate.hour(u.value).minute(ne).second(f.value));break;case"seconds":t.emit("change",e.spinnerDate.hour(u.value).minute(p.value).second(ne));break}},I=(H,{value:ne,disabled:le})=>{le||(A(H,ne),z(H),L(H,ne))},W=H=>{o=!0,r(H);const ne=Math.min(Math.round((F(c[H].$el).scrollTop-(Y(H)*.5-10)/D(H)+3)/D(H)),H==="hours"?23:59);A(H,ne)},Y=H=>c[H].$el.offsetHeight,J=()=>{const H=ne=>{c[ne]&&c[ne].$el&&(F(c[ne].$el).onscroll=()=>{W(ne)})};H("hours"),H("minutes"),H("seconds")};et(()=>{je(()=>{!e.arrowControl&&J(),R(),e.role==="start"&&z("hours")})});const Z=(H,ne)=>{c[ne]=H};t.emit("set-option",[`${e.role}_scrollDown`,P]),t.emit("set-option",[`${e.role}_emitSelectRange`,z]);const{getHoursList:se,getMinutesList:Se,getSecondsList:oe}=y0(e.disabledHours,e.disabledMinutes,e.disabledSeconds);return ge(()=>e.spinnerDate,()=>{o||R()}),{ns:n,setRef:Z,spinnerItems:d,currentScrollbar:a,hours:u,minutes:p,seconds:f,hoursList:b,minutesList:m,arrowHourList:y,arrowMinuteList:T,arrowSecondList:w,getAmPmFlag:$,emitSelectRange:z,adjustCurrentSpinner:O,typeItemHeight:D,listHoursRef:l,listMinutesRef:i,listSecondsRef:s,onIncreaseClick:V,onDecreaseClick:q,handleClick:I,secondsList:g,timePartsMap:h,arrowListMap:k,listMap:v}}}),$P=["onClick"],EP=["onMouseenter"];function AP(e,t,n,o,r,a){const l=ie("el-scrollbar"),i=ie("arrow-up"),s=ie("el-icon"),c=ie("arrow-down"),d=Nn("repeat-click");return x(),N("div",{class:S([e.ns.b("spinner"),{"has-seconds":e.showSeconds}])},[e.arrowControl?G("v-if",!0):(x(!0),N(De,{key:0},ct(e.spinnerItems,u=>(x(),Q(l,{key:u,ref_for:!0,ref:p=>e.setRef(p,u),class:S(e.ns.be("spinner","wrapper")),"wrap-style":"max-height: inherit;","view-class":e.ns.be("spinner","list"),noresize:"",tag:"ul",onMouseenter:p=>e.emitSelectRange(u),onMousemove:p=>e.adjustCurrentSpinner(u)},{default:K(()=>[(x(!0),N(De,null,ct(e.listMap[u].value,(p,f)=>(x(),N("li",{key:f,class:S([e.ns.be("spinner","item"),e.ns.is("active",f===e.timePartsMap[u].value),e.ns.is("disabled",p)]),onClick:h=>e.handleClick(u,{value:f,disabled:p})},[u==="hours"?(x(),N(De,{key:0},[lt(ve(("0"+(e.amPmMode?f%12||12:f)).slice(-2))+ve(e.getAmPmFlag(f)),1)],2112)):(x(),N(De,{key:1},[lt(ve(("0"+f).slice(-2)),1)],2112))],10,$P))),128))]),_:2},1032,["class","view-class","onMouseenter","onMousemove"]))),128)),e.arrowControl?(x(!0),N(De,{key:1},ct(e.spinnerItems,u=>(x(),N("div",{key:u,class:S([e.ns.be("spinner","wrapper"),e.ns.is("arrow")]),onMouseenter:p=>e.emitSelectRange(u)},[Ue((x(),Q(s,{class:S(["arrow-up",e.ns.be("spinner","arrow")])},{default:K(()=>[U(i)]),_:1},8,["class"])),[[d,e.onDecreaseClick]]),Ue((x(),Q(s,{class:S(["arrow-down",e.ns.be("spinner","arrow")])},{default:K(()=>[U(c)]),_:1},8,["class"])),[[d,e.onIncreaseClick]]),M("ul",{class:S(e.ns.be("spinner","list"))},[(x(!0),N(De,null,ct(e.arrowListMap[u].value,(p,f)=>(x(),N("li",{key:f,class:S([e.ns.be("spinner","item"),e.ns.is("active",p===e.timePartsMap[u].value),e.ns.is("disabled",e.listMap[u].value[p])])},[typeof p=="number"?(x(),N(De,{key:0},[u==="hours"?(x(),N(De,{key:0},[lt(ve(("0"+(e.amPmMode?p%12||12:p)).slice(-2))+ve(e.getAmPmFlag(p)),1)],2112)):(x(),N(De,{key:1},[lt(ve(("0"+p).slice(-2)),1)],2112))],2112)):G("v-if",!0)],2))),128))],2)],42,EP))),128)):G("v-if",!0)],2)}var x0=_e(SP,[["render",AP],["__file","/home/runner/work/element-plus/element-plus/packages/components/time-picker/src/time-picker-com/basic-time-spinner.vue"]]);const zP=ee({components:{TimeSpinner:x0},props:{visible:Boolean,actualVisible:{type:Boolean,default:void 0},datetimeRole:{type:String},parsedValue:{type:[Object,String]},format:{type:String,default:""}},emits:["pick","select-range","set-picker-option"],setup(e,t){const n=ke("time"),{t:o,lang:r}=Tt(),a=E([0,2]),l=w0(e),i=C(()=>Cn(e.actualVisible)?`${n.namespace.value}-zoom-in-top`:""),s=C(()=>e.format.includes("ss")),c=C(()=>e.format.includes("A")?"A":e.format.includes("a")?"a":""),d=P=>{const A=Ge(P).locale(r.value),I=g(A);return A.isSame(I)},u=()=>{t.emit("pick",l.value,!1)},p=(P=!1,A=!1)=>{A||t.emit("pick",e.parsedValue,P)},f=P=>{if(!e.visible)return;const A=g(P).millisecond(0);t.emit("pick",A,!0)},h=(P,A)=>{t.emit("select-range",P,A),a.value=[P,A]},b=P=>{const A=[0,3].concat(s.value?[6]:[]),I=["hours","minutes"].concat(s.value?["seconds"]:[]),Y=(A.indexOf(a.value[0])+P+A.length)%A.length;w.start_emitSelectRange(I[Y])},m=P=>{const A=P.code;if(A===Oe.left||A===Oe.right){const I=A===Oe.left?-1:1;b(I),P.preventDefault();return}if(A===Oe.up||A===Oe.down){const I=A===Oe.up?-1:1;w.start_scrollDown(I),P.preventDefault();return}},g=P=>{const A={hour:D,minute:V,second:q};let I=P;return["hour","minute","second"].forEach(W=>{if(A[W]){let Y;const J=A[W];W==="minute"?Y=J(I.hour(),e.datetimeRole):W==="second"?Y=J(I.hour(),I.minute(),e.datetimeRole):Y=J(e.datetimeRole),Y&&Y.length&&!Y.includes(I[W]())&&(I=I[W](Y[0]))}}),I},v=P=>P?Ge(P,e.format).locale(r.value):null,y=P=>P?P.format(e.format):null,T=()=>Ge(L).locale(r.value);t.emit("set-picker-option",["isValidValue",d]),t.emit("set-picker-option",["formatToString",y]),t.emit("set-picker-option",["parseUserInput",v]),t.emit("set-picker-option",["handleKeydown",m]),t.emit("set-picker-option",["getRangeAvailableTime",g]),t.emit("set-picker-option",["getDefaultValue",T]);const w={},k=P=>{w[P[0]]=P[1]},$=Ne("EP_PICKER_BASE"),{arrowControl:z,disabledHours:O,disabledMinutes:R,disabledSeconds:F,defaultValue:L}=$.props,{getAvailableHours:D,getAvailableMinutes:V,getAvailableSeconds:q}=_0(O,R,F);return{ns:n,transitionName:i,arrowControl:z,onSetOption:k,t:o,handleConfirm:p,handleChange:f,setSelectionRange:h,amPmMode:c,showSeconds:s,handleCancel:u,disabledHours:O,disabledMinutes:R,disabledSeconds:F}}});function NP(e,t,n,o,r,a){const l=ie("time-spinner");return x(),Q(qt,{name:e.transitionName},{default:K(()=>[e.actualVisible||e.visible?(x(),N("div",{key:0,class:S(e.ns.b("panel"))},[M("div",{class:S([e.ns.be("panel","content"),{"has-seconds":e.showSeconds}])},[U(l,{ref:"spinner",role:e.datetimeRole||"start","arrow-control":e.arrowControl,"show-seconds":e.showSeconds,"am-pm-mode":e.amPmMode,"spinner-date":e.parsedValue,"disabled-hours":e.disabledHours,"disabled-minutes":e.disabledMinutes,"disabled-seconds":e.disabledSeconds,onChange:e.handleChange,onSetOption:e.onSetOption,onSelectRange:e.setSelectionRange},null,8,["role","arrow-control","show-seconds","am-pm-mode","spinner-date","disabled-hours","disabled-minutes","disabled-seconds","onChange","onSetOption","onSelectRange"])],2),M("div",{class:S(e.ns.be("panel","footer"))},[M("button",{type:"button",class:S([e.ns.be("panel","btn"),"cancel"]),onClick:t[0]||(t[0]=(...i)=>e.handleCancel&&e.handleCancel(...i))},ve(e.t("el.datepicker.cancel")),3),M("button",{type:"button",class:S([e.ns.be("panel","btn"),"confirm"]),onClick:t[1]||(t[1]=i=>e.handleConfirm())},ve(e.t("el.datepicker.confirm")),3)],2)],2)):G("v-if",!0)]),_:1},8,["name"])}var $p=_e(zP,[["render",NP],["__file","/home/runner/work/element-plus/element-plus/packages/components/time-picker/src/time-picker-com/panel-time-pick.vue"]]);const ta=(e,t)=>{const n=[];for(let o=e;o<=t;o++)n.push(o);return n},IP=ee({components:{TimeSpinner:x0},props:{visible:Boolean,actualVisible:Boolean,parsedValue:{type:[Array]},format:{type:String,default:""}},emits:["pick","select-range","set-picker-option"],setup(e,t){const{t:n,lang:o}=Tt(),r=ke("time"),a=ke("picker"),l=C(()=>e.parsedValue[0]),i=C(()=>e.parsedValue[1]),s=w0(e),c=()=>{t.emit("pick",s.value,!1)},d=C(()=>e.format.includes("ss")),u=C(()=>e.format.includes("A")?"A":e.format.includes("a")?"a":""),p=E([]),f=E([]),h=(be=!1)=>{t.emit("pick",[l.value,i.value],be)},b=be=>{v(be.millisecond(0),i.value)},m=be=>{v(l.value,be.millisecond(0))},g=be=>{const $e=be.map(Me=>Ge(Me).locale(o.value)),Ie=D($e);return $e[0].isSame(Ie[0])&&$e[1].isSame(Ie[1])},v=(be,$e)=>{t.emit("pick",[be,$e],!0)},y=C(()=>l.value>i.value),T=E([0,2]),w=(be,$e)=>{t.emit("select-range",be,$e,"min"),T.value=[be,$e]},k=C(()=>d.value?11:8),$=(be,$e)=>{t.emit("select-range",be,$e,"max"),T.value=[be+k.value,$e+k.value]},z=be=>{const $e=d.value?[0,3,6,11,14,17]:[0,3,8,11],Ie=["hours","minutes"].concat(d.value?["seconds"]:[]),j=($e.indexOf(T.value[0])+be+$e.length)%$e.length,X=$e.length/2;j
+
+
+
+ This scatter operation would look like this:
+
+ >>> tensor = [0, 0, 0, 0, 0, 0, 0, 0] # tf.rank(tensor) == 1
+ >>> indices = [[1], [3], [4], [7]] # num_updates == 4, index_depth == 1
+ >>> updates = [9, 10, 11, 12] # num_updates == 4
+ >>> print(tf.tensor_scatter_nd_update(tensor, indices, updates))
+ tf.Tensor([ 0 9 0 10 11 0 0 12], shape=(8,), dtype=int32)
+
+ The length (first axis) of \`updates\` must equal the length of the \`indices\`:
+ \`num_updates\`. This is the number of updates being inserted. Each scalar
+ update is inserted into \`tensor\` at the indexed location.
+
+ For a higher rank input \`tensor\` scalar updates can be inserted by using an
+ \`index_depth\` that matches \`tf.rank(tensor)\`:
+
+ >>> tensor = [[1, 1], [1, 1], [1, 1]] # tf.rank(tensor) == 2
+ >>> indices = [[0, 1], [2, 0]] # num_updates == 2, index_depth == 2
+ >>> updates = [5, 10] # num_updates == 2
+ >>> print(tf.tensor_scatter_nd_update(tensor, indices, updates))
+ tf.Tensor(
+ [[ 1 5]
+ [ 1 1]
+ [10 1]], shape=(3, 2), dtype=int32)
+
+ ### Slice updates
+
+ When the input \`tensor\` has more than one axis scatter can be used to update
+ entire slices.
+
+ In this case it's helpful to think of the input \`tensor\` as being a two level
+ array-of-arrays. The shape of this two level array is split into the
+ \`outer_shape\` and the \`inner_shape\`.
+
+ \`indices\` indexes into the outer level of the input tensor (\`outer_shape\`).
+ and replaces the sub-array at that location with the corresponding item from
+ the \`updates\` list. The shape of each update is \`inner_shape\`.
+
+ When updating a list of slices the shape constraints are:
+
+ \`\`\`
+ num_updates, index_depth = indices.shape.as_list()
+ inner_shape = tensor.shape[:index_depth]
+ outer_shape = tensor.shape[index_depth:]
+ assert updates.shape == [num_updates, inner_shape]
+ \`\`\`
+
+ For example, to update rows of a \`(6, 3)\` \`tensor\`:
+
+ >>> tensor = tf.zeros([6, 3], dtype=tf.int32)
+
+ Use an index depth of one.
+
+ >>> indices = tf.constant([[2], [4]]) # num_updates == 2, index_depth == 1
+ >>> num_updates, index_depth = indices.shape.as_list()
+
+ The \`outer_shape\` is \`6\`, the inner shape is \`3\`:
+
+ >>> outer_shape = tensor.shape[:index_depth]
+ >>> inner_shape = tensor.shape[index_depth:]
+
+ 2 rows are being indexed so 2 \`updates\` must be supplied.
+ Each update must be shaped to match the \`inner_shape\`.
+
+ >>> # num_updates == 2, inner_shape==3
+ >>> updates = tf.constant([[1, 2, 3],
+ ... [4, 5, 6]])
+
+ Altogether this gives:
+
+ >>> tf.tensor_scatter_nd_update(tensor, indices, updates).numpy()
+ array([[0, 0, 0],
+ [0, 0, 0],
+ [1, 2, 3],
+ [0, 0, 0],
+ [4, 5, 6],
+ [0, 0, 0]], dtype=int32)
+
+ #### More slice update examples
+
+ A tensor representing a batch of uniformly sized video clips naturally has 5
+ axes: \`[batch_size, time, width, height, channels]\`.
+
+ For example:
+
+ >>> batch_size, time, width, height, channels = 13,11,7,5,3
+ >>> video_batch = tf.zeros([batch_size, time, width, height, channels])
+
+ To replace a selection of video clips:
+ * Use an \`index_depth\` of 1 (indexing the \`outer_shape\`: \`[batch_size]\`)
+ * Provide updates each with a shape matching the \`inner_shape\`:
+ \`[time, width, height, channels]\`.
+
+ To replace the first two clips with ones:
+
+ >>> indices = [[0],[1]]
+ >>> new_clips = tf.ones([2, time, width, height, channels])
+ >>> tf.tensor_scatter_nd_update(video_batch, indices, new_clips)
+
+ To replace a selection of frames in the videos:
+
+ * \`indices\` must have an \`index_depth\` of 2 for the \`outer_shape\`:
+ \`[batch_size, time]\`.
+ * \`updates\` must be shaped like a list of images. Each update must have a
+ shape, matching the \`inner_shape\`: \`[width, height, channels]\`.
+
+ To replace the first frame of the first three video clips:
+
+ >>> indices = [[0, 0], [1, 0], [2, 0]] # num_updates=3, index_depth=2
+ >>> new_images = tf.ones([
+ ... # num_updates=3, inner_shape=(width, height, channels)
+ ... 3, width, height, channels])
+ >>> tf.tensor_scatter_nd_update(video_batch, indices, new_images)
+
+ ### Folded indices
+
+ In simple cases it's convenient to think of \`indices\` and \`updates\` as
+ lists, but this is not a strict requirement. Instead of a flat \`num_updates\`,
+ the \`indices\` and \`updates\` can be folded into a \`batch_shape\`. This
+ \`batch_shape\` is all axes of the \`indices\`, except for the innermost
+ \`index_depth\` axis.
+
+ \`\`\`
+ index_depth = indices.shape[-1]
+ batch_shape = indices.shape[:-1]
+ \`\`\`
+
+ Note: The one exception is that the \`batch_shape\` cannot be \`[]\`. You can't
+ update a single index by passing indices with shape \`[index_depth]\`.
+
+ \`updates\` must have a matching \`batch_shape\` (the axes before \`inner_shape\`).
+
+ \`\`\`
+ assert updates.shape == batch_shape + inner_shape
+ \`\`\`
+
+ Note: The result is equivalent to flattening the \`batch_shape\` axes of
+ \`indices\` and \`updates\`. This generalization just avoids the need
+ for reshapes when it is more natural to construct "folded" indices and
+ updates.
+
+ With this generalization the full shape constraints are:
+
+ \`\`\`
+ assert tf.rank(indices) >= 2
+ index_depth = indices.shape[-1]
+ batch_shape = indices.shape[:-1]
+ assert index_depth <= tf.rank(tensor)
+ outer_shape = tensor.shape[:index_depth]
+ inner_shape = tensor.shape[index_depth:]
+ assert updates.shape == batch_shape + inner_shape
+ \`\`\`
+
+ For example, to draw an \`X\` on a \`(5,5)\` matrix start with these indices:
+
+ >>> tensor = tf.zeros([5,5])
+ >>> indices = tf.constant([
+ ... [[0,0],
+ ... [1,1],
+ ... [2,2],
+ ... [3,3],
+ ... [4,4]],
+ ... [[0,4],
+ ... [1,3],
+ ... [2,2],
+ ... [3,1],
+ ... [4,0]],
+ ... ])
+ >>> indices.shape.as_list() # batch_shape == [2, 5], index_depth == 2
+ [2, 5, 2]
+
+ Here the \`indices\` do not have a shape of \`[num_updates, index_depth]\`, but a
+ shape of \`batch_shape+[index_depth]\`.
+
+ Since the \`index_depth\` is equal to the rank of \`tensor\`:
+
+ * \`outer_shape\` is \`(5,5)\`
+ * \`inner_shape\` is \`()\` - each update is scalar
+ * \`updates.shape\` is \`batch_shape + inner_shape == (5,2) + ()\`
+
+ >>> updates = [
+ ... [1,1,1,1,1],
+ ... [1,1,1,1,1],
+ ... ]
+
+ Putting this together gives:
+
+ >>> tf.tensor_scatter_nd_update(tensor, indices, updates).numpy()
+ array([[1., 0., 0., 0., 1.],
+ [0., 1., 0., 1., 0.],
+ [0., 0., 1., 0., 0.],
+ [0., 1., 0., 1., 0.],
+ [1., 0., 0., 0., 1.]], dtype=float32)
+
+ Args:
+ tensor: Tensor to copy/update.
+ indices: Indices to update.
+ updates: Updates to apply at the indices.
+ name: Optional name for the operation.
+
+ Returns:
+ A new tensor with the given shape and updates applied according to the
+ indices.
+ `],["tf.test","description: Testing.",!0,`Testing.
+`],["tf.tile","description: Constructs a tensor by tiling a given tensor.",!1,`Constructs a tensor by tiling a given tensor.
+
+ This operation creates a new tensor by replicating \`input\` \`multiples\` times.
+ The output tensor's i'th dimension has \`input.dims(i) * multiples[i]\` elements,
+ and the values of \`input\` are replicated \`multiples[i]\` times along the 'i'th
+ dimension. For example, tiling \`[a b c d]\` by \`[2]\` produces
+ \`[a b c d a b c d]\`.
+
+ >>> a = tf.constant([[1,2,3],[4,5,6]], tf.int32)
+ >>> b = tf.constant([1,2], tf.int32)
+ >>> tf.tile(a, b)
+
+ tf.TypeSpec that represents the given value.',!1,`Returns a \`tf.TypeSpec\` that represents the given \`value\`.
+
+ Examples:
+
+ >>> tf.type_spec_from_value(tf.constant([1, 2, 3]))
+ TensorSpec(shape=(3,), dtype=tf.int32, name=None)
+ >>> tf.type_spec_from_value(np.array([4.0, 5.0], np.float64))
+ TensorSpec(shape=(2,), dtype=tf.float64, name=None)
+ >>> tf.type_spec_from_value(tf.ragged.constant([[1, 2], [3, 4, 5]]))
+ RaggedTensorSpec(TensorShape([2, None]), tf.int32, 1, tf.int64)
+
+ >>> example_input = tf.ragged.constant([[1, 2], [3]])
+ >>> @tf.function(input_signature=[tf.type_spec_from_value(example_input)])
+ ... def f(x):
+ ... return tf.reduce_sum(x, axis=1)
+
+ Args:
+ value: A value that can be accepted or returned by TensorFlow APIs. Accepted
+ types for \`value\` include \`tf.Tensor\`, any value that can be converted to
+ \`tf.Tensor\` using \`tf.convert_to_tensor\`, and any subclass of
+ \`CompositeTensor\` (such as \`tf.RaggedTensor\`).
+
+ Returns:
+ A \`TypeSpec\` that is compatible with \`value\`.
+
+ Raises:
+ TypeError: If a TypeSpec cannot be built for \`value\`, because its type
+ is not supported.
+ `],["tf.UnconnectedGradients","description: Controls how gradient computation behaves when y does not depend on x.",!1,`Controls how gradient computation behaves when y does not depend on x.
+
+ The gradient of y with respect to x can be zero in two different ways: there
+ could be no differentiable path in the graph connecting x to y (and so we can
+ statically prove that the gradient is zero) or it could be that runtime values
+ of tensors in a particular execution lead to a gradient of zero (say, if a
+ relu unit happens to not be activated). To allow you to distinguish between
+ these two cases you can choose what value gets returned for the gradient when
+ there is no path in the graph from x to y:
+
+ * \`NONE\`: Indicates that [None] will be returned if there is no path from x
+ to y
+ * \`ZERO\`: Indicates that a zero tensor will be returned in the shape of x.
+ `],["tf.unique","description: Finds unique elements in a 1-D tensor.",!1,"Finds unique elements in a 1-D tensor.\n\n This operation returns a tensor `y` containing all of the unique elements of `x`\n sorted in the same order that they occur in `x`; `x` does not need to be sorted.\n This operation also returns a tensor `idx` the same size as `x` that contains\n the index of each value of `x` in the unique output `y`. In other words:\n\n `y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`\n\n Examples:\n\n ```\n # tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8]\n y, idx = unique(x)\n y ==> [1, 2, 4, 7, 8]\n idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]\n ```\n\n ```\n # tensor 'x' is [4, 5, 1, 2, 3, 3, 4, 5]\n y, idx = unique(x)\n y ==> [4, 5, 1, 2, 3]\n idx ==> [0, 1, 2, 3, 4, 4, 0, 1]\n ```\n\n Args:\n x: A `Tensor`. 1-D.\n out_idx: An optional `tf.DType` from: `tf.int32, tf.int64`. Defaults to `tf.int32`.\n name: A name for the operation (optional).\n\n Returns:\n A tuple of `Tensor` objects (y, idx).\n\n y: A `Tensor`. Has the same type as `x`.\n idx: A `Tensor` of type `out_idx`.\n "],["tf.unique_with_counts","description: Finds unique elements in a 1-D tensor.",!1,"Finds unique elements in a 1-D tensor.\n\n This operation returns a tensor `y` containing all of the unique elements of `x`\n sorted in the same order that they occur in `x`. This operation also returns a\n tensor `idx` the same size as `x` that contains the index of each value of `x`\n in the unique output `y`. Finally, it returns a third tensor `count` that\n contains the count of each element of `y` in `x`. In other words:\n\n `y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`\n\n For example:\n\n ```\n # tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8]\n y, idx, count = unique_with_counts(x)\n y ==> [1, 2, 4, 7, 8]\n idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]\n count ==> [2, 1, 3, 1, 2]\n ```\n\n Args:\n x: A `Tensor`. 1-D.\n out_idx: An optional `tf.DType` from: `tf.int32, tf.int64`. Defaults to `tf.int32`.\n name: A name for the operation (optional).\n\n Returns:\n A tuple of `Tensor` objects (y, idx, count).\n\n y: A `Tensor`. Has the same type as `x`.\n idx: A `Tensor` of type `out_idx`.\n count: A `Tensor` of type `out_idx`.\n "],["tf.unravel_index","description: Converts an array of flat indices into a tuple of coordinate arrays.",!1,`Converts an array of flat indices into a tuple of coordinate arrays.
+
+
+ Example:
+
+ \`\`\`
+ y = tf.unravel_index(indices=[2, 5, 7], dims=[3, 3])
+ # 'dims' represent a hypothetical (3, 3) tensor of indices:
+ # [[0, 1, *2*],
+ # [3, 4, *5*],
+ # [6, *7*, 8]]
+ # For each entry from 'indices', this operation returns
+ # its coordinates (marked with '*'), such as
+ # 2 ==> (0, 2)
+ # 5 ==> (1, 2)
+ # 7 ==> (2, 1)
+ y ==> [[0, 1, 2], [2, 2, 1]]
+ \`\`\`
+
+ @compatibility(numpy)
+ Equivalent to np.unravel_index
+ @end_compatibility
+
+ Args:
+ indices: A \`Tensor\`. Must be one of the following types: \`int32\`, \`int64\`.
+ An 0-D or 1-D \`int\` Tensor whose elements are indices into the
+ flattened version of an array of dimensions dims.
+ dims: A \`Tensor\`. Must have the same type as \`indices\`.
+ An 1-D \`int\` Tensor. The shape of the array to use for unraveling
+ indices.
+ name: A name for the operation (optional).
+
+ Returns:
+ A \`Tensor\`. Has the same type as \`indices\`.
+ `],["tf.unstack","description: Unpacks the given dimension of a rank-R tensor into rank-(R-1) tensors.",!1,`Unpacks the given dimension of a rank-\`R\` tensor into rank-\`(R-1)\` tensors.
+
+ Unpacks tensors from \`value\` by chipping it along the \`axis\` dimension.
+
+ >>> x = tf.reshape(tf.range(12), (3,4))
+ >>>
+ >>> p, q, r = tf.unstack(x)
+ >>> p.shape.as_list()
+ [4]
+
+ >>> i, j, k, l = tf.unstack(x, axis=1)
+ >>> i.shape.as_list()
+ [3]
+
+ This is the opposite of stack.
+
+ >>> x = tf.stack([i, j, k, l], axis=1)
+
+ More generally if you have a tensor of shape \`(A, B, C, D)\`:
+
+ >>> A, B, C, D = [2, 3, 4, 5]
+ >>> t = tf.random.normal(shape=[A, B, C, D])
+
+ The number of tensor returned is equal to the length of the target \`axis\`:
+
+ >>> axis = 2
+ >>> items = tf.unstack(t, axis=axis)
+ >>> len(items) == t.shape[axis]
+ True
+
+ The shape of each result tensor is equal to the shape of the input tensor,
+ with the target \`axis\` removed.
+
+ >>> items[0].shape.as_list() # [A, B, D]
+ [2, 3, 5]
+
+ The value of each tensor \`items[i]\` is equal to the slice of \`input\` across
+ \`axis\` at index \`i\`:
+
+ >>> for i in range(len(items)):
+ ... slice = t[:,:,i,:]
+ ... assert tf.reduce_all(slice == items[i])
+
+ #### Python iterable unpacking
+
+ With eager execution you _can_ unstack the 0th axis of a tensor using python's
+ iterable unpacking:
+
+ >>> t = tf.constant([1,2,3])
+ >>> a,b,c = t
+
+ \`unstack\` is still necessary because Iterable unpacking doesn't work in
+ a \`@tf.function\`: Symbolic tensors are not iterable.
+
+ You need to use \`tf.unstack\` here:
+
+ >>> @tf.function
+ ... def bad(t):
+ ... a,b,c = t
+ ... return a
+ >>>
+ >>> bad(t)
+ Traceback (most recent call last):
+ ...
+ OperatorNotAllowedInGraphError: ...
+
+ >>> @tf.function
+ ... def good(t):
+ ... a,b,c = tf.unstack(t)
+ ... return a
+ >>>
+ >>> good(t).numpy()
+ 1
+
+ #### Unknown shapes
+
+ Eager tensors have concrete values, so their shape is always known.
+ Inside a \`tf.function\` the symbolic tensors may have unknown shapes.
+ If the length of \`axis\` is unknown \`tf.unstack\` will fail because it cannot
+ handle an unknown number of tensors:
+
+ >>> @tf.function(input_signature=[tf.TensorSpec([None], tf.float32)])
+ ... def bad(t):
+ ... tensors = tf.unstack(t)
+ ... return tensors[0]
+ >>>
+ >>> bad(tf.constant([1,2,3]))
+ Traceback (most recent call last):
+ ...
+ ValueError: Cannot infer argument \`num\` from shape (None,)
+
+ If you know the \`axis\` length you can pass it as the \`num\` argument. But this
+ must be a constant value.
+
+ If you actually need a variable number of tensors in a single \`tf.function\`
+ trace, you will need to use exlicit loops and a \`tf.TensorArray\` instead.
+
+ Args:
+ value: A rank \`R > 0\` \`Tensor\` to be unstacked.
+ num: An \`int\`. The length of the dimension \`axis\`. Automatically inferred if
+ \`None\` (the default).
+ axis: An \`int\`. The axis to unstack along. Defaults to the first dimension.
+ Negative values wrap around, so the valid range is \`[-R, R)\`.
+ name: A name for the operation (optional).
+
+ Returns:
+ The list of \`Tensor\` objects unstacked from \`value\`.
+
+ Raises:
+ ValueError: If \`axis\` is out of the range \`[-R, R)\`.
+ ValueError: If \`num\` is unspecified and cannot be inferred.
+ InvalidArgumentError: If \`num\` does not match the shape of \`value\`.
+ `],["tf.Variable","description: See the [variable guide](https://tensorflow.org/guide/variable).",!0,`See the [variable guide](https://tensorflow.org/guide/variable).
+
+ A variable maintains shared, persistent state manipulated by a program.
+
+ The \`Variable()\` constructor requires an initial value for the variable, which
+ can be a \`Tensor\` of any type and shape. This initial value defines the type
+ and shape of the variable. After construction, the type and shape of the
+ variable are fixed. The value can be changed using one of the assign methods.
+
+ >>> v = tf.Variable(1.)
+ >>> v.assign(2.)
+ '+(o?t:Jt(t,!0))+`"+(o?t:Jt(t,!0))+`+${t}+`}html(t){return t}heading(t,n,o,r){if(this.options.headerIds){const a=this.options.headerPrefix+r.slug(o);return`
+`:`
+`}list(t,n,o){const r=n?"ol":"ul",a=n&&o!==1?' start="'+o+'"':"";return"<"+r+a+`> +`+t+" +`}listitem(t){return`
${t}
+`}table(t,n){return n&&(n=`${n}`),`${t}`}br(){return this.options.xhtml?"":"
"}del(t){return`
An error occurred:
"+Jt(o.message+"",!0)+"";throw o}}ht.options=ht.setOptions=function(e){return so(ht.defaults,e),b2(ht.defaults),ht};ht.getDefaults=Zb;ht.defaults=Fa;ht.use=function(...e){const t=so({},...e),n=ht.defaults.extensions||{renderers:{},childTokens:{}};let o;e.forEach(r=>{if(r.extensions&&(o=!0,r.extensions.forEach(a=>{if(!a.name)throw new Error("extension name required");if(a.renderer){const l=n.renderers?n.renderers[a.name]:null;l?n.renderers[a.name]=function(...i){let s=a.renderer.apply(this,i);return s===!1&&(s=l.apply(this,i)),s}:n.renderers[a.name]=a.renderer}if(a.tokenizer){if(!a.level||a.level!=="block"&&a.level!=="inline")throw new Error("extension level must be 'block' or 'inline'");n[a.level]?n[a.level].unshift(a.tokenizer):n[a.level]=[a.tokenizer],a.start&&(a.level==="block"?n.startBlock?n.startBlock.push(a.start):n.startBlock=[a.start]:a.level==="inline"&&(n.startInline?n.startInline.push(a.start):n.startInline=[a.start]))}a.childTokens&&(n.childTokens[a.name]=a.childTokens)})),r.renderer){const a=ht.defaults.renderer||new Lu;for(const l in r.renderer){const i=a[l];a[l]=(...s)=>{let c=r.renderer[l].apply(a,s);return c===!1&&(c=i.apply(a,s)),c}}t.renderer=a}if(r.tokenizer){const a=ht.defaults.tokenizer||new Fu;for(const l in r.tokenizer){const i=a[l];a[l]=(...s)=>{let c=r.tokenizer[l].apply(a,s);return c===!1&&(c=i.apply(a,s)),c}}t.tokenizer=a}if(r.walkTokens){const a=ht.defaults.walkTokens;t.walkTokens=function(l){r.walkTokens.call(this,l),a&&a.call(this,l)}}o&&(t.extensions=n),ht.setOptions(t)})};ht.walkTokens=function(e,t){for(const n of e)switch(t.call(ht,n),n.type){case"table":{for(const o of n.header)ht.walkTokens(o.tokens,t);for(const o of n.rows)for(const r of o)ht.walkTokens(r.tokens,t);break}case"list":{ht.walkTokens(n.items,t);break}default:ht.defaults.extensions&&ht.defaults.extensions.childTokens&&ht.defaults.extensions.childTokens[n.type]?ht.defaults.extensions.childTokens[n.type].forEach(function(o){ht.walkTokens(n[o],t)}):n.tokens&&ht.walkTokens(n.tokens,t)}};ht.parseInline=function(e,t){if(typeof e=="undefined"||e===null)throw new Error("marked.parseInline(): input parameter is undefined or null");if(typeof e!="string")throw new Error("marked.parseInline(): input parameter is of type "+Object.prototype.toString.call(e)+", string expected");t=so({},ht.defaults,t||{}),Qb(t);try{const n=Mo.lexInline(e,t);return t.walkTokens&&ht.walkTokens(n,t.walkTokens),Po.parseInline(n,t)}catch(n){if(n.message+=` +Please report this to https://github.com/markedjs/marked.`,t.silent)return"
An error occurred:
"+Jt(n.message+"",!0)+"";throw n}};ht.Parser=Po;ht.parser=Po.parse;ht.Renderer=Lu;ht.TextRenderer=ev;ht.Lexer=Mo;ht.lexer=Mo.lex;ht.Tokenizer=Fu;ht.Slugger=tv;ht.parse=ht;Po.parse;Mo.lex;var nv=(e,t)=>{const n=e.__vccOpts||e;for(const[o,r]of t)n[o]=r;return n},P2=Object.defineProperty,O2=Object.getOwnPropertyDescriptor,R2=(e,t,n,o)=>{for(var r=o>1?void 0:o?O2(t,n):t,a=e.length-1,l;a>=0;a--)(l=e[a])&&(r=(o?l(t,n,r):l(r))||r);return o&&r&&P2(t,n,r),r};let wd=class extends Du{mounted(){XG(".api").accordion({collapsible:!0,header:".header",heightStyle:"content",active:!1})}encodeHtml(e){return e?ht(e):""}get apis(){return g2.filter(e=>e[2])}};wd=R2([Xb({components:{}})],wd);const D2=wd,ov=e=>(db("data-v-3527d162"),e=e(),ub(),e),F2={id:"Home"},L2=ov(()=>M("h2",null,"Modules",-1)),V2={class:"header clickable"},B2={class:"name"},j2=["innerHTML"],H2={class:"content"},q2=["innerHTML"],K2=ov(()=>M("h2",null,"Classes",-1));function W2(e,t,n,o,r,a){return x(),N("div",F2,[L2,(x(!0),N(De,null,ct(e.apis,l=>(x(),N("div",{class:"api",key:l[0].toString()},[M("div",V2,[M("span",B2,ve(l[0]),1),M("span",{class:"desc",innerHTML:l[1]},null,8,j2)]),M("div",H2,[M("div",{class:"md-docstring",innerHTML:e.encodeHtml(l[3])},null,8,q2)])]))),128)),K2])}var U2=nv(D2,[["render",W2],["__scopeId","data-v-3527d162"]]),Y2=Object.defineProperty,G2=Object.getOwnPropertyDescriptor,X2=(e,t,n,o)=>{for(var r=o>1?void 0:o?G2(t,n):t,a=e.length-1,l;a>=0;a--)(l=e[a])&&(r=(o?l(t,n,r):l(r))||r);return o&&r&&Y2(t,n,r),r};let xd=class extends Du{};xd=X2([Xb({components:{}})],xd);const Z2=xd,J2=e=>(db("data-v-bdbb760e"),e=e(),ub(),e),Q2={id:"About"},e3=lt(" This is HyDEV's Template "),t3=J2(()=>M("div",null,"for Vue 3 + Typescript + Vite + Vue Router + SASS + Element Plus + Class Components",-1)),n3=[e3,t3];function o3(e,t,n,o,r,a){return x(),N("div",Q2,n3)}var r3=nv(Z2,[["render",o3],["__scopeId","data-v-bdbb760e"]]);/*! + * vue-router v4.0.15 + * (c) 2022 Eduardo San Martin Morote + * @license MIT + */const rv=typeof Symbol=="function"&&typeof Symbol.toStringTag=="symbol",La=e=>rv?Symbol(e):"_vr_"+e,a3=La("rvlm"),Gf=La("rvd"),Vu=La("r"),av=La("rl"),kd=La("rvl"),ia=typeof window!="undefined";function l3(e){return e.__esModule||rv&&e[Symbol.toStringTag]==="Module"}const Nt=Object.assign;function Tc(e,t){const n={};for(const o in t){const r=t[o];n[o]=Array.isArray(r)?r.map(e):e(r)}return n}const ml=()=>{},i3=/\/$/,s3=e=>e.replace(i3,"");function Cc(e,t,n="/"){let o,r={},a="",l="";const i=t.indexOf("?"),s=t.indexOf("#",i>-1?i:0);return i>-1&&(o=t.slice(0,i),a=t.slice(i+1,s>-1?s:t.length),r=e(a)),s>-1&&(o=o||t.slice(0,s),l=t.slice(s,t.length)),o=p3(o!=null?o:t,n),{fullPath:o+(a&&"?")+a+l,path:o,query:r,hash:l}}function c3(e,t){const n=t.query?e(t.query):"";return t.path+(n&&"?")+n+(t.hash||"")}function Xf(e,t){return!t||!e.toLowerCase().startsWith(t.toLowerCase())?e:e.slice(t.length)||"/"}function d3(e,t,n){const o=t.matched.length-1,r=n.matched.length-1;return o>-1&&o===r&&xa(t.matched[o],n.matched[r])&&lv(t.params,n.params)&&e(t.query)===e(n.query)&&t.hash===n.hash}function xa(e,t){return(e.aliasOf||e)===(t.aliasOf||t)}function lv(e,t){if(Object.keys(e).length!==Object.keys(t).length)return!1;for(const n in e)if(!u3(e[n],t[n]))return!1;return!0}function u3(e,t){return Array.isArray(e)?Zf(e,t):Array.isArray(t)?Zf(t,e):e===t}function Zf(e,t){return Array.isArray(t)?e.length===t.length&&e.every((n,o)=>n===t[o]):e.length===1&&e[0]===t}function p3(e,t){if(e.startsWith("/"))return e;if(!e)return t;const n=t.split("/"),o=e.split("/");let r=n.length-1,a,l;for(a=0;a